
Random Forest는 감독 학습 알고리즘이다. 숲을 만들어 어딘지 모르게 만든다. “숲”은 의사 결정 나무의 앙살블이며 , 대부분 “포장”방법으로 훈련되었다. Bagging 방법의 일반적인 아이디어는 학습 모델의 조합이 전반적인 결과를 증가 시킨다는 것이다. 간단하게 말하자면 , 랜덤 포레스트는 여러 개의 의사 결정 트리를 만들고 병합하여 보다 정확하고 안정적인 예측을 한다 . 무작위적인 숲의 한 가지 큰 이점은 분류 및 회귀 문제 모두에 사용될 수 있다는 것이다. 현재 기계 학습 시스템의 대부분을 형성한다. 랜덤 포레스트는 결정 트리 또는 자루 분류기와 거의 동일한 하이퍼 매개 변수를 가진다. 의사 결정 트리를 분류 분류기와 결합 할 필요가 없으며 Random Forest의 분류 자 클래스를 쉽게..
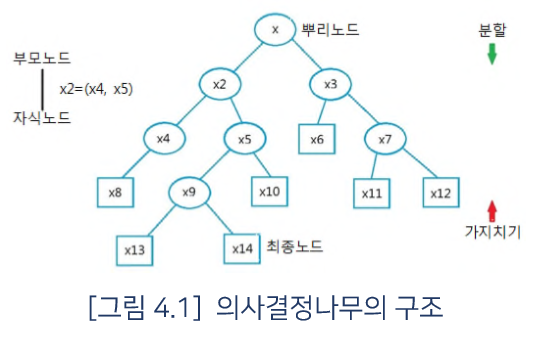
의사결정나무는 무엇이며 , R에서 어떻게 구현할 수 있으며 , 그 의미는 무엇인지 알아 볼 것이다. 의사결정나무(decision tree) 또는 나무 모형(tree model)은 의사결정 규칙을 나무 구조로 나타내어 전체 자료를 몇 개의 소집단으로 분류(classification) 하거나 예측 (prediction)을 수행하는 분석방법이다. 상위 노드로부터 하위노드로 트리구조를 형성하는 매 단계마다 분류변수와 분류 기준값의 선택이 중요하다. 상위노드에서의 (분류변수 , 분류 기준값)은 이 기준에 의해 분기되는 하위노드에서 노드 (집단) 내에서는 동질성이 , 노드(집단)간에는 이질성이 가장 커지도록 선택된다. 나무 모형의 크기는 과대적합(또는 과소적합) 되지 않도록 합리적 기준에 의해 적당히 조절되어야 한..
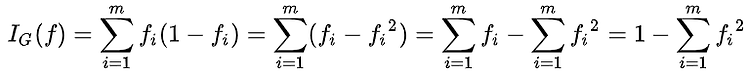
추천 알고리즘을 구현하기 위해서 몇 가지 생각을 해보았다.그 중에 한개에 해당하는 결정 트리 학습법에 대해서 알아 보고자 한다.나의 생각을 정리하기 보다는, 결정 트리 학습법이 무엇인지 알기 위함이 크다. 결정 트리 학습법(decision tree learning)은 어떤 항목에 대한 관측값과 목표값을 연결시켜주는 예측 모델로써 결정 트리를 사용한다.. 트리 모델 중 목표 변수가 유한한 수의 값을 가지는 것을 분류 트리라 한다 . 이 트리 구조에서 잎은 클래스 라벨을 나타내고 가지는 클래스 라벨과 관련있는 특징들의 논리곱을 나타낸다. 결정 트리 중 목표 변수가 연속하는 값, 일반적으로 실수를 가지는 것은 회귀 트리라 한다. 의사 결정 분석에서 결정 트리는 시각적이고 명시적인 방법으로 의사 결정 과정과 결..
앞에서 다룬 사용자의 행동을 분석하고 , 다른 사용자와의 유사성을 기반으로 사용자가 좋아할 것으로 예상되는 사용자 기반 협업 필터링이라는 협업 필터링 방법에 대해 알아 보았다. 그러나 , 이 방법은 다음과 같은 두 가지 주요 문제가 발생한다. 1. 데이터 희박성 : 항목 수가 많으면 사용자가 평가 한 항목 수가 매우 적어 상관 계수의 안정성이 떨어진다.2. 사용자 프로파일이 빠르게 변하고 전체 시스템 모델을 다시 계산해야 하는 데 시간과 계산 비용이 많이 든다 . 이러한 문제를 해결하기 위해 ITEM-ITEM 협업 필터링을 사용한다. ITEM-ITEM 협업 필터링 ITEM-ITEM 협업 필터링은 사용자가 이미 평가 한 기사와 유사한 항목을 찾고 유사한 기사를 가장 많이 추천한다 . 그러나 항목 항목 유사..
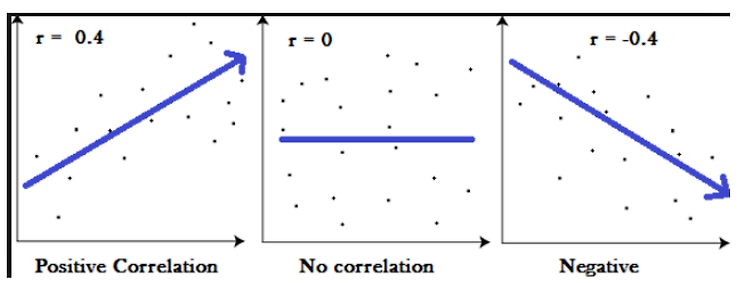
협업필터링 알고리즘 연습3(Collaborative filtering _ algorithm)저번에 사용한 유클리디안 거리공식을 활용한 유사도 측정에는 문제점이 있다. 특정인물의 점수기준이 극단적으로 너무 낮거나 높다면 제대로 된 결과를 도출해낼 수 없는 것이다. 예를 들어 나에게 영화를 평가할 때 일정 기준이 있어 , 기대를 충족하지 못하면 모두 0점을 주고 , 아니면 모두 만점을 주면 전체 데이터를 해치는 결과를 낳는다. 이것을 보완한 것이 Correlation_analysis(상관분석)이다. 상관분석은 두 변수간의 선형적 관계에 대한 분석이다. 쉽게 말해서 점수간 관계에 따라 점을 찍은 후 그 점이 분포한 모양에 따라 상관관계를 도출해내는 것이다 . 아래 그림과 같이 두 변인 x,y에 대해 x가 변화..
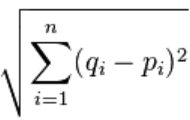
협업필터링 알고리즘 연습2(Collaborative filtering _ algorithm) 피타고라스 공식을 이용한 유사도도출은 2차원, 즉 비교대상이 2개로 한정되는 한계가 있다. 그렇기 때문에 실제 추천 알고리즘을 구현하고자 하는 데이터에서는 사실상 사용될 일이 없다고 할 수 있다. 다차원에서의 거리를 구해 비교대상이 몇 개로 늘어나든 하나의 함수로 비교할 수 있어야 하고 , 그에 따른 유사도를 구할 수 있어야 한다 . 다차원간 거리를 구하는 데 사용되는 공식들은 다음과 같다. 1. Euclidean distance 2. City-block(Manhattan) distance 3. Minkowski distance4. Cosine distance5. Jaccard’s distance 등이 있는데 ,..