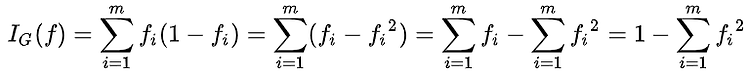

추천 알고리즘을 구현하기 위해서 몇 가지 생각을 해보았다.
그 중에 한개에 해당하는 결정 트리 학습법에 대해서 알아 보고자 한다.
나의 생각을 정리하기 보다는, 결정 트리 학습법이 무엇인지 알기 위함이 크다.
결정 트리 학습법(decision tree learning)은 어떤 항목에 대한 관측값과 목표값을 연결시켜주는 예측 모델로써 결정 트리를 사용한다..
트리 모델 중 목표 변수가 유한한 수의 값을 가지는 것을 분류 트리라 한다 . 이 트리 구조에서 잎은 클래스 라벨을 나타내고 가지는 클래스 라벨과 관련있는 특징들의 논리곱을 나타낸다.
결정 트리 중 목표 변수가 연속하는 값, 일반적으로 실수를 가지는 것은 회귀 트리라 한다.
의사 결정 분석에서 결정 트리는 시각적이고 명시적인 방법으로 의사 결정 과정과 결정된 의사를 보여주는데 사용된다 . 데이터 마이닝 분야에서 결정 트리는 결정된 의사보다는 자료 자체를 표현하는데 사용된다.
다만 , 데이터 마이닝의 결과로서의 분류 트리는 의사 결정 분석의 입력 값으로 사용될 수 있다.
결정 트리 학습법은 데이터 마이닝에서 일반적으로 사용되는 방법론으로 , 몇몇 입력 변수를 바탕으로 목표 변수의 값을 예측하는 모델을 생성하는 것을 목표로 한다.
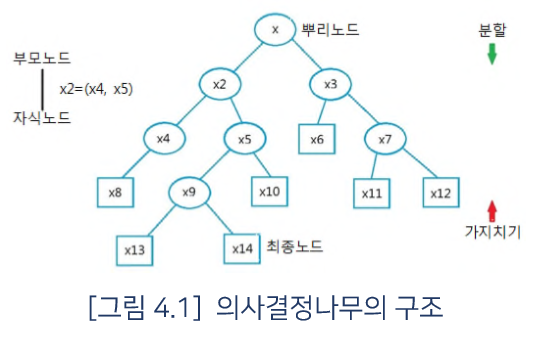
각 내부 노드들은 하나의 입력 변수에 , 자녀 노드들로 이어지는 가지들은 입력 변수의 가능한 값에 대응된다 . 잎 노드는 각 입력 변수들이 루트 노드로부터 잎 노드로 이어지는 경로에 해당되는 값들을 가질 때의 목표 변수 값에 해당된다 .
결정 트리 학습법은 지도 분류 학습에서 가장 유용하게 사용되고 있는 기법 중 하나이다.
여기에서는 모든 속성들이 유한한 이산값들로 구성된 정의역을 가지고 있으며 , 분류를 단일 대상 속성으로 지니고 있다고 간주한다. 분류의 정의역의 각 원소들은 클래스라고 불리며 , 결정 트리 또는 분류 트리의 모든 내부 노드들에는 입력 속성이 일대일로 대응된다. 트리의 내부 노드에 연결된 가지에는 속성이 가질 수 있는 값들이 표시되며 , 잎 노드에는 클래스 또는 클래스의 확률 분포가 표시된다 .
결정 트리의 학습은 학습에 사용되는 자료 집합을 적절한 분할 기준 또는 분할 테스트에 따라 부분 집합들로 나누는 과정이다. 이러한 과정은 순환 분할이라 불리는 방식으로 각각의 나눠진 자료 부분 집합에 재귀적으로 반복되며 , 분할로 인해 더 이상 새로운 예측 값이 추가되지 않거나 부분 집합의 노드가 목표 변수와 같은 값을 지닐 때까지 계속된다. 이러한 하향식 결정 트리 귀납법은 탐욕 알고리즘의 한 예시이다.
데이터로부터 결정 트리를 학습하는 가장 일반적인 방법이다.
데이터 마이닝에서 결정 트리는 주어진 데이터의 일반화와 범주화를 돕기 위해 수학적 표현으로 기술된다.
데이터를 아래와 같이 기술한다고 할 때 ,
(x,Y) = (x1,x2,x3,…,xk,Y)
종속 변수 Y는 분류를 통해 학습하고자 하는 목표 변수이며 , 벡터 x는 x1,x2,x3 등의 입력 변수로 구성된다 .
데이터 마이닝에서 사용되는 결정 트리 분석법은 크게 두 종류가 있다.
1. 분류 트리 분석은 예측된 결과로 입력 데이터가 분류되는 클래스를 출력한다.
2. 회귀 트리 분석은 예측된 결과로 특정 의미를 지니는 실수 값을 출력한다
회귀 트리와 분류 트리는 일정 부분 유사하지만 , 입력 자료를 나누는 과정 등에서 차이점이 있다.
의사 결정 트리 학습은 클래스-라벨 훈련 쌍으로부터의 결정 트리에 의해 구성된다 . 결정 트리의 각각의 노드는 서로 다른 특성을 가진다. 각각의 내부노드는 속성에 대한 테스트를 나타내고 , 각각의 가지는 테스트의 결과를 나타낸다. 그리고 각 리프노드 ( 또는 터미널 노드 )는 클래스의 라벨을 나타낸다 . 트리의 최상위 노드는 루트 노드이다.
결정 트리를 구성하는 알고리즘에는 주로 하향식 기법이 사용되며 , 각 진행 단계에서는 주어진 데이터 집합을 가장 적합한 기준으로 분할하는 변수 값이 선택된다 .
서로 다른 알고리즘들은 분할의 적합성을 측정하는 각자의 기준이 있다.
이러한 기준들은 보통 부분 집합 안에서의 목표 변수의 동질성을 측정하며 , 아래는 그 예시들이다.
이 기준들은 가능한 데이터 집합 분할의 경우의 수마다 적용되며 , 그 결과 값들은 병합되어 , 즉 평균 값이 계산되어 , 데이터 집합의 분할이 얼마나 적합한지 측정하는데 사용된다 .
지니 불순도
è 집합에 이질적인 것이 얼마나 섞였는지를 측정하는 지표이며 , CART 알고리즘에서 사용된다. 어떤 집합에서 한 항목을 뽑아 무작위로 라벨을 추정할 때 틀릴 확률을 말한다.
집합에 있는 항목이 모두 같다면 , 지니 불순도는 최솟값(0)을 갖게 되며 , 이 집합은 완전히 순수하다고 할 수 있다.
항목의 집합에 대한 지니 불순도를 계산하기 위하여 , i E {1,2,…,m} 인 i를 가정해 볼 것이다.
Fi를 i로 표시된 집합 안의 항목의 부분이라고 했을 때 , 아래와 같이 나타낼 수 있다.

정보 획득량
è 정보 획득량은 정보 이론의 엔트로피의 개념에 근거를 두고 있다.

분산 감소
è 노드 N에 대한 분산 감소는 노드의 분할로 인해 발생하는 목표 변수 x의 분산의 총 감소로 정의한다.

다음에는 트리를 통해 결정을 하는 알고리즘을 실질적으로 R에서 어떻게 구현을 하는지 알아 볼 것이며 ,
의사결정나무에 대해서도 알아볼 것이다.
'졸업작품_preparing.... > 알고리즘' 카테고리의 다른 글
| Metacritic이란 무엇인가 (0) | 2019.01.20 |
|---|---|
| Random Forest는 무엇인가 (0) | 2019.01.14 |
| 의사결정나무란 무엇인가 (0) | 2019.01.12 |
| Item-based-Filtering 이란 무엇인가 (0) | 2019.01.03 |
| 추천 시스템이란?? (0) | 2018.12.27 |
#IT #먹방 #전자기기 #일상
#개발 #일상