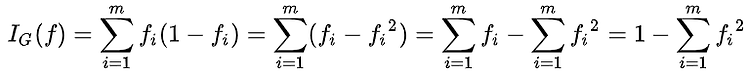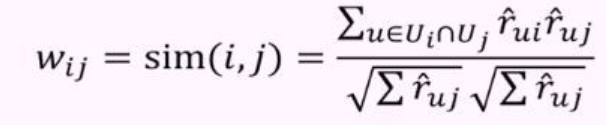Random Forest는 감독 학습 알고리즘이다. 숲을 만들어 어딘지 모르게 만든다.
“숲”은 의사 결정 나무의 앙살블이며 , 대부분 “포장”방법으로 훈련되었다.
Bagging 방법의 일반적인 아이디어는 학습 모델의 조합이 전반적인 결과를 증가 시킨다는 것이다.
간단하게 말하자면 , 랜덤 포레스트는 여러 개의 의사 결정 트리를 만들고 병합하여 보다 정확하고 안정적인 예측을 한다 .
무작위적인 숲의 한 가지 큰 이점은 분류 및 회귀 문제 모두에 사용될 수 있다는 것이다.
현재 기계 학습 시스템의 대부분을 형성한다.
랜덤 포레스트는 결정 트리 또는 자루 분류기와 거의 동일한 하이퍼 매개 변수를 가진다.
의사 결정 트리를 분류 분류기와 결합 할 필요가 없으며 Random Forest의 분류 자 클래스를 쉽게 사용할 수 있다. 이미 말한 것 처럼 Random Forest를 사용하면 Random Forest 회귀 분석기를 사용하여 회귀 작업을 처리 할 수도 있다.
랜덤 포레스트 알고리즘의 또 다른 장점은 예측에서 각 피쳐의 상대적 중요성을 측정하는 것이 매우 쉽다는 것이다 .
Sklearn은 이 기능을 사용하는 트리 노드가 포레스트의 모든 트리에서 불순물을 얼마나 줄일 수 있는지 살펴봄으로써 기능 중요성을 측정하는 훌륭한 도구를 제공한다 .
그것은 훈련 후에 각 특징을 위해 이 점수를 자동으로 계산하고 , 모든 중요도의 합이 1이 되도록 결과를 조정한다.
의사 결정 나무와 임의의 숲 사이의 차이점은 무엇일까 ??
Decision tree Vs Random Forest
기능 및 레이블이 포함 된 교육 데이터 세트를 의사 결정 트리에 입력하면 예측을 수행하는 데 사용할 규칙 집합이 공식화 된다.
Ex )
사용자가 온라인 광고를 클릭할지 여부를 예측하려면 과거에 클릭 한 사람의 광고와 자신의 결정을 설명하는 일부 기능을 수집 할 수 있다.
기능 및 레이블을 의사 결정 트리에 넣으면 몇 가지 규칙이 생성된다. 그러면 광고가 클릭되는지 여부를 예측할 수 있다.
비교해 보면 , Random Forest 알고리즘은 관측치와 특징을 무작위로 선택하여 여러 개의 결정 트리를 만든 다음 결과의 평균을 구한다.
또 다른 차이점은 “심층적인”의사 결정 나무는 과잉으로 인해 어려움을 겪을 수 있다는 것이다.
랜덤 포레스트는 기능의 무작위 부분집합을 생성하고 이러한 부분 집합을 사용하여 더 작은 나무를 작성함으로써 대부분의 시간을 초과 적용 ( overfitting ) 하는 것을 방지한다.
그런 다음 하위 트리를 결합한다. 이것은 매번 작동하지 않으며 무작위 포리스트가 몇 개의 나무를 만드느냐에 따라 계산 속도가 느려진다 .
중요한 하이퍼 매개 변수
임의 포리스트의 Hyperparameters는 모델의 예측 능력을 높이거나 모델을 더 빠르게 만드는 데 사용된다. 여기서 sklearns 내장 된 임의의 포리스트 기능의 하이퍼 패러미터에 대해 이야기 해 본다.
1. 예측력 증가
è “n_estimators” hyperparameter가 있다. 이것은 최대 투표를 하거나 예측의 평균을 취하기 전에 알고리즘이 빌드하는 나무의 수이다. 일반적으로 트리 수가 많을수록 성능이 향상되고 예측이 안정적으로 수행되지만 계산 속도가 느려진다 .
“max_features” : 임의 포리스트가 노드를 분할하는 것으로 간주하는 최대 기능 수 이다 . “min_sample_leaf” : 이것은 이미 이름에서와 같이 내부 노드를 분할하는 데 필요한 최소 리프 수를 결정한다.
2. 모델 속도 높이기
è “n_jobs” hyperparameter 사용할 수 있다. 얼마나 많은 프로세서 엔진을 알려준다. 값이 1이면 하나의 프로세서 만 사용할 수 있다. -1값은 제한이 없음을 의미한다.
“random_state”는 모델의 출력을 복제 가능하게 만든다 . 이 모델은 random_state의 명확한 값을 갖고 동일한 하이퍼 매개 변수와 동일한 교육 데이터가 주어진 경우 항상 동일한 결과를 생성한다 .
“oob_score” : 이는 임의의 포리스트 교차 유효성 검사 방법 , 이 샘플링에서는 약 1/3의 데이터가 모델을 학습하는 데 사용되지 않고 성능을 평가하는 데 사용될 수 있다. 이 샘프을 가방 밖의 샘플이라고 한다 . Leave-one-out 교차 유효성 검사 방법과 매우 유사하지만 추가 계산 부담은 거의 없다 .
장점과 단점
임의의 포리스트의 장점은 회귀 및 분류 작업에 모두 사용할 수 있고 , 입력 기능에 할당 된 상대적인 중요성을 쉽게 볼 수 있다는 것이다.
Random Forest는 기본 하이퍼 매개 변수가 종종 좋은 예측 결과를 생성하기 때문에 매우 편리하고 사용하기 쉬운 알고리즘으로 간주된다 . 하이퍼 파라미터의 수 또한 그다지 높지 않으며 이해하기 쉽다.
기계 학습의 가장 큰 문제 중 하나는 지나치게 적합하지만 대부분의 경우 이는 임의의 포리스트 분류 자에게 쉬운 일은 아니다 . 숲에 나무가 충분하며 분류자가 모델을 과장하지 않기 때문이다.
Random Forest의 주된 한계는 많은 수의 나무가 알고리즘을 실시간 예측을 위해 느려지거나 비 효과적으로 만들 수 있다는 것이다. 일반적으로 이러한 알고리즘은 훈련이 빠르지만 훈련을 받으면 예측을 생성하는 속도가 매우 느리다 . 보다 정확한 예측은 더 많은 트리를 필요로 하므로 느린 모델이 된다. 대부분의 실제 응용 프로그램에서 임의의 포리스트 알고리즘은 충분히 빠르지만 런타임 성능이 중요하고 다른 방법이 선호되는 상황이 있을 수 있다.
Random Forest는 예측 모델링 도구이며 설명 도구는 아니다. 즉 , 데이터에서 관계에 대한 설명을 찾고 있다면 다른 접근 방식이 선호된다 .
'졸업작품_preparing.... > 알고리즘' 카테고리의 다른 글
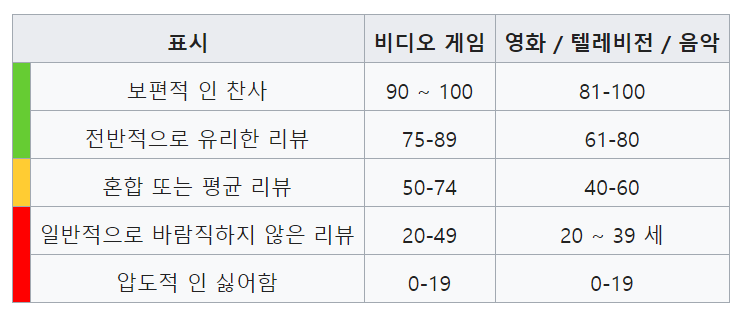
| Metacritic이란 무엇인가 (0) | 2019.01.20 |
|---|---|
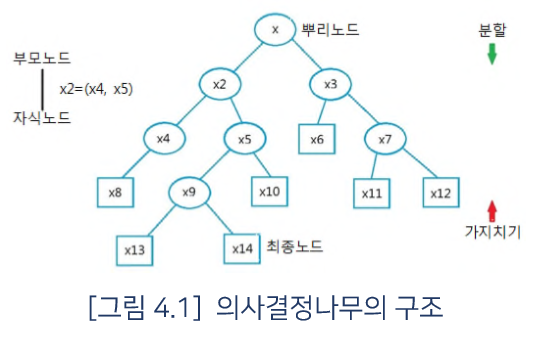
| 의사결정나무란 무엇인가 (0) | 2019.01.12 |
| 결정 트리 학습법이란 무엇인가 (0) | 2019.01.12 |
| Item-based-Filtering 이란 무엇인가 (0) | 2019.01.03 |
| 추천 시스템이란?? (0) | 2018.12.27 |
#IT #먹방 #전자기기 #일상
#개발 #일상