
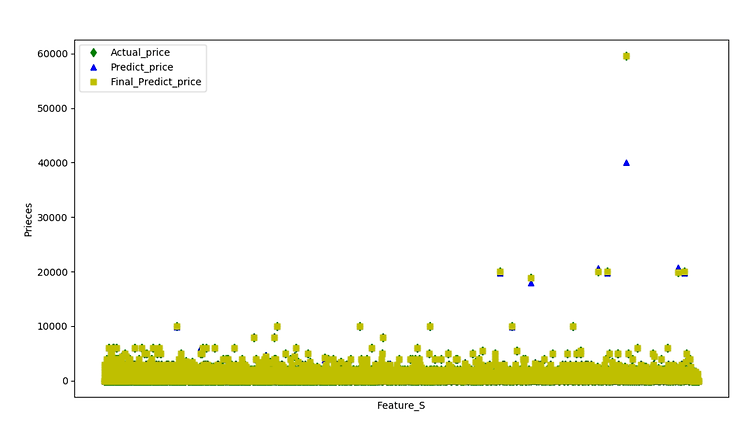
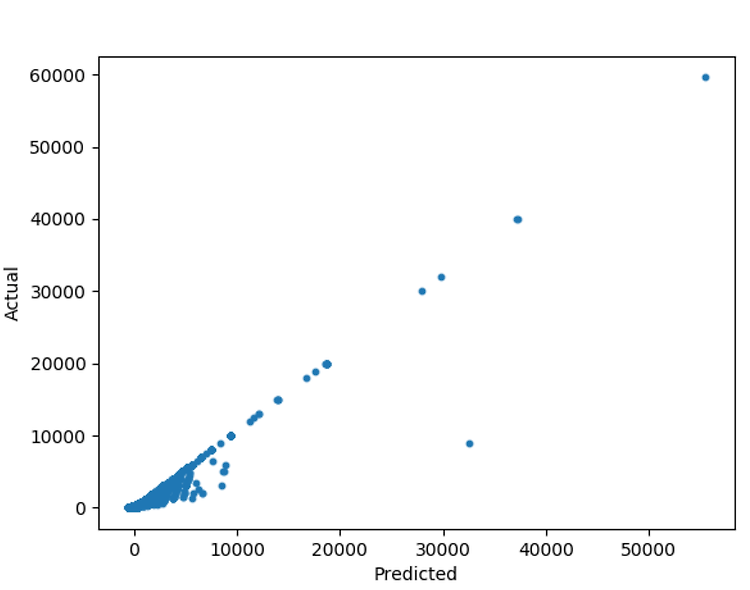
전에 각각의 알고리즘을 적용해서 game_price를 예측했다. 그런데, 알고리즘 적용 후의 예측값과 적용 전의 값의 차이가 존재했고 그 값의 차이를 줄이기 위한 방법은 다음과 같다. # Gradientboosting regressor 알고리즘을 사용해서 가격예측을 해야한다. # 예측되어진 값에서 예측전의 값을 빼면 두 값의 편차가 생긴다. # 이 편차값을 예측되어진 값에서 뺀다면 원래 초기가격에 맞춰지지 않을까 생각을 하였다. # 이 때 두가지 가정이 주어진다 # 적용 전의 값 - 적용 후의 값 : 양수 or 음수 # 양수일 때는 적용전의 값이 클때이며 # 음수일 때는 적용 후의 값이 더 클때이다. # 양수일때와 음수일때의 계산을 다르게 해야할 필요를 느꼈다. 코드를 통해서 확인해 본다. # 예측전의 ..
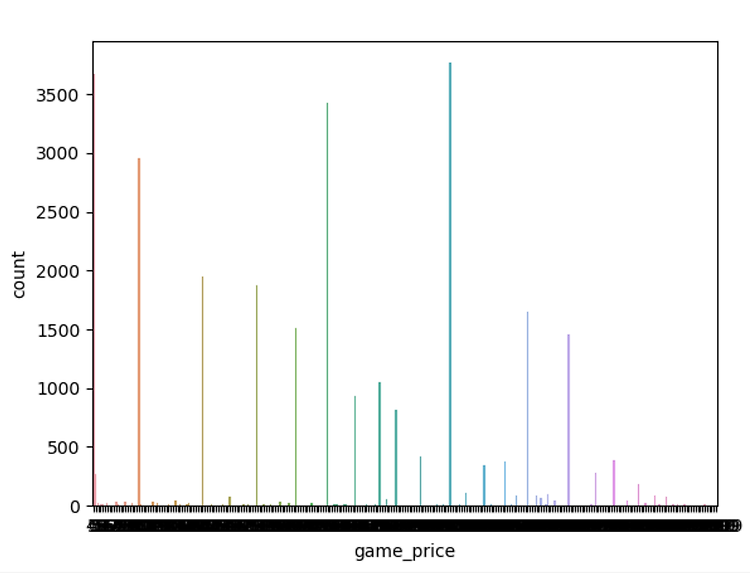
201303017_김인우_빅데이터기술 최종발표 자료 목차 Par1. 1. 데이터셋 설명 2. 데이터 분석 3. 알고리즘 적용 4. 수정된 점 5. 최종결과 Part1 데이터셋 설명 먼저 최종 데이터셋은 다음과 같다. 내가 최종적으로 예측하고자 하는 Y값은 game_price이며, 예측에 필요한 feature들은 다음과 같다. Game_positive(게임의 긍정적인 수), game_negative(게임의 부정적인 수), game_owners(게임 소유자들), game_initialprice(게임 초기가격), game_discount(게임의 할인율) 왜 게임 가격 예측인가? 게임가격은 소비자들의 입장에서 매우 민감한 부분 중 하나이다. 민감한 부분인만큼 어떠한 부분이 게임가격에 영향을 미치는지 궁금했다. ..
코드를 보면서 확인해 보겠다. import pandas as pd import numpy as np import statsmodels.api as sm from sklearn import linear_model from sklearn.linear_model import LinearRegression import matplotlib.pyplot as plt 먼저 필요한 library를 임포트한다. # Excel read pd.set_option('display.max_columns', None) DATA_PATH ="C:/Users/user/Desktop/Data/Data.xlsx" full_dataframe = pd.read_excel(DATA_PATH, sep=',') X = full_dataframe..
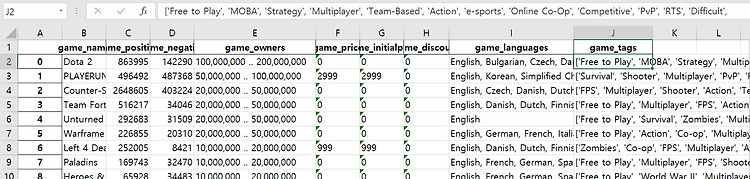
201303017_김인우_빅데이터기술 중간발표자료 목차 1. 데이터셋 설명 2. 데이터 분석 3. 분석 진행도 4. 앞으로 해야 할 작업 데이터셋 설명 è 데이터셋의 head(10)까지만 보면 위와같다. 칼럼들은 다음과 같다. è Game_name(게임이름) game_positive(게임의 긍정적인 평가 점수) game_negative(게임의 부정적인 평가 점수) game_owners(게임 소유한 사람 수) game_price(게임 현재 가격) game_initialprice(게임 초기 가격) game_discount(게임 할인 가격) game_languages(게임이 지원하는 언어) game_tags(게임 태그들) 위 데이터셋은 Steamspiapi를 이용해서 python으로 데이터를 모았으며, Ste..
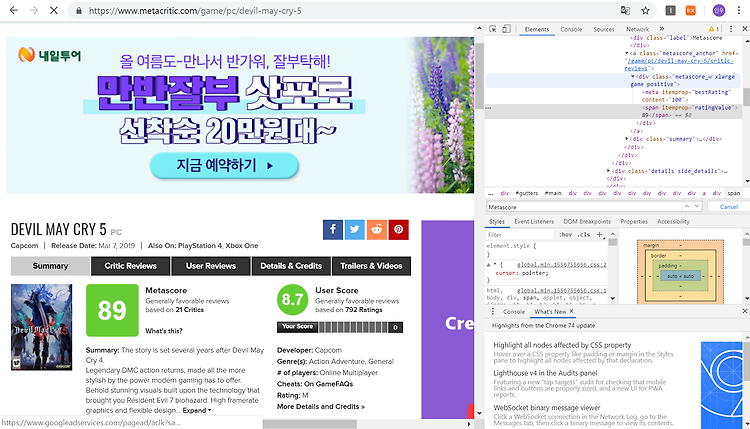
코드를 통해서 설명해 보겠다. import requests from bs4 import BeautifulSoup 일단 필요한 라이브러리는 위와같다. # hrd를 해주는 이유는 웹에서 봇으로 생각을 해서 차단을 해서 hrd ={'User-Agent': 'Mozilla/5.0', 'referer' : 'https://www.metacritic.com/game/pc/devil-may-cry-5'} 봇으로 착각을 해서 header정보를 만들어 주었고 , referer은 크롤링하고자 하는 임시 페이지이다. url = "https://www.metacritic.com/game/pc/devil-may-cry-5" -->요청하고자 하는 주소 req = requests.get(url, headers=hrd) -->req..
Python에서 requests library를 사용해서 크롤링을 할려고 하였다. 그런데 , 제목과 같은 오류가 났다. https://medium.com/@speedforcerun/python-crawler-http-error-403-forbidden-1623ae9ba0f [Python][Crawler]“HTTP Error 403: Forbidden” Using urllib.request.urlopen() to open a website when crawling, and encounters “HTTP Error 403: Forbidden”. It possibly due to the server… medium.com 위를 참고하여서 해결하였다. 문제는 웹에서 봇으로 착각을 하여서 차단한다는 것이다. 그래서..