
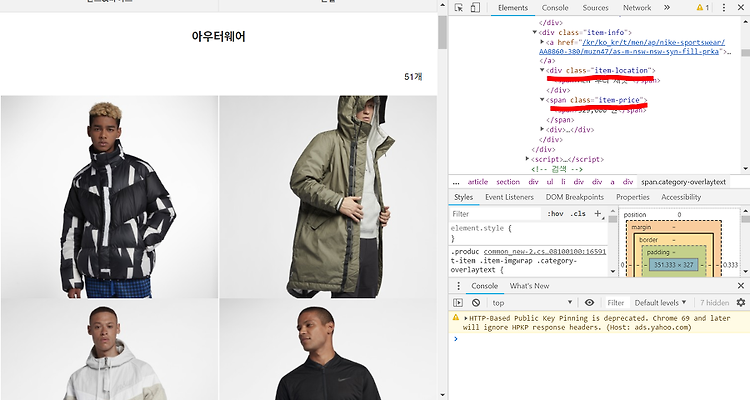
이번에는 나이키(nike) 사이트를 크롤링 해 볼 것이다. 내가 가져올 값들은 아우터 부분의 아우터 이름명과 가격이다. R을 실행해서 , 크롤링에 필요한 , xml과 rvest 패키지를 로딩시켜 준다 . library(rvest)library(XML) url url에 내가 크롤링 하고자 하는 사이트의 url 값을 넣어준다. doc 이 url을 html으로써 읽어 온다 이제 html에 접근하기 위해서 nike 사이트를 접속해 주면 되는데 , Nike 사이트는 다음과 같은 구조를 가졌다. 다음을 보게 되면 아우터의 class 명은 item-location으로 지정되어 있는 것을 확인할 수 있었다. # 옷 이름 가져오기 부분 prod_name % html_nodes(".item-title") %>% html_..
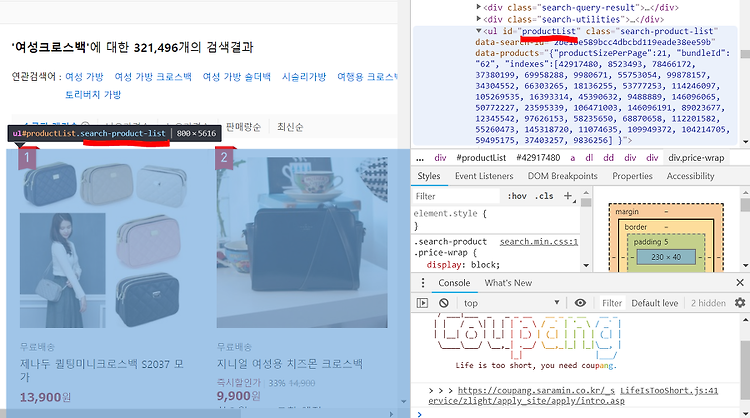
웹 크롤링할 일이 생겨서 하다가 , 안되는 부분이 있어서 적어보고자 한다. 기존 코드이다. XML 라이브러리를 통해서 크롤링에 접근할려고 했다. library(XML) url 먼저 내가 Parsing 하고자 하는 url을 긁어온다. doc 긁어온 url을 html 코드로 변환하며 encoding 방식도 설정해 줄수 있다. prod_name 내가 긁어온 html 코드에 접근을 하고 , ul태그내에 있는 id 값이 productList인것에 1차 접근을 하고 //을 통해서 건너뛴 다음 , div 태그 내에 있는 class 값이 name인 것에 2차 접근을 하는 것이였다. 그런데 여기서 오류가 나는 것이다. Class 가 NULL이라고 한다… 내 뇌피셜이지만 class를 못찾거나 , class명이 잘못된것이라..
웹 스크래핑이란?--> 웹 문서로부터 유용한 정보를 추출하는 기술이다. 예제를 통해서 익혀보자. library(XML)library(RCurl)스크래핑을 하기 위해서는 XML , RCurl 라이브러리가 설치되어 있어야 한다. 첫 번째로는 내가 검색을 할때 , 한국어로 할지 , 또는 영어로 검색을 할지 정해야 한다.영문으로 할때와 한국어로 할때 두가지 경우만 보겠다. query
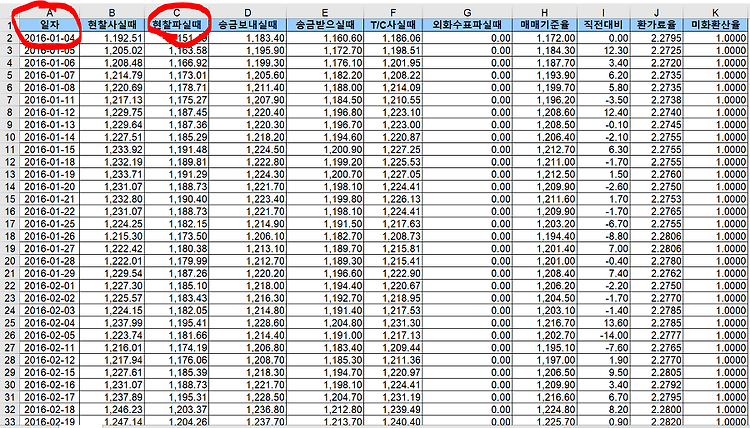
기간환율변동 데이터 분석하기 제가 분석해볼 컬럼 명은 “일자”를 기준으로 , “현찰파실 때” 컬럼의 데이터를 가공하고 분석해서 , plot으로 나타내 볼 것이며 , 예측과 예측값의 정확도를 분석해 볼 것입니다. 그런데 , 분석하기 앞서서 데이터의 예측과 분석이 어떻게 이루어 지는지 , 다음 그림을 통해서 간략화 시킬 수 있습니다. 먼저 , 학습을 통한 예측을 통해 , 실제 데이터를 다루고 , 실제 데이터를 기반으로 학습을 한 데이터를 통해 예측을 합니다 . 예측을 통해서 학습을 하였고 , 이제 데이터 예측을 합니다. 그렇다면 어떻게 예측을 하고 , 학습을 할 수 있을까요? 간단한 플로차트로 나타내 보자면 다음과 같습니다. 1. 데이터 준비 ㄱ. 데이터 파일 읽기 [data 데이터 정규화하기 [Pnorm ..
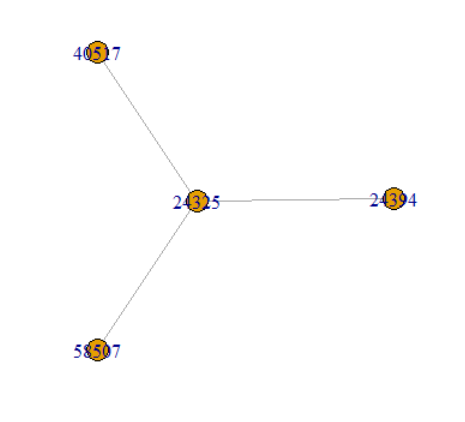
1.파일을 R코드에서 읽어 들인다.sn -->결과물 V1 V21 24325 243942 24325 405173 24325 585074 24394 37375 24394 39056 24394 7237 3.head에서 첫 번째 사용자와 연결된 사용자들의 그래프를 그려 저장한다. [그림 1]sn1 sn1.df plot(sn1.df) # 24325의 값을 기준으로한 데이터프레임을 plot으로 뽑는다 . 4.네트워크 노드의 총수는 몇 명인가? sn.df # 네트워크의 크기: 노드의 총수를 나타나며, # 페이스북 사용자 데이터 세트는 총 9877명의 사용자로 구성vcount(sn.df)5.노드간의 연결된 edge는 총 몇 개인가? # 노드간의 연결된 edge의 총수,# 물리학 – 현상학 사용자간 총 연결수는 총 51..

들어가기 전에 앞서 천체 물리학 협업 네트워크를 다루기 위해서는 저번데 다루었던 페이스북 사용자 네트워크 데이터셋을 다운받은 사이트에서 다운을 받을 수 있다. 천체 물리학 협업 네트워크란 , 어떤 1명의 저자가 논문 1개를 내었을 때 , 혹은 공동작업을 하였을 때 의 ID값들이 서로 연결되어서 네트워크를 이루는 것을 말한다. 1. http://snap.stanford.edu/