
 CA-HepTh.txt
CA-HepTh.txt1.파일을 R코드에서 읽어 들인다.
sn <- read.table(file.choose(), header=F)
# file.choose를 사용해서 임의의 파일을 가져오고 이 파일을 table형식으로 읽어와서 sn에 저장함
2. 데이터의 head 부분을 읽어 들인다.
head(sn)
# 읽어온 테이블의 head로써 6개 까지 가져온다 // 앞에 부분쪽
-->결과물
V1 V2
1 24325 24394
2 24325 40517
3 24325 58507
4 24394 3737
5 24394 3905
6 24394 7237
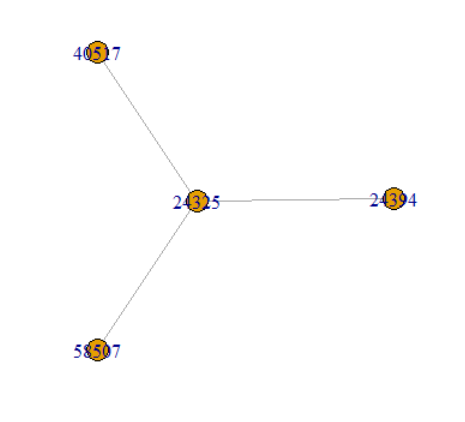
3.head에서 첫 번째 사용자와 연결된 사용자들의 그래프를 그려 저장한다. [그림 1]
sn1 <- subset(sn, sn$V1==24325)
# sn테이블 파일을 sn$V1 함으로써 V1에 접근하고 24325와 같은 값을 갖는 데이터를 부분집합으로 설정하고 sn1에 그 값을 저장시킴

sn1.df <- graph.data.frame(sn1, directed=FALSE)
# 24325의 값을 부분집합으로 뽑은 데이터를 무방향으로써 데이터프레임 ( sn1.df에 저장시킨다.)
plot(sn1.df)
# 24325의 값을 기준으로한 데이터프레임을 plot으로 뽑는다 .
4.네트워크 노드의 총수는 몇 명인가?
sn.df <- graph.data.frame(sn, directed=FALSE)
# graph.daa.frame 함으로써 테이블 형식으로 가져온 파일을 방향성없이 데이터프레임을 sn.df에 저장함
# 네트워크의 크기: 노드의 총수를 나타나며,
# 페이스북 사용자 데이터 세트는 총 9877명의 사용자로 구성
vcount(sn.df)
5.노드간의 연결된 edge는 총 몇 개인가?
# 노드간의 연결된 edge의 총수,
# 물리학 – 현상학 사용자간 총 연결수는 총 51971개로 구성
ecount(sn.df)
6.노드 중에서 연결정도가 최대인 것은 무엇인가?
# 노드 중에서 연결정도가 최대인 것
vmax <- V(sn.df)$name[degree(sn.df)==max(degree(sn.df))]
-->vmax
결과값 : “1441”
7.노드 중에서 연결정도가 최대인 노드의 연결정도(degree)는 몇 개인가?
# vmax(1441)에 해당하는 노드의 연결정도
degree(sn.df, vmax)
결과값 : 1441 : 130
8.노드 중에서 연결정도가 최대인 사용자와 연결된 사용자들의 그래프를 그려 저장한다. [그림 2]
# 사용자별 연결정도 그래프 , 여기서는 연결 정도가 최대인 사용자는 1441이므로 xlab에 1441를 대입한다 , 그러면 그래프를 출력할 수 있게 된다 .
plot(degree(sn.df), xlab="1441", ylab="연결 정도", type='h')
9.degree를 요약(summary)했을 때, 중앙값과 평균 연결정도(degree)는 얼마인가?
summary(degree(sn.df))
--> sn.df 데이터프레임의 전체적인 정도를 나타낸다 .
--> 출력값은 다음과 같다.
Min. 1st Qu. Median Mean 3rd Qu. Max.
2.00 4.00 6.00 10.52 12.00 130.00
중앙값 : 6.00
평균 연결정도 : 10.52를 추출할수 있게 된다 .
10.사용자별 연결정도 그래프를 그리세요. [그림 3]

plot(degree(sn.df), xlab="사용자 이름", ylab="연결 정도", type='h')
--> xlab은 사용자 이름이 오고 , ylab은 연결 정도를 함으로써 그래프를 출력할 수 있다 .
11. 연결정도 분포 및 출력된 결과를 어떠한 의미인지 해석해 보세요. [그림 4]

연결정도 분포 및 출력된 결과를 보고 싶다면 다음과 같은 순서를 지켜야 한다 .
1. sn.df.dist <- degree.distribution(sn.df) --> distribution 은 분포를 의미하는데 degree가 정도를 의미한다 . 그렇기 때문에 분포정도를 나타내게 되는데 어떤 분포정도이냐면 읽어온 파일의 데이터프레임을 분포정도를 그래프로 나타내는 것이다 .
2. plot(sn.df.dist, xlab="연결 정도", ylab="확률")
--> 다음은 위코드를 입력하면 된다 , 위 코드가 의미하는 것은 분포정도를 추출한 것을 plot으로 나타내는 것인데 , xlab은 연결정도를 의미하고 , ylab은 확률을 의미한다 .
출력결과는 연결정도가 작은 노드들이 많고, 연결정도가 큰 노드들은 적은 분포를 나타낸다.
이러한 모양의 분포를 멱함수 분포라고 부르고 ,네트워크의 많은 분포는 정규분포와는 다르게 멱함수 분포를 띠고 있다.
'학부공부 > 데이터마이닝과통계' 카테고리의 다른 글
| 웹 스크래핑 맛보기(Web Scraping) (0) | 2018.10.30 |
|---|---|
| 기간환율변동 데이터 분석하기 (0) | 2018.10.25 |
| 천체 물리학 협업 네트워크를 다뤄보자. (0) | 2018.10.03 |
| 페이스북 사용자 네트워크 분석 (0) | 2018.09.30 |
| 네트워크만들기 (0) | 2018.09.22 |
#IT #먹방 #전자기기 #일상
#개발 #일상