
웹 크롤링할 일이 생겨서 하다가 , 안되는 부분이 있어서 적어보고자 한다.
기존 코드이다.
XML 라이브러리를 통해서 크롤링에 접근할려고 했다.
library(XML)
url <-http://www.coupang.com/np/search?q=%EC%97%AC%EC%84%B1%ED%81%AC%EB%A1%9C%EC%8A%A4%EB%B0%B1
è 먼저 내가 Parsing 하고자 하는 url을 긁어온다.
doc <- htmlParse(url, encoding="utf-8")
è 긁어온 url을 html 코드로 변환하며 encoding 방식도 설정해 줄수 있다.
prod_name <- xpathSApply(doc, "//ul[@id='productList']//div[@class='name']", xmlValue)
è 내가 긁어온 html 코드에 접근을 하고 , ul태그내에 있는 id 값이 productList인것에 1차 접근을 하고 //을 통해서 건너뛴 다음 , div 태그 내에 있는 class 값이 name인 것에 2차 접근을 하는 것이였다. 그런데 여기서 오류가 나는 것이다. Class 가 NULL이라고 한다… 내 뇌피셜이지만 class를 못찾거나 , class명이 잘못된것이라고 생각을 했다.
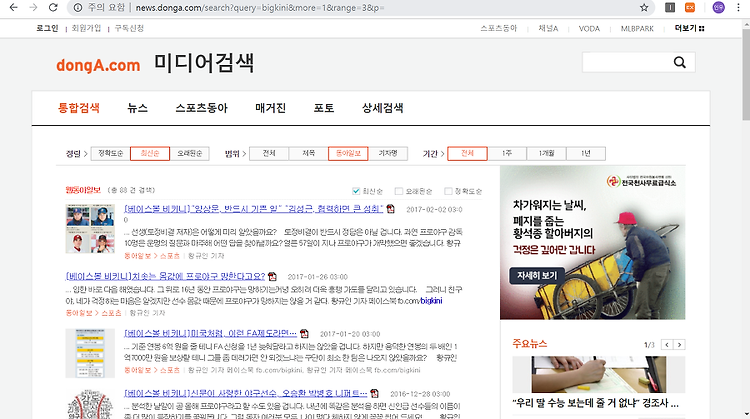
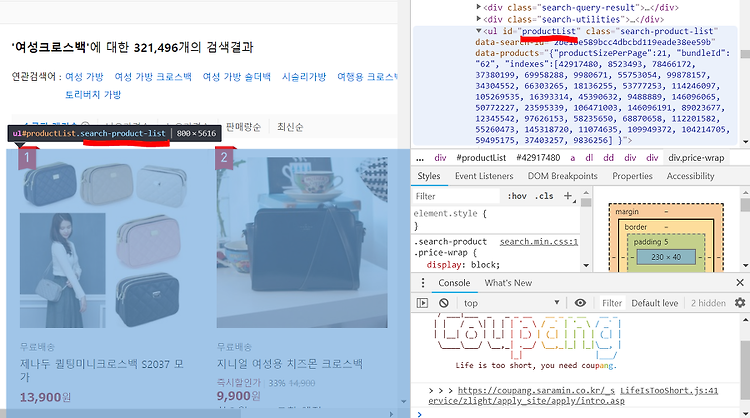
그래서 coupang 사이트에 들어가서 검사를 통해 직접 확인해 보았다.

위의 그림에서 보이는 것처럼 상위 태그인 ul 태그의 id값은 동일했다.
그래서 밑으로 더 내리다가 내가 찾고자 하는 title의 명또한 맞는지 확인해 보았다.

Div 태그로 둘러싸인 class 명은 name이 맞다….
도대체 무엇이 문제일까…
정말 답이 안나와서 … 구글링을 하다가 Rvest 패키지라는 것을 알게 되었다
Rvest는 R에서 웹 크롤링을 할 때 사용하는 라이브러리 패키지이다.
먼저 install.packages(“rvest”) 를 통해서 패키지를 다운받는다.
library(rvest) 패키지 로딩을한다.
url <-"http://www.coupang.com/np/search?q=%EC%97%AC%EC%84%B1%ED%81%AC%EB%A1%9C%EC%8A%A4%EB%B0%B1"
#해당 url을 새로운 변수에 저장한다.
html <-read_html(url,encoding = "UTF-8")
#url에서 html파일을 읽어오고 저장한다.
아마 여기까지는 XML패키지를 사용해서 하는 방법이 똑같을 것이다.
이제 부터는 약간 다를것이다.
아참 , Rvest는 접근하는 방법이 약간다르다 .
titles <- html %>% html_nodes(".name") %>% html_text()
먼저 html코드로 가져온 값들에 html_nodes라는 함수를 이용해서 class = name 인 부분에 접근을 한다 . name 클래스에 접근 후 html_text()를 통해서 name 클래스의 값들을 출력하게 된다.
쉽게 말해서 Parsing한 html에서 css가 ‘name’인 것을 찾아주세요 라고 이해하면 쉬울 것 같다
이렇게 하면 name클래스의 값들이 벡터 형태로 담길 것이다 .
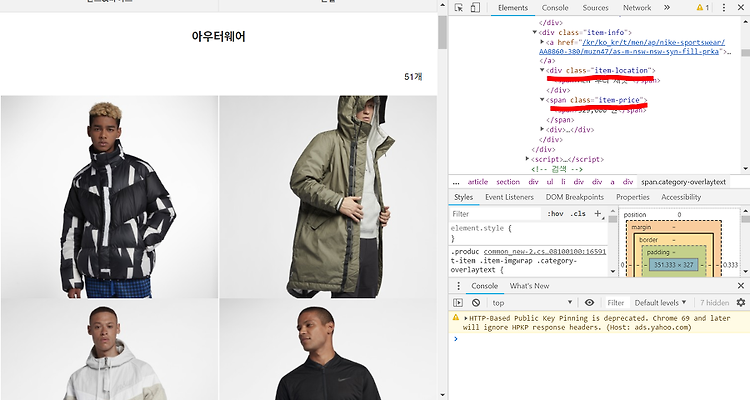
나는 가격의 정보를 필요로 하므로 , 위와 똑 같은 방법으로 가격을 가져올 것이다.

가격이 나와있는 부분을 확인해 보자 . class 명은 sale로 되어있는 것을 확인가능하다.
price <- html %>% html_nodes(".sale") %>% html_text()
이렇게 함으로써 가방명과 가격을 각각 벡터형태로 가져왔다.
그런데 , 가져온 값들이 이쁘지가 않기 때문에 gsub를 통해서 불필요한 부분을 삭제해 줄거이다.
titles <- gsub('\n','',titles)
titles <-gsub('\t','',titles)
titles <- gsub(' ','',titles)
è 공백의 제거를 해준다.
df <- data.frame(상품명=titles, 가격=price)
è Title , price를 각각 상품명 , 가격으로 설정후 새로운 데이터 프레임 하나 생성한다.
df$상품명 <- format(df$상품명 , justify = "left")
è 상품명의 위치를 왼쪽으로 고정시켜 준다.
이렇게 함으로써 기존의 XML 라이브러리 대신 Rvest라는 패키지를 이용해서 크롤링을 해 보았다.
그런데 첫페이지만 추출한다고 하였을 경우 위에서 처럼 하면 되는데 , 첫 페이지 뿐만 아니라 특정 페이지들을에서 접근을 하려고 하면 어떻게 해야할까…??
이럴 때는 for문을 통해서 구할수 있게 된다.
다음 코드를 보자.
df.products <- NULL
for (page in 1:10)
{
url2 <- paste(url,page,sep="")
// 이부분에서 paste를 통해서 url 뒤에 page라는 for문 변수를 통해 page의 이동이 가능해 질 것이다 .


위에서 처럼 page의 값에 따라 page의 이동이 되는 것을 확인할 수 있다.
밑에 부분은 위와 동일 하다.
doc <-htmlParse(url2,encoding="UTF-8")
titles <- html %>% html_nodes(".name") %>% html_text()
titles <- gsub('\n','',titles)
titles <-gsub('\t','',titles)
titles <- gsub(' ','',titles)
price <- html %>% html_nodes(".sale") %>% html_text()
df <- data.frame(상품명=titles, 가격=price)
df.products <-rbind(df.products,df)
}
마지막으로 Rvest를 사용하기 위해서는 몇가지 개념을 알아야 한다.

Node : html에서 tag라고 하는것들 , 위에서는 <h1> , <p> , <title>이 되겠다.
내가 원하는 Node에 접근하기 위해서는 tag이름 , tag의 id속성 , tag의 class 속성 , tag의 custom 속성을 알고 있어야 한다.
접근 하는 방식은 다음과 같다.
Tag , #id , .class , [attr =”val”] , tag#id , tag.class , tag[attr=”val”]
Text가 무엇인지도 알아야 한다.
왜냐하면 태그로 둘러싸인 부분의 값들을 가져올 경우가 분명히 있다.
Text은 시작태그와 종료 태그 사이에 있는 글자이다.
예를 들면 <tag attr1=”qweqwe”> 안녕??</tag> : 여기서는 안녕??이 text가 되겠다.
Rvest의 동작 순서 ( text 가져오기 )
1. Html 문서 데이터 가져오기
2. 필요한 노드 선택하기
3. 노드내에 text를 가져오기
위에서 처럼 %>%을 통해서 태그안으로들어가는 것을 확인할 수 있었다.
들어간다고 표현이 조금 그렇지만 이 부분이 Rvest의 동작 순서인 것이다.
html_node() Vs html_nodes() 의 차이점
html_node()는 매칭되는 한 요소만 반환하고 , html_nodes() 는 모든 요소를 반환한다.
id를 찾을 경우에는 html_node() 를 사용하며 , tag or class 를 찾을 경우에는 html_nodes()를 사용한다.
마지막으로 몇 가지 함수들이 존재한다.
html_text() : 텍스트를 추출한다.
html_name() : attribute의 이름을 가져온다.
html_children() : 해당 요소의 하위 요소를 읽어온다.
html_tag() : tag이름 추출
html_attrs() : attribute를 추출한다
출처
https://blog.rstudio.com/2014/11/24/rvest-easy-web-scraping-with-r/
https://mrchypark.github.io/getWebR/#19
'학부공부 > 데이터마이닝과통계' 카테고리의 다른 글
| 동아신문 스크랩핑 (0) | 2018.11.14 |
|---|---|
| 나이키 사이트 크롤링 (0) | 2018.11.10 |
| 웹 스크래핑 맛보기(Web Scraping) (0) | 2018.10.30 |
| 기간환율변동 데이터 분석하기 (0) | 2018.10.25 |
| CA-HepTh.txt ( 고에너지 물리학 - 현상학 ) 분석하기 (0) | 2018.10.05 |
#IT #먹방 #전자기기 #일상
#개발 #일상