
기간환율변동 데이터 분석하기

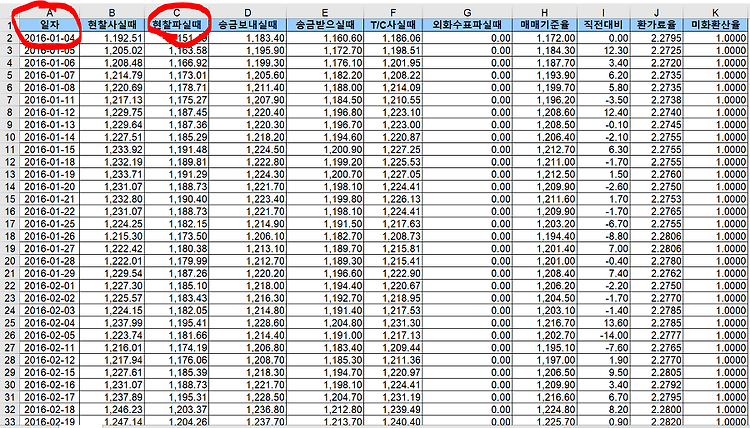
제가 분석해볼 컬럼 명은 “일자”를 기준으로 , “현찰파실 때” 컬럼의 데이터를 가공하고 분석해서 , plot으로 나타내 볼 것이며 , 예측과 예측값의 정확도를 분석해 볼 것입니다.
그런데 , 분석하기 앞서서 데이터의 예측과 분석이 어떻게 이루어 지는지 , 다음 그림을 통해서 간략화 시킬 수 있습니다.

먼저 , 학습을 통한 예측을 통해 , 실제 데이터를 다루고 , 실제 데이터를 기반으로 학습을 한 데이터를 통해 예측을 합니다 . 예측을 통해서 학습을 하였고 , 이제 데이터 예측을 합니다.
그렇다면 어떻게 예측을 하고 , 학습을 할 수 있을까요?
간단한 플로차트로 나타내 보자면 다음과 같습니다.
1. 데이터 준비
ㄱ. 데이터 파일 읽기 [data <- read.xlsx2()]
ㄴ. 데이터 정규화하기 [Pnorm <- …]
ㄷ. 학습 데이터 세트 만들기 [df.learning <- df[1:n80,]
ㄹ. 테스트 데이터 세트 만들기 [df.test <- df[(n80+1):n,]
2. 인공신경망 모형 설계
3. 학습
ㄱ. 입력 데이터 만들기 [in_learning <- getDataSet()]
ㄴ. 출력(목표) 데이터 만들기 [out_learning <- getDataSet() ]
ㄷ. 학습 [ model <- nnet() ]
4. 테스트
ㄱ. 입력 데이터 만들기 [ in_test <- getDataSet() ]
ㄴ. 예측 [predicted_values <- predict() ]
ㄷ. 실제값 읽기 [ real <-getDataSet() ]
ㄹ. 오차 계산 및 출력 [ MAPE <- rowMeans(ERROR/real) * 100 ]
5. 최적 모형 선정
6. 예측
ㄱ. 입력 데이터 만들기 [ in_forecasting <- getDataSet() ]
ㄴ. 예측 [ predicted_values <- predict() ]
ㄷ. 그래프 출력 [ plot() ]
간단한 함수와 수식을 정리 하면 위의 플로차트로 나타낼 수 있습니다.
이제 본론에 들어가서 R에서 어떻게 구현하는지 보겠습니다.
library(xlsx)
library(nnet)
이때 사용되는 라이브러리는 위와 같은데 , 없을 경우 install.packages를 통해 설치해줍니다.
데이터 파일 읽기
data3 <- read.xlsx2(file.choose(),1)
file.choose를 통해서 내가 분석하고자 하는 파일을 선택해 주고 , 1은 첫번째 시트를 의미합니다.
data3$현찰파실때 <- gsub(",","",data3$현찰파실때)
읽어온 데이터 파일에서 “현찰파실떄” 칼럼의 콤마(,)를 제거해 줍니다.
data3$현찰파실때 <- as.numeric(data3$현찰파실때)
제거한 data3$현찰파실 때의 형태를 숫자형태로 변환합니다.
df <- data.frame(일자=data3$일자,현찰파실때=data3$현찰파실때)
데이터에서 칼럼명이 일자 , 현찰파실때의 데이터를 새로운 데이터 프레임으로 만듭니다.
df <- df[order(df$일자)]
데이터프레임의 데이터를 일자 칼럼의 오름차순으로 정렬을 시킵니다.
n <- nrow(df)
데이터프레임의 행의 수를 가져옵니다.
rownames(df) <- 1:n
데이터프레임의 행의 수를 1~n까지 가져오는데 , n은 위에서 가져온 값이다.
데이터 정규화
Pnorm <-(df$현찰파실때-min(df$현찰파실때)) / (max(df$현찰파실때)-min(df$현찰파실때)) * 0.9 + 0.05
정규화 공식에 의해서 데이터를 정규화 시켜줍니다.
df <- cbind(df,현찰파실때norm=Pnorm)
데이터 프레임에 “현찰파실 때”의 칼럼을 정규화 시킨 값들을 추가해줍니다.
학습과 테스트 데이터 분리
n80 <- round(n*0.8,0)
데이터 세트의 80%에 해당하는 행 번호를 소수점 0자리(정수)로 반올림시킵니다.
df.learning <- df[1:n80,]
학습 데이터 세트를 만들어 줍니다.
여기서는 1~146행까지 출력이 될 것입니다.
df.test <- df[(n80+1):n,]
테스트 데이터 세트 만들기
테스트 데이터는 147~183행까지 출력이 될 것입니다.
인공신경망 모형구조 설계
INPUT_NODES <- 10 / 입력 노드 수
HIDDEN_NODES <- 10 / 은닉층의 노드 수
OUTPUT_NODES <- 5 / 출력 노드 수
ITERATION <- 100 / 학습 반복 수
위의 값들은 인공신경망 모형의 구조를 정의해 주기 위한 임의의 값들입니다.
이제는 입출력 데이터 파일 생성 함수를 만들어 줄 것입니다.
getDataSet <- function(item,from,to,size)
{
dataframe <- NULL
to <- to-size +1 // 마지막 행의 시작 날짜 번호
for(i in from:to) // 각 행의 반복
{
start <- I // 각 행의 시작 날짜 번호
end <- start + size -1 // 각 행의 끝 날짜 번호
temp <- item[c(start:end)] //item에서 start-end 구간의 데이터 추출
dataframe <- rbind(dataframe,t(temp))
// t()함수를 사용하여 열 단위의 데이터를 행으로 전환한 후 데이터 프레임의 행에 추가
}
return(dataframe) // 데이터 프레임 반환
}
학습
in_learning <- getDataSet(df.learning$현찰파실때norm,1,92,INPUT_NODES)
입력 데이터를 만들어 준다.
학습 데이터 세트의 정규화된 칼럼 “ 현찰파실때”에서 1~92번째 데이터로부터 각 행이 입력 노드 수의 크기가 되는 입력 데이터 세트를 만든다.
out_learning <- getDataSet(df.learning$현찰파실때norm,11,97,OUTPUT_NODES)
출력 데이터를 만들어 준다.
학습 데이터 세트의 정규화된 칼럼 “현찰파실 때”에서 11~97번째 데이터로부터 각 행이 출력 노드 수의 크기가 되는 출력(목표)데이터 세트를 만든다.
model <- nnet(in_learning, out_learning, size = HIDDEN_NODES, maxit = ITERATION)
이제 학습을 해준다.
입력 데이터 세트와 출력 데이터 세트 , 그리고 은닉층 노드 수에 해당하는 모형 생성과 학습 , maxit을 설정해 주는데 이값은 학습 수를 의미한다.
테스트
입력 데이터 작성과 예측
in_test <- getDataSet(df.test$현찰파실때norm,1,19,INPUT_NODES)
입력 데이터를 만들어 준다.
테스트 데이터 세트의 정규화된 칼럼 “현팔파실 때”에서 1~19번째 데이터로부터 각 행이 입력 노드 수의 크기가 되는 입력 데이터 세트를 만든다.
예측
predicted_values <- predict(model, in_test, type="raw")
학습된 모형을 이용해서 입력 데이터에 대한 예측치를 만든다.
Vpredicted <- (predicted_values-0.05)/0.9*(max(df$현찰파실때)-min(df$현찰파실때)) + min(df$현찰파실때)
정규화된 예측치를 원 데이터 범위로 변환시킨다.
오차계산
각 예측 기간별 실제 데이터
Vreal <- getDataSet(df.test$현찰파실때,11,24,OUTPUT_NODES)
테스트 데이터 세트의 칼럼 “현살파실 때”에서 11~24번째 데이터로부터 각 행이 출력 노드 수의 크기가 되는 출력(목표) 데이터 세트의 형시으로 실제 데이터 세트를 만든다.
ERROR <- abs(Vreal - Vpredicted) // 각 행별 각 열들 간 절대오차를 구한다.
MAPE <-rowMeans(ERROR / Vreal) * 100 // 각 행별 각 열의 실제값 대비 절대오차를 행별로 평균(rowMeans)하여서 백분율(%)로 나타낸다.
mean(MAPE)// 각 행들의 MAPE에 대한 전체 평균값
예측
in_forecasting <- df$현찰파실때norm[30:40]
입력 데이터를 만든다.
predicted_values <- predict(model,in_forecasting,type="raw")
예측을 한다.
Vpredicted <-(predicted_values -0.05) / 0.9*(max(df$현찰파실때)-min(df$현찰파실때)) + min(df$현찰파실때)
그래프 출력
plot(30:80 , df$현찰파실때[30:80], xlab="일자" , ylab="현찰파실때", xlim=c(31,85), ylim=c(1000,2000), type="o")
30~80 시점에 대한 현찰파실때에 대한 과거 데이터를 출력하고 , 예측치 출력을 위해 x축은 31~85로 설정한다.
lines(81:85 , Vpredicted , type="o" , col="red")
그래프의 81~85 시점에 예측치를 추가한다.
abline(v=80, col="blue", lty=2)
실제치와 예측치 구분을 위해 80시점에 수직 점선을 추가한다 .

정리를 해보자면 , 80을 기준으로 학습을 통한 값들이 출력이 되는데 , 1200을 기준으로 위아래로 값들이 위치하는 것을 확인할 수 있습니다. 이 값들을 기반으로 데이터 예측을 하였는데 , 기존 데이터의 값들보다 위쪽에 위치하는 것을 확인할 수 있습니다. 한가지 의문인 점은
plot(30:80 , df$현찰파실때[30:80], xlab="일자" , ylab="현찰파실때", xlim=c(31,85), ylim=c(1000,2000), type="o")
이 부분에서 ylim의 값의 범위를 초반에 (100000,200000 ) 이렇게 주었습니다. 왜냐하면 제가 출력하고자 하는 칼럼의 숫자범위를 보게되면 10만 단위였고 , 당연히 범위도 10만단위부터 시작해야 된다고 생각을 하였습니다. 이렇게 주다 보니 그래프가 출력이 안되는 것입니다. 또한 기존에 학습을 통한 데이터의 그래프도 안뜨고 , 예측 데이터의 값들도 출력이 안됬습니다. 생각을 해보다가 , 학습을 통한 데이터의 값을 보니까 , 1000~2000사이의 값들로 출력이 된 것을 알 수 있었습니다. 그래서 범위를 (1000,2000)을 주었더니 그래프가 잘 출력이 되었습니다.
여기서 한가지 더 알게 된 것은 기존의 칼럼의 값들이 정규화를 통해서 값이 변하고 , n80을 통해서 반올림을 해주었기 때문에 1000~2000사이의 값들로만 뭉쳐진다는 것을 알게 되었습니다.
'학부공부 > 데이터마이닝과통계' 카테고리의 다른 글
| 쿠팡 웹 크롤링 맛보기 (2) | 2018.11.01 |
|---|---|
| 웹 스크래핑 맛보기(Web Scraping) (0) | 2018.10.30 |
| CA-HepTh.txt ( 고에너지 물리학 - 현상학 ) 분석하기 (0) | 2018.10.05 |
| 천체 물리학 협업 네트워크를 다뤄보자. (0) | 2018.10.03 |
| 페이스북 사용자 네트워크 분석 (0) | 2018.09.30 |
#IT #먹방 #전자기기 #일상
#개발 #일상