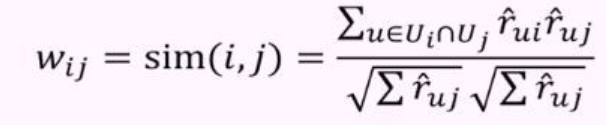

졸작 준비중에 있는데 ,
추천시스템을 알아야 하는 과정이 필요했다.
그래서 짧게 나마, 추천시스템이 무엇이며 , 어떤 것들이 있고 , 어떤 알고리즘을 사용하는지 알아볼 것이다.
추천 시스템이란 ???
대상자가 좋아할 만한 무언가를 추천하는 시스템을 일컫는다.
예를 들어서 , 쇼핑을 하기 위해 웹사이트를 방문하면 당신에게 추천할 만한 아이템이라는 것을 보거나 혹은 특정 상품의 정보를 얻기 위해 클릭을 하면 화면 어딘가에 추천아이템 , 인기아이템 , 당신이 좋아할 만한아이템 등 다양한 이름으로 상품을 추천하는 것을 쉽게 발견할 수 있다.
추천시스템의 주요기술
협업필터링(Collaborative Filtering)
협업필터링은 다음과 같은 가정을 기반으로 만들어진 기술로 추천시스템의 가장 기본적이면서도 중요한 핵심기술이라고 할 수 있다.
유유상종 : 끼리끼리 모인다.
예를 들어 A라는 사람이 부산행이라는 영화를 좋아하면 , A와 성향이 비슷해 보이는 B라는 사람 역시 부산행을 좋아할 것이라는 생각을 활용한 방법이다.
이 아이디어는 매우 단순한 생각이지만 현실세계에서 매우 잘 동작하는 것 중의 하나로 거의 모든 추천시스템에서 활용하고 있는 기술이다.
Collaborative Filtering은 대상이 무엇이냐에 따라 User-based Collaborative Filtering ( 사용자기반 협업 필터링 ) 과 item-based Collaborative Filtering ( 아이템기반 협업 필터링 ) 2가지로 나뉜다.
사용자기반 협업 필터링 ( User-based Collaborative Filtering )
è 유사한 성향을 가진 사람들을 구분하고 , 해당 성향의 사람들이 좋아하는 것을 이용해 추천하는 방식이다.
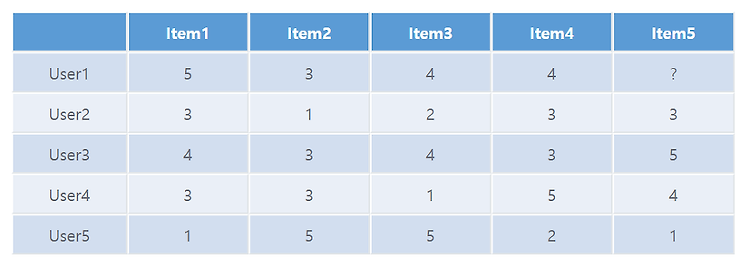
다음과 같은 표가 있다고 하자 .

위의 데이터는 User1,2,3,4,5가 Item 1,2,3,4,5에 매긴 평점을 나타내는 것이다.
예를 들어서 User1은 item1에 대해 5점이라는 평점을 주었고 , User3는 item4에 대해 3이라는 평점을 주었다.
이제 User1에게 item5를 추천하는 것이 적당한지를 판별하기 위해 User1과 비슷한 성향을 가진 사용자를 찾고 해당 사용자가 item5에 준 평점이 높다면 , 아마도 User1은 item5를 좋아할 것이라고 생각하고 추천한다.
그런데, 문제는 위의 표에서 User1과 가장 유사한 성향을 가진 사람이 누군지를 파악하는 것이다.
유사한 성향을 유사도 ( Similarity ) 라고 하며 , 유사도가 높다는 것은 그만큼 서로 유사한 성향을 가졌다고 할 수 있다.
유사도는 협업 필터링에서 중요한 척도이다. 왜냐하면 이 척도를 이용해 사용자 간의 유사도 , 혹은 아이템 간의 유사도를 계산할 수 있기 때문이다.
계산된 유사도를 이용해 가장 유사하다고 생각되는 사람이나 아이템을 선정할 수 있고, 그 선정된 것에 의해 사용자에게 무엇을 추천하는 것이 좋은지를 결정할 수 있다.
아래의 식은 많이 활용되는 피어슨 상관계수를 이용한 유사도를 계산하는 식이다.

피어슨상관계수는 비교대상이 되는 2개의 변수가 선형적인 관계를 추정하는 방법으로 변수들의 값이 동일한 방향으로 움직이는지 , 그렇지 않은지를 파악해 비례관계인지 , 반비례관계인지 아니면 관계가 없는지를 추정할 수 있다.
위의 식을 이용해 User1과 다른 사용자들간의 유사도를 계산해보면 다음과 같다.
Sim(User1, User2) = 0.85
Sim(User1, User3) = 0.70
Sim(User1, User5) = -0.79
위의 값에서 알 수 있듯이 User1과 가장 유사한 사람은 User2라는 것을 알 수 있다.
User2의 Item5의 평점은 3점이라는 것을 알 수 있다.
하지만 , User2의 평점이 3점이라는 것을 User1이 Item5에 대한 평점이라고 생각하기는 어렵다 .
왜냐하면 , User2의 성향이 평점을 낮게 주거나 혹은 반대로 평점을 많이 준다면 3점이라는 평점을 그대로 3점의 평점으로 받아 들일 수 없기 때문이다 .
그래서 보완한 새로운 방법이 필요하다 .

위의 식은 언급한 문제점을 해결하기 위한 방법으로 (r_a ) ̅ 의 값을 기준값으로 설정하고 , 유사도에 따른 다른 사용자의 평점을 이용해 가중치를 조절하는 방식으로 최종저으로 User가 특정 Item을 좋아할지 말지를 계산한다 .
아이템기반 협업 필터링 (Item-based Collaborative Filtering )
è 이 방식은 앞서 설명한 사용자기반 협업 필터링과 모든 아이디어가 동일하지만 대상이 사람이 아닌 아이템으로 대치된 것이다.
예를 들자면 , A에게 물건을 추천한다면 A가 과거에 좋아했던 물건을 찾고 , 해당 물건과 유사한 물건을 추천해주는 방식이다.
아이템기반 협업 필터링에서 많이 사용하는 유사도 계산방법인 코사인유사도(Cosine Similarity)에 대해 알아보자 .

코사인유사도는 평점을 벡터로 생각하고 , 2개 벡터사이의 각도를 계산하고 , 그 각도가 작을수록 가까이 있기 때문에 유사하다고 판단
하는 방식이다.
사용자기반 협업 필터링과 아이템기반 협업 필터링을 Memory-based Methods 라고 한다.
이 기술의 가장 큰 장점은 구현이 간단하고 이해하기 쉽다는 것이다 . 유사도를 구하거나 예상 평점을 구하는 것이 일반적인 머신러닝
처럼 대량의 데이터를 이용해 모델을 만들고 , 해당 모델의 평가를 하고 , 이를 최적화하는 과정이 필요치 않고 단 순한 몇가지의 수식으
로 쉽게 계산이 가능하다 .
단점은 평점에 대한 정보가 많지 않은 경우에는 예측의 정확도가 높지 않은 것이다.
예를 들자면 , 사용자에게 “inwookim” 이라는 책을 추천하려고 하는데 , 이 책이 신간이라 아직 평점이 없다면 “Collaborative Filtering”
은 적절한 평점을 예측할 수 없다. 그리고 이와 더불어 범위성 ( Scalability ) 문제가 있어 사용자나 아이템이 매우 많다면 실시간으로 사
용하는데 계산시간이 오래걸리기 때문에 적용하기 어렵다 .
모델기반 방법 ( Model-based Methods )
è 이 방식은 머신러닝을 이용해 평점을 예측할 수 있는 모델을 만드는 방식이다.
앞서 얘기한 Memory-based 방식에서는 별도의 모델을 만들지 않았기 때문에 평점을 가지고 있지 않은 것에 대해서는 효과가 없었던
반면 Model-based 방법에서는 과거의 사용자 평점 데이터를 이용해 모델을 만들었기 때문에 평점 정보가 없다하더라도 특정 아이템에
대한 사용자의 평점을 예측할 수 있다 .
의사결정트리 , SVM 등의 머신러닝 알고리즘을 이용해 평점예측모델을 만든다 .
모델을 만드는데 사용되는 방법들은 다음과 같다 .
ㄱ. Matrix Factorization
- SVD ( Singular Value Decomposition )
- PCA ( Principal Component Analysis )
ㄴ. Association Rule Mining
- Shopping basket analysis
ㄷ. Probabilistic Models
- Clustering , Bayesian networks
ㄹ. Other Techniques
- Regression , Deep learning , SVM
Model-based 방법에는 여러가지가 있지만 , Netflix Prize Contest 를 통해 대부분의 추천시스템에서 사용되는 중요한 기술인 SVD ( Singular
Value Decomposition ) 에 대해서 알아본다.
SVD는 차원축소기술 (Dimensionality Reduction) 의 일종으로 사용자와 아이템의 평점데이터를 행렬로 생각하고 이를 U와 V로 분리하는 것을 말한다.
실수나 복소수로 이루어진 원소의 구성되는 m * n 행렬 M은 다음과 같은 3개 행렬의 곱으로 분해할 수 있다 .

U는 m*m의 크기를 갖는 직교행렬을 의미하고 , Σ는 m*m의 크기를 가지는 대각행렬이고 , V는 n*n의 유니터리 행렬을 나타낸다.
여기서 중요한 사항은 행렬 U는 MM^T , V는 M^T M의 고유벡터를 각각 포함하고 있다는 점이다.
행렬 V가 M^T M의 고유벡터를 가지고 있다는 것의 의미는 해당 행렬이 row space에 대한 차원축소를 실행한 것이고 , 이는 곧 item-item 상관관계에 대한 고유치를 가지고 있다는 것으로 해석할 수 있다.
행렬 UΣ 는 원래의 평점행렬을 행렬 V에 대한 관계로 변형한 것으로 이야기 할 수 있다.
이와 같이 생각하면 SVD는 원래 사용자와 아이템의 관계를 일반적인 2차원의 직교좌표계를 이용해 표현했던 것을 사용자와 아이템에 대한 고유치를 계산하고 , 계산된 고유치를 이용해 기존의 평점데이터로 다시 표현한 것이다 .
위의 SVD그림에 빗대어 설명하면 σ_1 과 σ_2 는 기존의 데이터를UΣ 행렬과 V행렬을 이용해 새로운 좌표계를 만들고 , 이것을 기준으로 기존의 데이터를 변형해 나타낸 것으로 이해할 수 있다 .
데이터를 SVD 형태로 나타내게 되면 차원축소의 이점으로 데이터가 작아지는 것과 더불어 노이즈제거에도 효과적이다 . 데이터를 새롭게 설정된 좌표계에서 표현할 때 다른 값들과의 차이가 크다면 그만큼 노이즈일 가능성이 크다고 생각할 수 있다. 왜냐하면 새롭게 구축된 좌표계는 사용자와 아이템의 고유값을 계산한 것이기 때문이다 .
평가방법
Collaborative Filtering을 이용해 추천시스템을 개발했다면 해당 시스템의 성능을 평가해야 한다.
평가를 위한 방법은 크게 다음과 같은 3가지로 나누어 볼 수 있다.
1. 사용자 평가
2. 온라인 평가
3. 오프라인 평가
사용자평가와 온라인 평가는 사용자에 의한 평가라는 공통점을 가지고 있다. 이 둘의 가장 큰 차이는 추천시스템의 평가를 위해 어느 시점에 사
용자를 활용하는가에 있다.,
사용자 평가는 특정한 시점에 사용자를 초청해 추천시스템의 성능을 점검해보는 것이고 온라인평가는 추천시스템이 실제 환경에서 활용되고 있
는 상황에서 사용자가 보여주는 행위를 보고 성능을 평가하는 방식이다.
오프라인 평가는 과거의 데이터를 이용해 평가하는 방식으로 데이터 기반의 평가이기 때문에 사용자를 초청할 필요가 없다 .
사용자 평가
사용자평가에서는 사용자를 초청하고 , 추천시스템을 사용하도록 요구한다. 그리고 사용자들로부터 피드백을 받는다. 피드백의 반응이 좋으면 , 성능이 좋은 추천시스템으로 평가하는 방식이다 .
사용자평가의 최대 장점은 평가를 위해 초청한 사용자들에게 원하는 정보를 물어보고 , 수집할 수 있다는 점이다. 단순하게는 추천시스템에 대한 선호도를 물어볼 수 있고 , 온라인평가에서는 알기 어려운 사용상의 문제점 , 추천의 적합도에 이유등을 자유롭게 물어볼 수 있다.
사용자평가는 초청된 사용자가 추천시스템을 평가하기 위해 왔다는 것을 인지하고 있기 때문에 100% 자신의 의사를 명확하게 표현하기 어려울 수도 있고 , 환경적인 요소로 인해 왜곡된 대답을 할 수도 있다는 점을 인지해 추천시스템의 최종적인 평가를 해야 한다 .
온라인평가
온라인평가는 사용자를 별도로 초청하지 않고 , 실제 환경등에 추천시스템을 적용하고 , 사용자의 행위를 보고 , 추천시스템의 성능을 파악하는 방식이다 .
이 방식은 사용자가 추천시스템 평가를 하고 있다는 사실을 인지하고 있지 않기 때문에 사용자평가에서 발생할 수 있는 문제인 왜곡이 발생하지 않는 장점이 있다.
온라인평가에서는 A/B 테스팅을 이용해 추천시스템의 성능을 평가한다.
예를 들어 추천시스템을 적용하지 않은 경우와 적용한 경우의 2가지 상황을 무작위적으로 사용자에게 보여주고 , 이 둘의 결과를 비교하는 방식이다.
만약 추천시스템을 적용하지 않은 상황에서의 CTR ( Click Through Rate )가 10% 였고 , 적용했을 때 CTR이 20% 였다면 추천시스템이 기존대비 성능이 좋다고 평가하는 방식이다.
이를 좀더 구체적으로 표현하면 다음과 같다.
1. 사용자그룹을 2개의 그룹 A와 B로 나눈다.
2. 그룹 A에는 추천시스템을 적용하지 않고 , 그룹B에만 추천시스템을 적용한다
( 혹은 그 반대로 시행한다 . )
3. 일정시간이 지난 후에 그룹 A/B의 CTR과 같은 수치를 비교한다.
이 방식은 의료계에서 신약의 효과를 측정하기 위해 사용하는 방법과 매우 유사하다.
보다 정확한 평가를 위해서 동일한 사용자에게 추천시스템을 활용하는 경우와 그렇지 않은 경우를 모두 시험하는 경우도 있다.
오프라인평가
오프라인평가에서는 추천시스템의 성능을 평가하기 위해 과거의 데이터를 이용한다.
예를 들어 앞서 설명한 Netflix Prize Contest가 오프라인평가의 가장 대표적이다.
참가자들이 추천시스템을 만들고 , 해당 시스템에 과거의 데이터를 넣어서 얼마나 정확하게 예측하는지를 평가한다.
오프라인평가는 평가방법과 평가항목을 표준화시킬 수 있기 때문에 추천시스템 평가에서 자주 활용된다.
평가항목은 Accuracy , Coverage , Confidence , Novelty 등 다양한 항목들이 있다.
출처 : https://www.oss.kr/
'졸업작품_preparing.... > 알고리즘' 카테고리의 다른 글
| Metacritic이란 무엇인가 (0) | 2019.01.20 |
|---|---|
| Random Forest는 무엇인가 (0) | 2019.01.14 |
| 의사결정나무란 무엇인가 (0) | 2019.01.12 |
| 결정 트리 학습법이란 무엇인가 (0) | 2019.01.12 |
| Item-based-Filtering 이란 무엇인가 (0) | 2019.01.03 |
#IT #먹방 #전자기기 #일상
#개발 #일상