
동아 신문 사이트를 스크랩핑해보는 시간을 가져볼 것이다.
소스 코드는 다음과 같다.
library(rvest)
library(dplyr)
우선 기본적으로 rvest 와 dplyr 패키지를 로딩시켜준다.
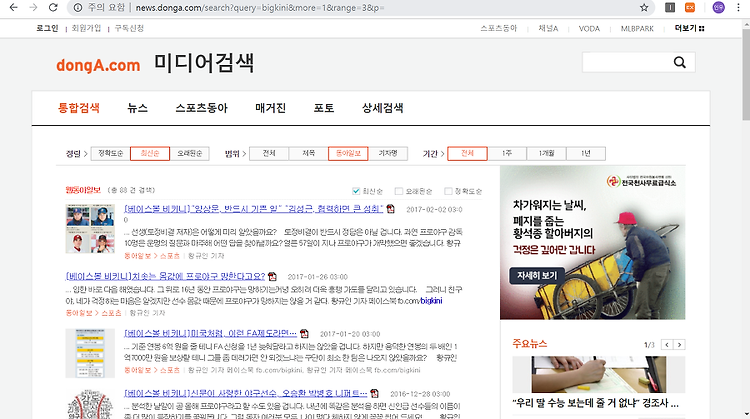
url <- "http://news.donga.com/search?query=bigkini&more=1&range=3&p="
내가 스크랩핑 하고자 하는 부분의 url 주소를 가져온다.

urls <- NULL
임시 변수 urls
for(x in 0:5)
{
urls[x+1] <- paste0(url,as.character(x*15+1))
}
for문을 통해 동아 신문의 특정 페이지 값을 설정시켜 주게 되는데 , 이것은 사용하는 사람의 자유
> urls
[1] "http://news.donga.com/search?query=bigkini&more=1&range=3&p=1"
[2] "http://news.donga.com/search?query=bigkini&more=1&range=3&p=16"
[3] "http://news.donga.com/search?query=bigkini&more=1&range=3&p=31"
[4] "http://news.donga.com/search?query=bigkini&more=1&range=3&p=46"
[5] "http://news.donga.com/search?query=bigkini&more=1&range=3&p=61"
[6] "http://news.donga.com/search?query=bigkini&more=1&range=3&p=76"
이렇게 해주게 되면 urls은 1:6까지의 범위를 가지는 url을 가지며 p의 값은 위와 같을 것이다
links <- NULL
links 또한 임시 변수
for(url in urls)
{
html <-read_html(url)
links <- c(links, html %>% html_nodes('.searchCont') %>% html_nodes('a') %>% html_attr('href') %>% unique())
# unique Function : double remove
links <- c(links, html %>% html_nodes('.searchList') %>% html_nodes('a') %>% html_attr('href') %>% unique())
}
이제 for문을 사용해서 html 코드 내에 있는 값에 접근을 해볼 것이다.
먼저 html_read로 6개의 값이 저장되어 있는 url을 html 코드로 가져온다.
그리고 나서 searchContent_class 명인것에 접근을 하고 , 그 하위 node인 클래스 a인 노드들에 접근하며 , 그 하위 노드의 attr = href 의 값을 가지는 노드를 추출한다 . 이때 unique를 사용함으로써 중복 방지를 한다 .
보게 되면 searchList 또한 같은 결과같을 가지게 되는데 , 그 이유는 searchContent가 구조적으로 보면 searchList의 상위 태그인데 , rvest에서 %>%로 접근할 때 오로지 클래스명을 기준으로 접근하기 때문에 , 상위 태그이건 , 하위 태그이건 사용자가 설정해준 class에 무조건 적인 접근을 하기 때문이다 .


links <- links[-grep("pdf",links)]
#가져온 값들 중 pdf가 포함되어진 links return 한다.
links
이렇게 가져온 links를 보게 되면 1...176개의 url 주소 값을 반환한 것을 알 수 있다.
여기서 궁금한 점이 생긴다.
내가 처음에 url 주소로 가지게 된 값은 6인데 , 어떻게 176까지 늘어난 건이냐 이다.
그 이유는 처음에 가져온 urls에는 단순히 내가 특정 게시글들의 목록들을 가져온 page이다.
그 page 내에서 나는 게시글의 목록들을 정제하는 과정을 거쳤으며 ,
그 과정에서 추출된 값들이 176개나 된다고 생각하면 쉽다 ^^
[1] "http://news.donga.com/3/all/20170202/82676578/1"
.....
[176] "http://news.donga.com/3/all/20140404/62255822/1"
txts <- NULL
txts 는 임시 변수
for(link in links) # get links
{
html <- read_html(link)
txts <- c(txts, html %>% html_nodes('.article_txt') %>% html_text())
# Geting main text
}

이제 마지막 작업이다 .
걸러진 urls 주소들에서 , article_txt의 text 값을 가져올 것이다.
여기서 가져오는 text의 값들도 176개가 될 것이다.
데이터 양이 너무 많아서 보여주는것은 생략하겠다.
이 부분은 예외적인데,
내가 가져온 값들을 csv 파일로 저장시킬 상황이 생길수도 있다.
write.csv("text","경로") 를 사용함으로써 그 경로에 text의 내용을 저장시킬 수 있다 .
이때 주의할 점은 경로 마지막에 내가 저장시킬 csv의 파일명과 확장자 명까지 적어주어야 한다.
write.csv(txts, "C://Users/user/Desktop/3학년2학기/데이터마이닝과통계/기말_HW2/scraping_text.csv")
# csv file Save


이런 형태로 176개의 칼럼들이 존재하게 된다 ...
'학부공부 > 데이터마이닝과통계' 카테고리의 다른 글
| API를 사용해서 실시간 버스 위치정보 시각화 (1) | 2018.11.15 |
|---|---|
| web_crawling + wordCloud (0) | 2018.11.15 |
| 나이키 사이트 크롤링 (0) | 2018.11.10 |
| 쿠팡 웹 크롤링 맛보기 (2) | 2018.11.01 |
| 웹 스크래핑 맛보기(Web Scraping) (0) | 2018.10.30 |
#IT #먹방 #전자기기 #일상
#개발 #일상