
데이터 모으기(4)학부공부/빅데이터기술_프로젝트2019. 5. 5. 04:35
Table of Contents
반응형
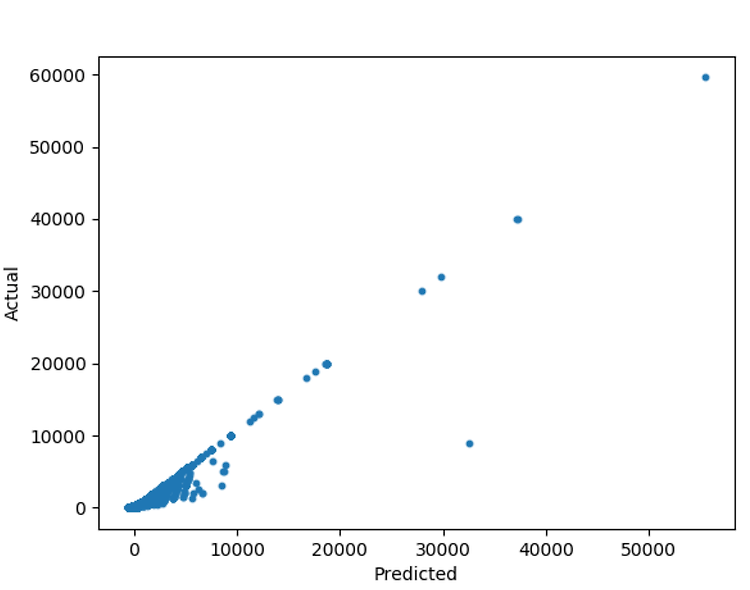
코드를 통해서 설명해 보겠다.
import requests
from bs4 import BeautifulSoup
일단 필요한 라이브러리는 위와같다.
# hrd를 해주는 이유는 웹에서 봇으로 생각을 해서 차단을 해서
hrd ={'User-Agent': 'Mozilla/5.0', 'referer' : 'https://www.metacritic.com/game/pc/devil-may-cry-5'}
봇으로 착각을 해서 header정보를 만들어 주었고 , referer은 크롤링하고자 하는 임시 페이지이다.
url = "https://www.metacritic.com/game/pc/devil-may-cry-5"
-->요청하고자 하는 주소
req = requests.get(url, headers=hrd)
-->requests할 때 크롤링할 주소와 header정보를 같이 포함시킨다.
soup = BeautifulSoup(req.content,'html.parser', from_encoding='utf-8')
-->BeautifulSoup를 사용할 때 , html.parser를 해고 인코딩도 해준다.
questions = soup.find("div", {"class":"metascore_w xlarge game positive"})
--> 웹 페이지를 보면 알겠지만, div라는 태그내에 class 명이 위와 같은 것이다.
a = questions.find("span", itemprop="ratingValue").text
print(a)
최종결과값 89
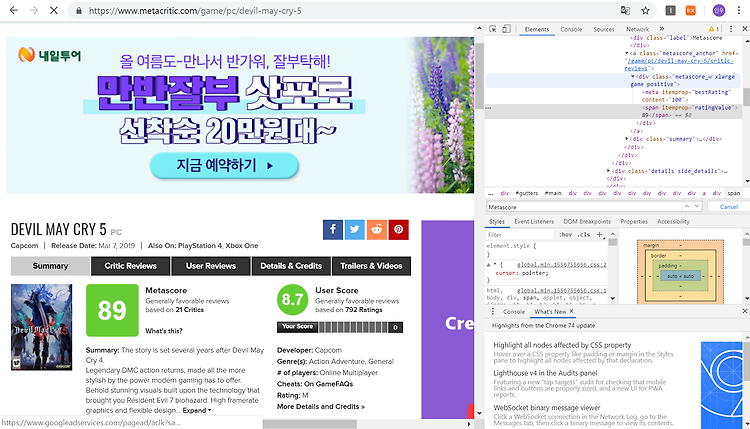
웹 구조는 다음과 같다.

위 그림처럼 "span" 태그내의 itemprop의 변수명으로 설정되어 있고 , 89점을 알려준다.
이제 크롤링 기본 작업은 끝났고
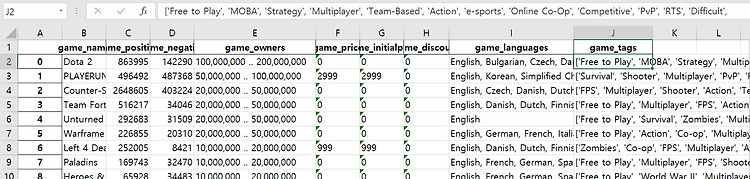
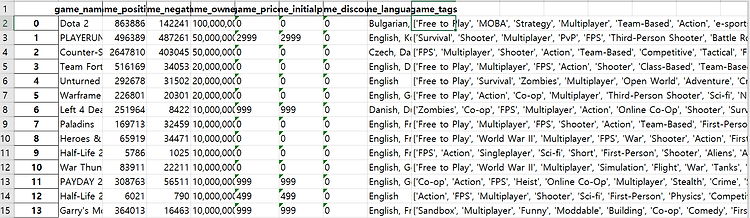
Excel에서 게임 이름을 가져와서 metacritic 점수와 user 점수를 뽑아와서 Excel에 저장시킨 다음
원본 게임 데이터에 합쳐주면 될것 같다 .
반응형
'학부공부 > 빅데이터기술_프로젝트' 카테고리의 다른 글
| game_price 예측(based on linear regression algorithm) (0) | 2019.05.19 |
|---|---|
| 프로젝트_중간점검(데이터정제과정) (0) | 2019.05.19 |
| HTTP Error 403: Forbidden (0) | 2019.05.05 |
| 데이터 모으기(3) (0) | 2019.05.01 |
| 데이터 모으기(2) (0) | 2019.04.29 |
@IT grow. :: IT grow.
#IT #먹방 #전자기기 #일상
#개발 #일상