
데이터 모으기(3)학부공부/빅데이터기술_프로젝트2019. 5. 1. 01:28
Table of Contents
반응형
기존에 구현에 놓았던 코드에서
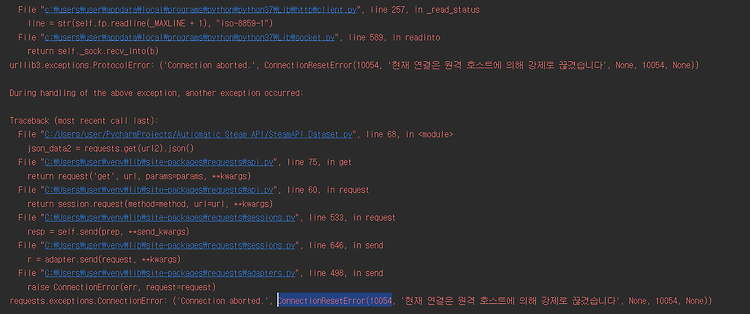
"원격 제어자에 의한 강제 종료"
로 골치아팠다.
나는 현재 데이터를 최대한 모아야 하는 상황이며
최적의 방법은 Steamspyapi에서 제공하는 api를 사용하여서
데이터를 모으는 방법이 최고라고 생각을 하고 진행을 하였다.
그래서 구현해 놓은 코드가 있었는데
Error가 나는것이다...
2틀정도 고민과 방법을 찾아보았다.
해결방법은 다음과 같다.
어차피 나의 목적은 최대한 많은 Steam게임의 데이터를 구해야 하며
최대한 빠르게 모아야 한다.
그래서 API에서 제공하는 all 이라는 requests가 있다.
이 all은 steamspyapi에서 제공하는 gamedata의 모든 것이다.
이 all을 사용하여서 requests를 보낸뒤
그 정보를 json형태로 저장을 했다.
그런 다음 json파일을 python에서 불러온 뒤
appid를 변수로 지정한 뒤
requests를 하는 것이다.
긴 말은 필요없고 코드를 통해서 확인해 본다.
import json
import urllib.parse
import requests
import pandas as pd
with open("C:/Users/user/Desktop/Steam_Data_Json/all.json") as json_file:
json_data = json.load(json_file)
a = [x for x in json_data]
print(len(a))
data_1 = []
main_api = "http://steamspy.com/api.php?request=appdetails&appid="
for Count in range(0,len(a)-29290):
url = main_api + a[Count]
json_data = requests.get(url).json()
# keys = [key for key in json_data]
keys2= [key for key in json_data['tags']]
print("game_appid : " + str(json_data['appid']))
print("================================")
print("game_name : " + json_data['name'])
print("================================")
print("game_positive : " + str(json_data['positive']))
print("================================")
print("game_negative : " + str(json_data['negative']))
print("================================")
print("game_owners : " + str(json_data['owners']))
print("================================")
print("game_price : " + str(json_data['price']))
print("================================")
print("game_initialprice : " + str(json_data['initialprice']))
print("================================")
print("game_discount : " + str(json_data['discount']))
print("================================")
print("game_languages : " + json_data['languages'])
print("================================")
print("game_tags : " + str(keys2))
print("================================END================================")
data_1.insert(Count ,
[json_data['name'],json_data['positive'],json_data['negative'],
json_data['owners'],json_data['price'],json_data['initialprice'],
json_data['discount'],json_data['languages'],keys2
])
# Dataframe 생성 및 csv 파일 생성
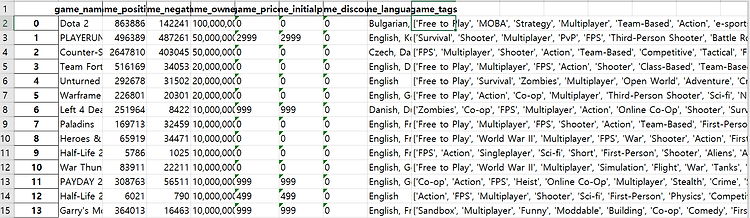
df = pd.DataFrame(data_1,columns=['game_name','game_positive','game_negative','game_owners','game_price','game_initialprice','game_discount','game_languages','game_tags'])
df.to_excel("C:/Users/user/Desktop/Data/Steam_game_Data.xlsx",sheet_name = 'Data')
결과값은 다음과 같다.
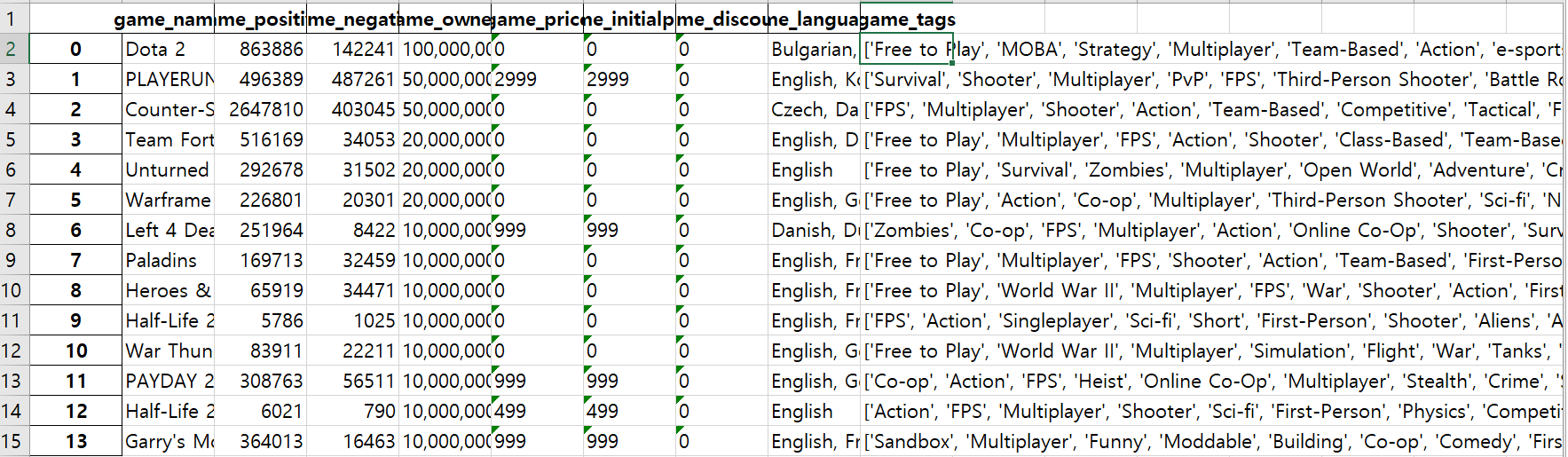
결과값은 전에 했던 것과 크게 달라보이는 것이 없다.
결론을 지어 보겠다.
for문을 통해서 다중 requests를 했을 때
"원격 제어자의 의한 강제 종료"
에러가 났다.
해결방안으로
all 변수를 통해서 모든 데이터의 결과값을 requests한 뒤 json형태로 다운받았다.
그런 다음 python에서 이 json에서 appid만 빼온뒤에
appid를 기반으로 requests요청을 했다.
나의 개인적인 생각일 수 있겠지만
체감상 다중 requests 보다
json에서 특정 데이터값을 변수로 저장 시켜 놓은 뒤
이 변수로 requests를 하니까 가져오는 데이터의 속도가 더 빨랐다.
당연한 거일 수도 있겠지만, 왜 이생각을 못했을까 싶다.
이제 이 코드를 기반으로 데이터르 모은 뒤에
Metacritic의 점수도 가져오고 싶다.
반응형
'학부공부 > 빅데이터기술_프로젝트' 카테고리의 다른 글
| 데이터 모으기(4) (0) | 2019.05.05 |
|---|---|
| HTTP Error 403: Forbidden (0) | 2019.05.05 |
| 데이터 모으기(2) (0) | 2019.04.29 |
| 필요한 데이터 모으기(1) (0) | 2019.04.27 |
| machine_learning_project (0) | 2019.04.27 |
@IT grow. :: IT grow.
#IT #먹방 #전자기기 #일상
#개발 #일상