
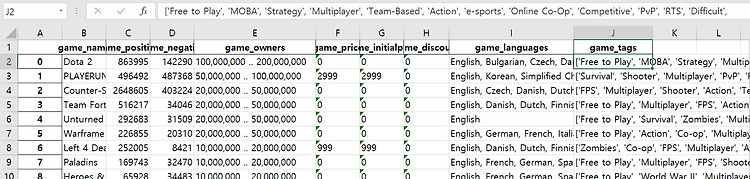
201303017_김인우_빅데이터기술 중간발표자료 목차 1. 데이터셋 설명 2. 데이터 분석 3. 분석 진행도 4. 앞으로 해야 할 작업 데이터셋 설명 è 데이터셋의 head(10)까지만 보면 위와같다. 칼럼들은 다음과 같다. è Game_name(게임이름) game_positive(게임의 긍정적인 평가 점수) game_negative(게임의 부정적인 평가 점수) game_owners(게임 소유한 사람 수) game_price(게임 현재 가격) game_initialprice(게임 초기 가격) game_discount(게임 할인 가격) game_languages(게임이 지원하는 언어) game_tags(게임 태그들) 위 데이터셋은 Steamspiapi를 이용해서 python으로 데이터를 모았으며, Ste..
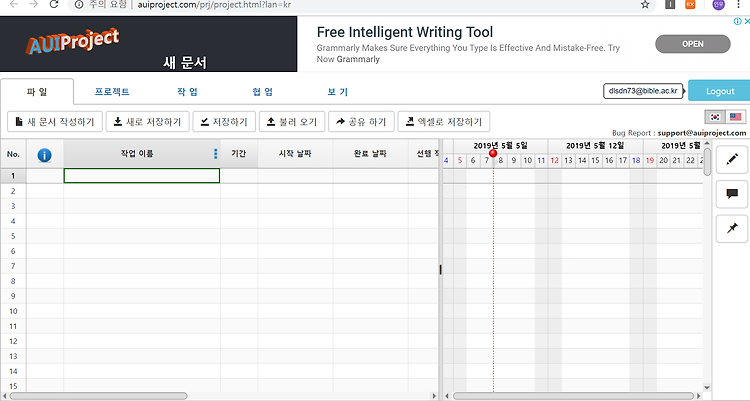
간트차트 만들 상황이 생겨서 알아보다가 괜찮은 사이트를 알게 되어서 설명해 본다. http://auiproject.com/prj/project.html?lan=kr 에이유아이 프로젝트( AUIProject ) 간트차트 기반 무료 프로젝트 관리 - 공유, 협업, 엑셀 저장 등 가능 www.auiproject.com 에이유아이 프로젝트라는 사이트인데 보통 엑셀을 쓰거나 프로그램을 사용하는 경우가 있다. 나는 번거롭게 느껴져서 위 사이트가 그런면에서 좋다고 생각한다. 사이트를 들어가면 다음화면처럼 새 문서 작성하기를 한다 작업이름과 기간,시작 날짜,완료 날짜, 선행작업 등 많은 기능을 작성할 수 있으며 작업도를 숫자로 입력하게 되면 오른쪽에 막내차트로 표시가 된다. 대충 입력을 했으면 엑셀로 저장해서 확인할 ..
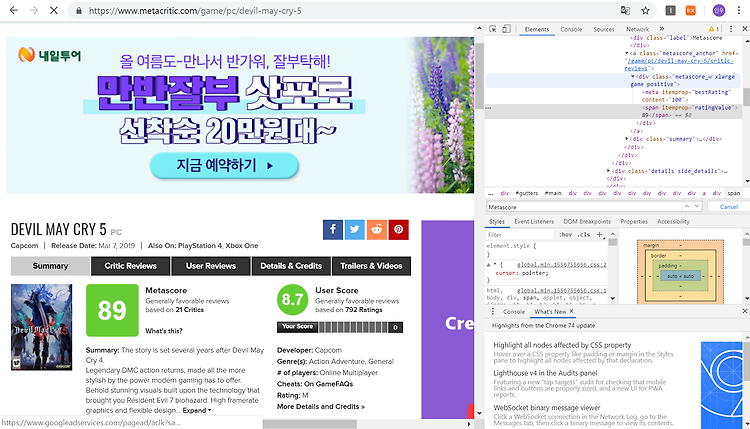
코드를 통해서 설명해 보겠다. import requests from bs4 import BeautifulSoup 일단 필요한 라이브러리는 위와같다. # hrd를 해주는 이유는 웹에서 봇으로 생각을 해서 차단을 해서 hrd ={'User-Agent': 'Mozilla/5.0', 'referer' : 'https://www.metacritic.com/game/pc/devil-may-cry-5'} 봇으로 착각을 해서 header정보를 만들어 주었고 , referer은 크롤링하고자 하는 임시 페이지이다. url = "https://www.metacritic.com/game/pc/devil-may-cry-5" -->요청하고자 하는 주소 req = requests.get(url, headers=hrd) -->req..
Python에서 requests library를 사용해서 크롤링을 할려고 하였다. 그런데 , 제목과 같은 오류가 났다. https://medium.com/@speedforcerun/python-crawler-http-error-403-forbidden-1623ae9ba0f [Python][Crawler]“HTTP Error 403: Forbidden” Using urllib.request.urlopen() to open a website when crawling, and encounters “HTTP Error 403: Forbidden”. It possibly due to the server… medium.com 위를 참고하여서 해결하였다. 문제는 웹에서 봇으로 착각을 하여서 차단한다는 것이다. 그래서..
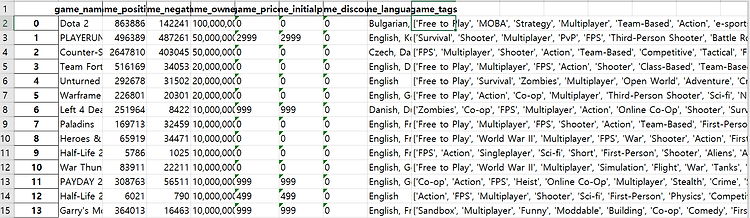
기존에 구현에 놓았던 코드에서 "원격 제어자에 의한 강제 종료" 로 골치아팠다. 나는 현재 데이터를 최대한 모아야 하는 상황이며 최적의 방법은 Steamspyapi에서 제공하는 api를 사용하여서 데이터를 모으는 방법이 최고라고 생각을 하고 진행을 하였다. 그래서 구현해 놓은 코드가 있었는데 Error가 나는것이다... 2틀정도 고민과 방법을 찾아보았다. 해결방법은 다음과 같다. 어차피 나의 목적은 최대한 많은 Steam게임의 데이터를 구해야 하며 최대한 빠르게 모아야 한다. 그래서 API에서 제공하는 all 이라는 requests가 있다. 이 all은 steamspyapi에서 제공하는 gamedata의 모든 것이다. 이 all을 사용하여서 requests를 보낸뒤 그 정보를 json형태로 저장을 했다...
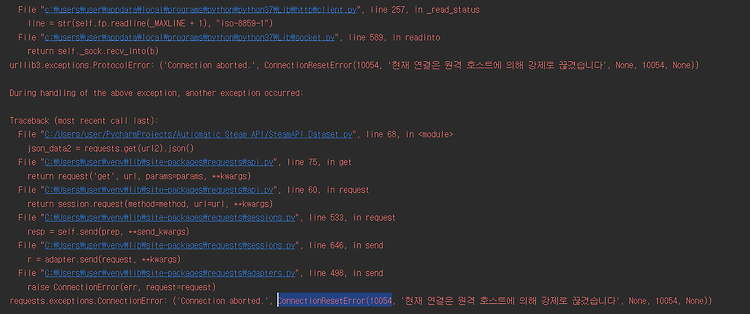
저번에 구현해 놓은 코드를 기반으로 이번에는 조금 더 많은 데이터를 가져오기 위해서 받아오는 데이터의 양을 늘려보았다. 원래 100개 안팎인 데이터에서 1000개 단위의 데이터로 늘렸다. Error가 뜬다. 내 생각에는 중간에 네트워크의 변경이 있거나 SteamspyAPI에서 호스트를 끊어버리거나 인데 아직 해결을 못했다. 시간이 없기 때문에 빨리 해결해야 할 듯하다. 먼저 생각해 본 해결방안은 다음과 같다. 1.소수의 데이터는 문제없이 돌아간다. 2.이 내용을 기반으로 1000개의 데이터씩 쪼개서 데이터를 가져온뒤 한꺼번에 데이터를 취합한다. 꾸준히 해봐야겠다.