
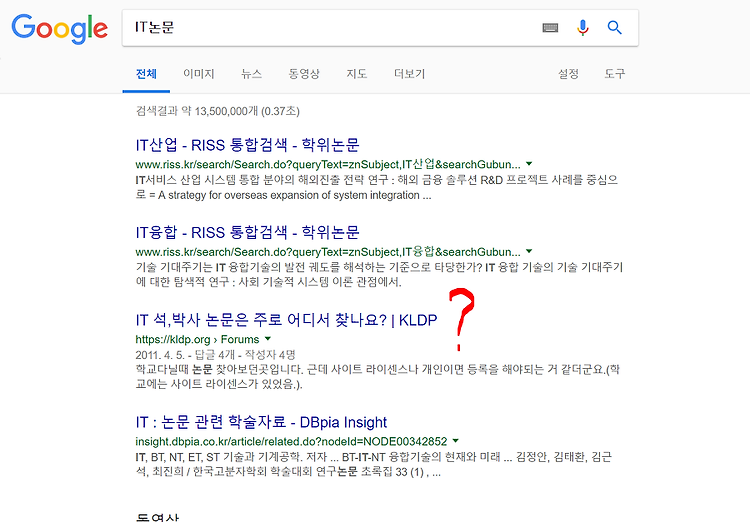
오늘은 구글에서 논문 저자와 메인제목과 메인내용을 가져와 볼 것이다. 먼저 , 구글에 IT논문을 쳐서 , 검색기록들을 분석해 본다 . 그런데 , 검색을 하다보니 , 내가 찾고자 하는 정보와 관련없는 내용들이 너무 많았다…. 나는 논문관련된 정보만 추출하고 싶었다. 그래서 구글말고 논문 전문 사이트를 이용하기로 하였다. 그래서 이용하게된 DBpia 사이트 : http://www.dbpia.co.kr/SearchResult/TopSearch?isFullText=0&searchAll=IT 이 사이트는 논문의 종류가 굉장히 다양하고 정보가 많았다. 이 사이트를 이용해서 분석하기 전에 앞서 , 구글의 페이지 이동에 관해서 알아보았다. 1번째 페이지 : https://www.google.com/search?q=%E..
오늘은 웹 크롤링한 데이터를 csv ( 엑셀 ) 형태로 저장을 시키고 , 저장시킨 엑셀 파일을 정제시키고 , 데이터를 가져와서 시각화 해보는 작업을 해 볼 것이다. 내가 크롤링할 사이트는 https://www.greenclimate.fund/home 이며 영어로 된 뉴스 사이트다. 코드를 보면서 분서해 보자 . 크게 rvest 패키지와 XML패키지가 필요하며 시각화 할 때 필요한 wordcloud2 패키지가 필요하다 . 문서를 다루는 tm패키지가 보통 깔려있는데 , 나는 없어서 깔아 주었다. library(rvest)library(XML) # 크롤링을 해오기 위해서 필요한 라이브러리들 install.packages("tm")install.packages("wordcloud2") # 필요한 패키지들 #wo..
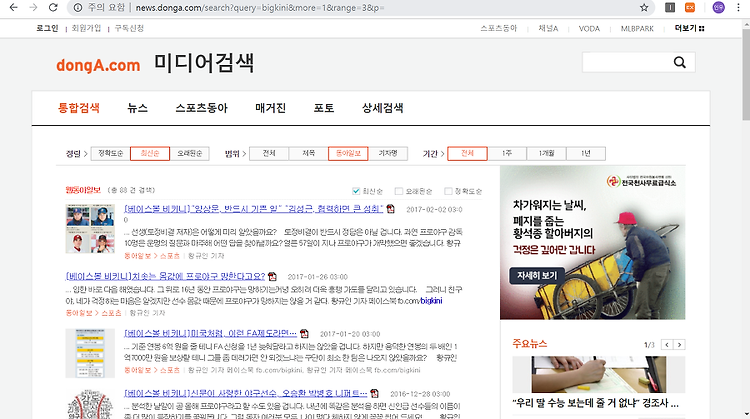
동아 신문 사이트를 스크랩핑해보는 시간을 가져볼 것이다. 소스 코드는 다음과 같다. library(rvest)library(dplyr)우선 기본적으로 rvest 와 dplyr 패키지를 로딩시켜준다. url % html_nodes('a') %>% html_attr('href') %>% unique()) }이제 for문을 사용해서 html 코드 내에 있는 값에 접근을 해볼 것이다.먼저 html_read로 6개의 값이 저장되어 있는 url을 html 코드로 가져온다.그리고 나서 searchContent_class 명인것에 접근을 하고 , 그 하위 node인 클래스 a인 노드들에 접근하며 , 그 하위 노드의 attr = href 의 값을 가지는 노드를 추출한다 . 이때 unique를 사용함으로써 중복 방지를 한..
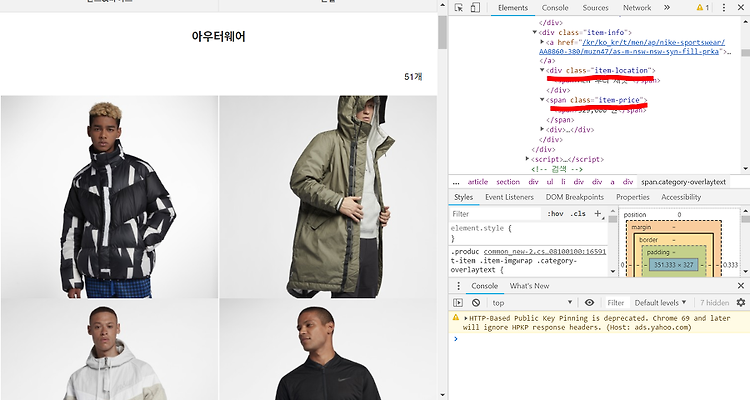
이번에는 나이키(nike) 사이트를 크롤링 해 볼 것이다. 내가 가져올 값들은 아우터 부분의 아우터 이름명과 가격이다. R을 실행해서 , 크롤링에 필요한 , xml과 rvest 패키지를 로딩시켜 준다 . library(rvest)library(XML) url url에 내가 크롤링 하고자 하는 사이트의 url 값을 넣어준다. doc 이 url을 html으로써 읽어 온다 이제 html에 접근하기 위해서 nike 사이트를 접속해 주면 되는데 , Nike 사이트는 다음과 같은 구조를 가졌다. 다음을 보게 되면 아우터의 class 명은 item-location으로 지정되어 있는 것을 확인할 수 있었다. # 옷 이름 가져오기 부분 prod_name % html_nodes(".item-title") %>% html_..