
오늘은 구글에서 논문 저자와 메인제목과 메인내용을 가져와 볼 것이다.
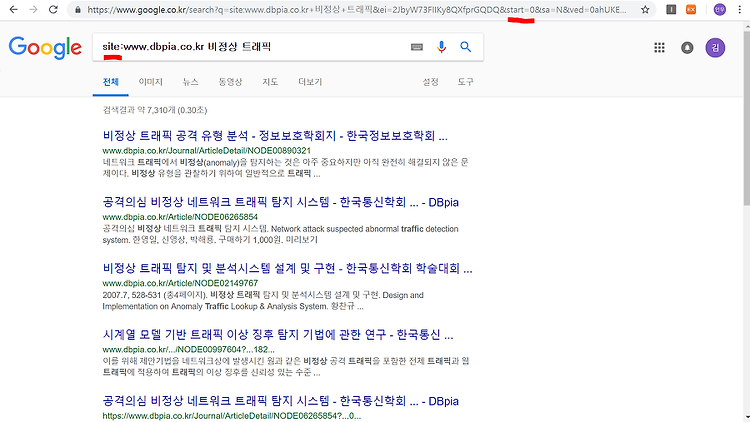
먼저 , 구글에 IT논문을 쳐서 , 검색기록들을 분석해 본다 .

그런데 , 검색을 하다보니 , 내가 찾고자 하는 정보와 관련없는 내용들이 너무 많았다….
나는 논문관련된 정보만 추출하고 싶었다.
그래서 구글말고 논문 전문 사이트를 이용하기로 하였다.
그래서 이용하게된 DBpia 사이트 :
http://www.dbpia.co.kr/SearchResult/TopSearch?isFullText=0&searchAll=IT
이 사이트는 논문의 종류가 굉장히 다양하고 정보가 많았다.
이 사이트를 이용해서 분석하기 전에 앞서 ,
구글의 페이지 이동에 관해서 알아보았다.
1번째 페이지 :
3번째 페이지 :
4번째 페이지 :
구글은 페이지 이동에 사용하는 변수를 start로 주었고 , 이 값의 증가는 10이였다.
보통 페이지 이동할 때 page = 숫자 , 이런 식으로 설정되어있는데, 구글은 이상하게 증가값이 10이였다..
다시 본론으로 들어와서

사이트에 들어가서 IT를 입력해 주고 결과값들을 보면 IT와 관련된 논문들이 나오는 것을 알 수 있었다 .
그런데 이 사이트는 논문을 사고 파는 그런곳같았다.
아무튼 , 이제 이 사이트에서 페이지의 이동이 어떻게 되는지 알아 보자 .
검색창에 IT를 입력했을 때 변하는 사이트의 주소는 다음과 같다.
http://www.dbpia.co.kr/SearchResult/TopSearch?isFullText=0&searchAll=IT
searchAll 변수를 사용해서 IT를 검색하는 것을 알 수 있다.
첫 번째 페이지의 주소는 다음과 같다.
http://www.dbpia.co.kr/SearchResult/Search?q=%28%5BIT%C2%A7coldb%C2%A72%C2%A751%C2%A73%5D%29&searchWord=%EC%A0%84%EC%B2%B4%3D%5E%24IT%5E*&Collection=0&nSort=1&nSorttype=desc&Page=1&nPagesize=20&searchAll=IT&Multimedia=0&isFullText=0&Collection=0&SearchMethod=0&SrvYN=&PublishDate=&PublishSttDate=&PublishEndDate=
두번째 페이지의 주소는 다음과 같다.
세 번째 페이지는 다음과 같다 .
이를 통해서 우리는 page 라는 변수를 통해서 페이지의 이동이 되는 것을 알 수 있다.
그래서 생각해 볼 수 있는 것이
Page를 변수로 두기 위해서 Page를 기준으로 앞 뒤 url을 각각 따로 저장시키는 것이다.
들어가기 전에 앞서서 이 작업을 수행하기 위해서는 몇 가지 패키지들이 필요하다.
library(rvest)
library(xml2)
# 크롤링을 해오기 위해서 필요한 라이브러리들
install.packages("tm")
install.packages("wordcloud2")
install.packages("NLP")
# 필요한 패키지들
#wordcloud2를 구동하기 위한 라이브러리들
library(devtools)
library(htmlwidgets)
library(htmltools)
library(jsonlite)
library(yaml)
library(base64enc)
library(tm)
library(NLP)
library(wordcloud2)
First_url <- "http://www.dbpia.co.kr/SearchResult/Search?q=%28%5BIT%C2%A7coldb%C2%A72%C2%A751%C2%A73%5D%29&searchWord=%EC%A0%84%EC%B2%B4%3D%5E%24IT%5E*&Collection=0&nSort=1&nSorttype=desc&Page="
# First_url : Page라는 페이지의 이동 변수를 기준으로 앞 주소
second_url <- "&nPagesize=20&searchAll=IT&Multimedia=0&isFullText=0&Collection=0&SearchMethod=0&SrvYN=&PublishDate=&PublishSttDate=&PublishEndDate="
# second_url : Page 라는 페이지의 이동 변수를 기준으로 뒤 주소
urls <- NULL
for(x in 1:5)
{
urls[x] <- paste0(First_url,as.character(x),second_url)
}
è 이제 앞뒤로 따로 만들어준 url을 paste를 사용해서 하나의 주소로 만들어 줄 것인데 , 이때 for문을 사용해서 1~5페이지의 url주소를 담는 urls변수를 만들어서 싹 다 저장시켜 준다.
links <- NULL
이제 가져온 주소들에서 본문기사로 넘어가는 주소 url를 가져올 것이다.
for(url in urls)
{
#에러 방지
download.file(url, destfile = "scrapedpage.html", quiet = TRUE)
html <- read_html("scrapedpage.html")
links <- c(links, html %>% html_nodes(".titleWarp") %>% html_nodes('a') %>% html_attr('href') %>% unique())
# titleWarp는 메인 기사 본문을 의미한다.
# 찾고자 하는 부분이 class일 경우 앞에 . 을 붙이고 , id이면 #을 붇인다.
# 가져오고자 하는 클래스명에 띄어쓰기가 있을 경우 띄어쓰기 있는 부분에 .을 사용하면 된다.
# class = titleWarp : main article
}
그런데 , 여기서 저장된 links를 보게 되면 13 , 14 는 Journal인데 , 15는 bookrail 의 주소를 가지는것을 확인할 수 있다 . 그래서 , 정제할 필요가 있다고 느낀다.
[13] "/Journal/ArticleDetail/NODE02152540?TotalCount=1544220&Seq=13&q=(%5BIT%C2%A7coldb%C2%A72%C2%A751%C2%A73%5D)&searchWord=%EC%A0%84%EC%B2%B4%3D%5E%24IT%5E*&Multimedia=0&isIdentifyAuthor=0&Collection=0&SearchAll=IT&isFullText=0&specificParam=0&SearchMethod=0&Sort=1&SortType=desc&Page=1&PageSize=20" [14] "/Journal/ArticleDetail/NODE02239356?TotalCount=1544220&Seq=14&q=(%5BIT%C2%A7coldb%C2%A72%C2%A751%C2%A73%5D)&searchWord=%EC%A0%84%EC%B2%B4%3D%5E%24IT%5E*&Multimedia=0&isIdentifyAuthor=0&Collection=0&SearchAll=IT&isFullText=0&specificParam=0&SearchMethod=0&Sort=1&SortType=desc&Page=1&PageSize=20" [15] "http://www.bookrail.co.kr/view/product_detail.asp?co_id=N1004016"
Grep를 사용해서 journal이 존재하는 url만 따로 num_GCFurl 변수에 저장시킨다.
num_GCFurl <- grep("Journal/",links)
결과값
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35[34] 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68[67] 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100
저장이 잘 들어가졌다 .
이제 links_green 이라는 변수에 걸러진 url 주소들을 저장시켜 줄 것이다.
links_green <- NULL
# 각 번호에 해당되는 links의 url 을 links_green에 담는다
# 이 말은 즉슨 , green 기사 url만 links_green에 저장시키는 것이다.
for(num in num_GCFurl)
{
links_green <- c(links_green, links[num])
}
Links_green 결과값은 다음과 같다 .
너무 많아서 마지막만 출력해 본다
[98] "/Journal/ArticleDetail/NODE06357343?TotalCount=1544220&Seq=100&q=(%5BIT%C2%A7coldb%C2%A72%C2%A751%C2%A73%5D)&searchWord=%EC%A0%84%EC%B2%B4%3D%5E%24IT%5E*&Multimedia=0&isIdentifyAuthor=0&Collection=0&SearchAll=IT&isFullText=0&specificParam=0&SearchMethod=0&Sort=1&Sort Type=desc&Page=5&PageSize=20"
Type=desc&Page=5&PageSize=20"
그런데 , 여기서 또하나 이상한게 있다.
추출되거 걸러진 주소값을 들어가 보면 서버에서 거절을 한다…


그래서 보니까 주소값이 이상하긴 하다… 보통 메인주소의 하위로 가면서 타고 들어가게 되는데 , 메인 페이지의 주소값이 없었다.
다음과 같이 메인주소를 걸러진 url에 순서대로 대입해 주었다.
links_dbpia <- NULL
links_dbpia <- paste0("http://www.dbpia.co.kr",links_green[1:98])
이제 준비 작업은 끝났다.
본격적으로 크롤링을 해보자 . 이 부분은 코드를 통해서 설명해 보겠다.
main_article <- NULL # main_article , 본문기사
è 메인 문의 기사 제목을 크롤링할 부분
write_name <- NULL # wirte_name , 저자
è 논문에 참여 or 쓴 사람들
Filter_name <- NULL # Maping group user , 논문제작을 같이한 저자끼리 묶기 위해
è 논문제작에 같이 참여한 사람들을 묶어 주기 위한 변수
small_imformation <- NULL # small_imformation , 소제목과 발간일
è 소제목과 발간일 추출할 부분
다음은 위에 설정한 부분들을 토대로 크롤링 하는 부분이다.
크롤링을 해 올 때 변수 하나를 설정해 주게된다.
그 변수에 차곡차곡 값들이 쌓이게 된다.
그런데 , write_name은 저자이다.
논문을 쓸 때는 보통 여러명에서 작업하거나 , 혼자하기도 하는데
이것들을 논문에 따라서 묶어줄 필요를 느꼈다.
이렇게 안해주면 논문에 따른 저자들이 제대로 출력이 안될 것이며 , 보기에도 안이쁘다
그래서 나는 다음과 같은 Function 기능을 추가했다.
plus_Str <- function(str,sep=",")
{
paste(str,collapse = sep)
}
è 이 function은 문자열 ( 여기서는 이름들 ) 을 받고 sep 로써 “,” 을 줌으로써 구별을 하고
è paste로써 문자들을 하나의 열로 만드는 Function
그리고 여기서 a는 필터링 된 저자들을 저장하기 위한 주소값이라고 생각하면 된다 .
A의 값이 0 부터 1씩 증가하면서 차곡차곡 쌓일 것이다.
a = 0
for문을 돌려서 접근하기 전에 홈페이지 들어가서 우리가 접근하고자 하는 html의 구조를 확인해 보아야 한다.

è 메인기사의 class 명은 book_info라는 것을 알 수 있으며 그 하위 태그로 <h3> 감싸진 것을 알 수 있다.

è 저자의 클래스명은 write_info 로 되어 있으며 , 그 하위 태그 span내에 noticen 클래스로 묶여 있는 것을 알 수 있다.
è 저자들은 특이 했던게 , 저자가 2명이상일 경우에는 span 태그 하위에 <a>태그로써 또 하나의 저자를 만들어 놨다…
è 아무튼 noticen 클래스로 접근하면 된다

è 위에는 논문의 간략한 초록이다. 이 내용을 같이 크롤링 할려고 했지만 컴퓨터가 감당을 못해서 크롤링하진 않았따… 아무튼 클래스명은 Con_txt다

è 마지막으로 발간일과 간략한 내용을 담고 있는 dt태그이다. 상위 클래스는 Book_info 이며 그 하위 <dl>태그 내에 다시 하위 태그 <dt>로 접근하면 될 것이다.
이제 다음 for문을 돌려서 크롤링이 제대로 작동하는지 확인해 보자
for(link in links_dbpia)
{
# download.file(link, destfile = "scrapedpage.html" , quite=TRUE)
# 추후 예방을 위한 download.file은 속도가 약간 느려서 이번에는 그냥 read_html로 읽어와 보겠다.
html <- read_html(link)
è 주소값을 읽어온다 ( html 파일로 )
a <-a + 1
è 초기값 a에 1이 더해진다.
main_article <- c(main_article, html %>% html_nodes(".book_info") %>% html_nodes("h3") %>% html_text())
write_name <- c(write_name, html %>% html_nodes(".writeInfo") %>% html_nodes(".noticen") %>% html_text())
Filter_name[a] <-plus_Str(write_name,sep=",")
#small_main_text <- c(small_main_text, html %>% html_nodes(".con_txt") %>% html_text())
#small_imformation <- c(small_imformation, html %>% html_nodes(".book_info") %>% html_node("dl") %>% html_nodes("dt") %>% html_text())
}
Main_article 의 결과값 마지막 부분만 출력해 본다. 데이터가 많아서 이다. 칼럼수는 97개
"정당성은 빌려올 수 있는가"
Write_name 의 결과값 마지막 부분만 출력해 본다 . 데이터가 많다.
[145] "남정우" "이해영" "김영옥" "김현미" "김서형" "김동수" "이민주" "박범주" "이해준"
[154] "신완선" "이관후"
앞에서도 말했지만 , 저자들의 이름들이 하나의 이름으로써 write_name에 저장되어 있다 .
이 이름들을 논문에 따라서 같이 작업한 이름끼리 묶어줄 필요가 있다고 생각이 든다.
Filter_name의 결과값을 보면 , 다음처럼 첫 칼럼에 “”로 들어가져 있다.
[1] ""
그래서 Filter_name의 첫 칼럼을 지워준다.
Filter_name <- Filter_name[-1]
그런데 , 한가지 문제가 더 있다. 다음은 21번째 칼럼을 가져온 것인데 , 이름들이 이어져 있다.
앞에서 말한 문제가 이것이다.
크롤링한 이름들을 하나의 변수에 차곡차곡 쌓는 것인데 , 이것은 보기에 좋을 수 있지만 , 내가 원하는 형태가 아니다.
[21] "최혜민,김성룡,최승년,김희영,조준서,김현화,황은희,이성주,조남영,김병선,조찬우,류권홍,송희영,김도년,이다혜,권오걸,김원준,지형주,곽관훈,문태수,강성배,최상민,문태수,정현,구본근,이주희,곽기영,홍문경,Shoko Tonai,김도승,정대율,노미진,장형유"
그래서 나는 원래에 있는 Filter_name 의 똑 같은 값과 형태를 가지는
Filter_real_name 변수를 또하나 만들어 주었다.
Filter_real_name <- NULL
Filter_real_name <- Filter_name[1:97]
이 Filter_real_name은 논문에 매치되는 저자들을 묶어 놓은 저자들이 저장될 변수이다.
먼저 for문을 만들어서 돌려주기 전에 , 내가 생각한 것이 맞게 들어가는지 확인해주는 작업이 필요하다
Filter_real_name[2] <- gsub(Filter_name[1],"",Filter_real_name[2])
è 이것은 두번째 칼럼에 첫번째 칼럼에 있는 값이 존재한다면 공백으로 처리하겠다 라는 것을 의미한다
è 실행시켜 보자
실행시켜 보면 결과값은 다음과 같다.
[2] ",김성룡"
이렇게 함으로써 2번째 논문에 해당하는 저자는 “ 김성룡 “ 이 사람으로 추려진다.
알맞게 들어감을 확인했으므로 for문을 만들어서 작업해 준다.
for(number in 3:97)
{
Filter_real_name[number] <- gsub(Filter_name[number-1],"",Filter_real_name[number])
}
2번째 칼럼은 처리했으므로 , 3번째 칼럼부터 진행한다.
결과값은 다음과 같다.
[94] ",김동수" ",이민주" ",박범주,이해준,신완선"
[97] ",이관후"
위 결과값은 94번째 논문의 저자는 “김동수” , 95번째 논문의 저자는 “이민주” 96번째 논문의 저자는 “박범주,이해준,신완선” 97번째 논문의 저자는 “이관후”라는 것이 확인이 된다.
이제 발간일을 저장시켜놓은 small_imformation의 결과값을 보자, 마지막 부분인데
정말 이쁘지 않게 가져왔다. 이부분도 정제할 필요를 느낀다.
[193] "\r\n 정치사상연구 제21집 1호, 2015.5, 89-114 (27 pages)\r\n "
[194] "\r\n \r\n \r\n "
다음을 통해서 \r , \n , “ “ 을 제거시킨다.
small_imformation <- gsub("\r","",small_imformation)
small_imformation <- gsub("\n","",small_imformation)
small_imformation <- gsub(" ","",small_imformation)
이제 다시 small_imformation의 결과값을 확인해 본다
[193] "정치사상연구제21집1호,2015.5,89-114(27pages)"
[194] ""
마지막 부분인데 , 이쁘게 되긴했는데 , 2칼럼당 하나의 정보가 들어가있다..
왜그런지는 모르겠지만 , 다시 정제해줄 필요를 느낀다.
먼저 , 다음 코드를 통해서 두번째 칼럼을 제거해 본다
small_imformation <- small_imformation[-2]
결과값은 다음과 같다.
[2] "IT와법연구제5집,2011.2,319-346(28pages)"
[3] ""
R에서는 칼럼을 제거하면 다음 값이 자동으로 비워진 곳을 채운다…
이것 때문에 고생 엄청했다
다시 3번째 칼럼을 제거해 보자
small_imformation <- small_imformation[-3]
[3] "KoreaBusinessReview제18권제3호,2014.8,213-245(33pages)"
[4] ""
내 생각대로 4번째 있던 값이 3번째 칼럼으로 채워진다…
마지막으로 4번째를 지워보자.
small_imformation <- small_imformation[-4]
결과값은 다음과 같다.
[4] "KoreaBusinessReview제16권제1호,2012.2,99-117(19pages)"
[5] ""
이제 먼가 감이 온다.
내가 지워준 칼럼을 기준으로 자동으로 값이 채워지기 때문에 , for문을 통해서 지워볼수 있을 것 같다.
for(user in 5:190){
small_imformation <- small_imformation[-user]
}
è 우리는 4번째 칼럼까지 지웠다. 이제 5번째 칼럼을 지울 것인데 , 5번째 칼럼을 지웠다고 가정을 하면 6번째 칼럼에 있던 값이 지워진 5번째 칼럼에 들어갈 것이다. 결론적으로 내가 지워야 할 칼럼들은 5부터 시작해서 1씩 증가하고 , 190까지 지워주면 될 것이다 라는 결론이 나온다.
이제 for문의 결과값을 확인해 보면 다음과 같다.
[96] "經營科學第32卷第2號,2015.6,1-14(14pages)"
[97] "정치사상연구제21집1호,2015.5,89-114(27pages)"
마지막 부분인데 , 97 칼럼까지 잘 들어간 것을 확인할 수 있다.
이때 칼럼 개수도 확인해야 한다. 왜냐하면 내가 가져온 메인본문의 칼럼수는 97 이였는데 , 이것과 어긋나면 무엇인가 잘못 추출된 것이기 때문이다.
본문기사, 저자 , 소제목+발간일을 크롤링해서 정제시켰다.
이제 이 것들을 하나의 새로운 데이터 프레임으로 만들어서 이쁘게 만들어 보겠다.
dt <- data.frame(본문기사=main_article,저자=Filter_real_name,발간일=small_imformation)
만든 데이터 프레임을 보면 다음과 같은데 , 너무 안이쁘다 .
그래서 이쁘게 해보겠다.

다음의 명령어들을 통해서 각 칼럼들은 왼쪽 정렬을 시킬 것이다
dt$본문기사 <- format(dt$본문기사,justify = 'left')
dt$저자 <- format(dt$저자,justify = 'left')
dt$발간일 <- format(dt$발간일,justify = 'left')
결과값은 다음과 같다.

나름 이쁘게 정리 되었다 ^^
이렇게 끝내기는 먼 가 아쉽다.
그래서 나는 csv파일로 저장과 불러오기 , 정제 , 시각화를 해볼 것이다
다음 명령어들을 통해서 csv 파일로 각각 별도의 파일로 만들어 준다.
write.csv(main_article,"C://Users/user/Desktop/3학년2학기/데이터마이닝과통계/기말_HW2/MainArticle.csv")
write.csv(Filter_real_name,"C://Users/user/Desktop/3학년2학기/데이터마이닝과통계/기말_HW2/Filter_real_name.csv")
write.csv(small_imformation,"C://Users/user/Desktop/3학년2학기/데이터마이닝과통계/기말_HW2/small_imformation.csv")
먼저 본문기사를 다뤄보겠다.
상대경로를 통해서 경로를 가져올 것인데 , 이때 주의해야하 점은 아까 저장시켜놓은 각각의 파일은 USer/user/Document 에 저장되어 있어야 한다 . 이상하게도 상대경로가 여기로 저장되어 있었다 … 한참 해맸다…
news_path <- paste0(getwd(),"/MainArticle.csv")
modi_txt <- readLines(news_path)
이렇게 함으로써 파일을 읽어 오는 것 까지 되었다.
본문기사에 불필요한 기호들은 제거해 준다.
modi_txt <- gsub("<U.00A0>"," ",modi_txt)
modi_txt <- gsub("<U.2013>","-",modi_txt)
각각 하이픈과 공백은 지워줄 것이다.
Txt의 총 line수를 구하고 , 총 line수 만큼 1씩 증가하는 벡터를 생성한다
last_number_of_lines <- length(readLines(news_path))
line_numbers <- seq(1,last_number_of_lines,1)
이제 line별 마다 번호를 매기고 , 하나의 data.frame으로 만들어 준다.
doc_ids <- line_numbers
df <- data.frame(doc_id = doc_ids,text = modi_txt, stringsAsFactors = FALSE)
만들어준 df의 Dataframesource를 확인해 본다 .
modi_data <- Corpus(DataframeSource(df))
이제 언어를 설정해 줄 것인데 , 한국어로 되어있기 때문에 , 다음처럼 설정해 준다.
Sys.setlocale(category = "LC_ALL",locale ="korean")
이제 메인기사의 데이터들을 정제해 볼 것이다.
공백이 2개 이상인 것을 1개로 만든다.
modi_data <- tm_map(modi_data,stripWhitespace)
숫자는 필요없다. 제거해 준다
modi_data <- tm_map(modi_data,removeNumbers)
구둣점들도 제거해 준다.
modi_data <- tm_map(modi_data,removePunctuation)
정제가 끝나면 , 이 line별들도 되어 있는 것을 matrix형태로 만들어 준다
tdm_modi <- TermDocumentMatrix(modi_data)
matrix를 format시켜 준다
TDM1 <- as.matrix((tdm_modi))
이제 모든 단어들의 빈도수를 체크해 보자
v=sort(rowSums(TDM1), decreasing = TRUE)
profile = data.frame(word=names(v),freq=v)
실행시켜보면 다음과 같다.
head(profile,10)
word freq<ec>뿰援<ac> <ec>뿰援<ac> 15
愿\u0080<ed>븳 愿\u0080<ed>븳 14
諛<8f> 諛<8f> 12
誘몄튂<eb>뒗 誘몄튂<eb>뒗 10
<eb><8c>\u0080<ed>븳 <eb><8c>\u0080<ed>븳 8
洹<b8> 洹<b8> 6
<ec>쐞<ed>븳 <ec>쐞<ed>븳 6
<ec>쁺<ed>뼢 <ec>쁺<ed>뼢 6
遺꾩꽍 遺꾩꽍 5
怨좎같 怨좎같 5
결과가 위처럼 뜨게된다 .
이상한게 , 어제만 해도 잘됬는데 , 한글이 깨져버린다…
이점을 고치려고 하였으나 … 차차 찾아보도록 하겠다..
# 저장위치 설정
word_path <- paste0(getwd(),"/MainArticle.csv")
# csv파일로 저장
write.csv(profile, word_path)
#수정한 csv파일 불러오기
data <- read.csv(word_path)
#첫 column은 단어의 중복이므로 삭제한다.
data <- data[,-1]
#일정 횟수 이상 검색된 항목만 추출한다.
data_pick <- subset(data, freq >= 0)
# 제일 많이 검색된 순서대로 보기 (10개까지)
head(data_pick,10)
결과값은 다음과 같이 깨진 word를 기준으로 빈도수를 볼 수 가 있다.
word freq1 <ec>뿰援<ac> 15
2 愿\u0080<ed>븳 14
3 諛<8f> 12
4 誘몄튂<eb>뒗 10
5 <eb><8c>\u0080<ed>븳 8
6 洹<b8> 6
7 <ec>쐞<ed>븳 6
8 <ec>쁺<ed>뼢 6
9 遺꾩꽍 5
10 怨좎같 5
이제 wordclout2로써 시각화를 해볼 것이다.
그전에 특정 빈도수에 따른 값들은 글자 색깔을 다르게 줘볼 것이다.
# 특정 빈도수에 따른 별도의 색깔 출력
in_out_colors = "function(word,weight)
{return(weight > 5 ? '#4B088A':'#81F7F3')}"
# word cloud 그리기
# 기존모형으로 wordcloud 생성
# 모양선택 : shape = 'circle' , 'cardioid' , 'diamond ' , 'triangle -forward', 'triangle' , 'pentagon' , 'star'
wordcloud2(data_pick,shape = "diamond",size=0.3,color=htmlwidgets::JS(in_out_colors), backgroundColor = "black")
글자 크기인 size = 0.3으로 줘보겠다.
최종결과값은 다음과 같다.
한글이 깨저버려서 값들이 이상하다…ㅠㅠ
그렇지만 인코딩 문제를 제외하고선 색깔 옵션이 잘 들어갔고 , 빈도수에 따른 크기도 제대로 들어간 것을 확인할 수 있다.

위의 결과는 main_article의 결과이며 , 저자와 , 발간일도 동일하게 해주면 된다
지금은 한글이 깨져서 값이 이쁘게 나오지 않기 때문에 오류 발견시 제대로 올려보겠다…ㅠㅠ
'학부공부 > 데이터마이닝과통계' 카테고리의 다른 글
| 구글서칭결과크롤링+CSV파일저장시키기 (3) | 2018.11.19 |
|---|---|
| Corpus --> VCorpus (2) | 2018.11.18 |
| API를 사용해서 실시간 버스 위치정보 시각화 (1) | 2018.11.15 |
| web_crawling + wordCloud (0) | 2018.11.15 |
| 동아신문 스크랩핑 (0) | 2018.11.14 |
#IT #먹방 #전자기기 #일상
#개발 #일상