
Steam 에서 특정 태그에 해당하는 태그 성향 분석하기 1
Steam 게임은 게임을 좋아하는 사람이라면 알고 있는 게임 툴일 것이다.
Steam에는 수많은 게임들이 존재한다.
정말 매력적인 것은 스팀에서 게임을 올릴 때 , 개발자가 각 게임에 대해서
태그 ( Tag ) 로써 게임의 성향을 써놓았다.
이 태그들을 통하여서 , 각 게임에 대해서 어떠한 특성을 가지고 있는지 알 수 있게 된다.
Steam에서는 태그별로 게임들을 분류해 놓았다 .
정말 다양한 Tag들이 존재한다.
이 Tag들에 따른 Game들이 존재하게 되는데 , 과연 이 Tag 에 따른 게임들이 어떻게 다양하게 존재하고 ,
얼마나 관계가 있을까 궁금했다.
그래서 나는 R 을 사용해서 크롤링을 해서 , wordcloud2를 사용해서 특정 태그에 존재하는 게임들의 성향을 알아 보았다.
코드를 보면서 말해보겠다.
많은 태그들 중 Indie태그에 해당하는 게임들을 알아 볼 것이다 .

library(rvest)
library(xml2)
library(dplyr) #파이프 구조 ( %>% ) 를 쓰기 위한 라이브러리
library(stringr)
# 필요한 패키지들
library(devtools)
library(htmlwidgets)
library(htmltools)
library(jsonlite)
library(yaml)
library(base64enc)
library(tm)
library(NLP)
library(wordcloud2)
library(extrafont)
나는 수 많은 태그들 중에서 Indie 태그를 알아 볼 것이다.
기본적으로 Indie 태그는 페이지의 이동 변수가 p이며 , 값은 0 부터 시작하며 , 1씩 증가함에 따라 페이지의 이동이 된다.
First_url <- "https://store.steampowered.com/tags/en/Indie/#p="
# First_url : Page라는 페이지의 이동 변수를 기준으로 앞 주소
second_url <- "&tab=NewReleases"
# second_url : Page 라는 페이지의 이동 변수를 기준으로 뒤 주소
urls <- NULL
# 여기 포인트 : 벡터의 주소값은 1 부터 시작한다 , 그런데 url 주소를 보면 페이지의 이동이 p=0부터 시작한다
# 그래서 x -1 을 해줌으로써 p=0을 맞춰줌
for(x in 1:2)
{
urls[x] <- paste0(First_url,as.character(x-1),second_url)
}
데이터가 많기 때문에 , 첫 페이지와 두번째 페이지 까지만 가져올 것이다.
이제 urls 라는 변수에 벡터로써 주소값들이 존재하게 된다 .
가져왔으면 크롤링 할 준비를 하면 된다.
근데 , 여기서 생각해 볼 것이 다음과 같다.
1. 나는 게임의 이름과 게임이 어떠한 특성을 가졌는지 알고 싶다
2. 그렇기 때문에 크롤링해올 것들은 게임의 이름 , 게임의 특성 ( 여기서는 Tag ) 이다.
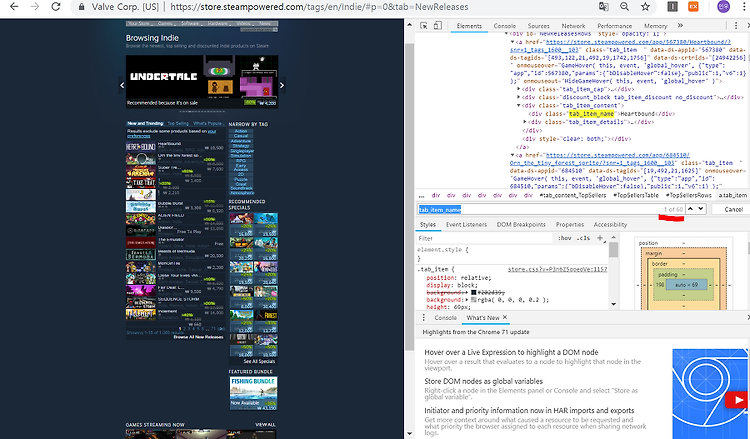
3. 그렇다면 , 페이지 이동에 따른 주소에서 html을 가져와서 거기서 바로 크롤링을 하는가 ??
4. 아니면 , 페이지 이동에 따른 전체 urls에서 특정 게임에 해당하는 <a> 태그내에 존재하는 link를 타고 들어가서
거기서 크롤링을 할 것인가??
나는 두 가지 방법을 다 해보았는데 , 3번을 하게 될 경우 Steam에서는 제대로된 크롤링을 해오지 못한다 .
왜냐하면 , Steam의 구조를 보니까 , 가져온 페이지 이동 주소에서 게임의 이름과 게임의 태그들을 가져온다고 했을 때
불필요한 부분까지 포함이 되었고 , 화면내에서는 안보이는 부분까지 불필요하게 가져왔기 때문이다 .
그래서 4번 방법으로 크롤링을 진행 하였다.
# ---------------------- Get Steam _ game _ name (Indie)
# 그 페이지에 존재하는 class 값이 존재한다면 그 값을 다 가져와 버린다 .
# 그렇기 때문에 나는 , 특정 범위를 잡아서 그 범위 내에 존재하는 class 이름들만 검색한후
# 해당하는 값들만 가져온다 .

game_name <- NULL
for(url in urls)
{
html <- read_html(url)
game_name <- c(game_name, html %>% html_nodes("#NewReleasesRows") %>% html_nodes(".tab_item_content") %>% html_nodes(".tab_item_name") %>% html_text())
}
위 처럼 게임의 이름을 가져온다 .
이제는 , 해당하는 게임의 성향을 알기 위해서 Tag로 된 것들을 크롤링 해야 한다 .
그러기 위해서는 <a> 태그로 감싸진 href 주소 값을 뽑아야 했다.
# ------------------------ Get Steam _ game _ name _ Genre (Indie)
# 게임에 대한 정보를 포함하고 있는 <a> 태그 주소값들을 뽑는다 .
game_Genre_link <- NULL
for(url in urls)
{
html <- read_html(url)
game_Genre_link <- c(game_Genre_link, html %>% html_nodes("#NewReleasesRows") %>% html_nodes("a") %>% html_attr("href"))
}
우리는 특정 게임에 해당하는 href 주소 까지 가져왔다.
이 href는 해당하는 게임의 자세한 정보를 담고 있다 .
우리는 이 주소에서 게임의 성향을 크롤링 해올 것이다.
그런데 , 크롤링을 해 올 때 , 가져온 값들을 연속된 값으로써 한 변수에 넣는 특성이 있다.
이 특성은 특정 게임에 해당하는 성향을 알고 싶거나 , 분류하고 싶을 때 문제가 된다.
그래서 , 다음처럼 function을 해줌으로써 , 특정 게임에 해당하는 성향을 분류해줄 것이다.
a 는 특정 게임에 해당하는 성향을 분류해주기 위한 주소값이라고 생각하면 된다 .
game_Genre <- NULL
game_Genre_Filter <- NULL
Filter_str <- function(str,sep=",")
{
paste(str,collapse = sep)
}
a <- 0
for(url in game_Genre_link)
{
a <- a + 1
download.file(url, destfile = "scrapedpage.html", quiet = TRUE , encoding = "UTF-8")
html <- read_html(url)
game_Genre <- c(game_Genre, html %>% html_nodes(".responsive_page_content") %>% html_nodes(".glance_tags.popular_tags") %>% html_nodes("a") %>% html_text())
game_Genre_Filter[a] <- Filter_str(game_Genre) // 이 부분이 특정 게임에 해당하는 성향을 분류해주는 곳
}
다음은 크롤링해온 성향에 불필요한 정보가 있어서 대체해 준 것
game_Genre_Filter <- gsub("\t","",game_Genre_Filter)
game_Genre_Filter <- gsub("\r","",game_Genre_Filter)
game_Genre_Filter <- gsub("\n","",game_Genre_Filter)
game_Genre_Filter <- gsub(" ","",game_Genre_Filter)
다음은 가져온 정보가 연속된 정보이기 때문에 , 똑같은 벡터를 만들어서 중복되는 , 즉 전에 있던 값들이 존재한다면 공백으로써 대체해 주는 작업이다.
game_Genre_Filter_real <- game_Genre_Filter[1:30]
game_Genre_Filter_real <- NULL
i <- 0
for(i in 2:30)
{
game_Genre_Filter_real[i] <- str_replace_all(game_Genre_Filter_real[i],game_Genre_Filter[i-1],"")
#game_Genre_Filter_real[i] <- gsub(game_Genre_Filter[i-1],"", game_Genre_Filter_real[i],perl = FALSE,fixed = FALSE, useBytes = FALSE)
--> R에서는 특정 문자를 대체하는 함수가 있는데 , 보통 나는 gsub를 사용했었다 . 그런데 위에서 gsub를 사용하게 되면 이상하게 문법 오류가 떠서 , str_replace_all 함수를 사용하였다.
}
game_Genre_Filter_real
이제 가져온 게임의 이름과 , 장르를 하나의 데이터 프레임으로 만들어 준다 .
data1 <- data.frame(게임=game_name , 장르=game_Genre_Filter_real)
이쁘게 왼쪽 정렬도 해주고
data1$게임 <- format(data1$게임, justify = 'left')
data1$장르 <- format(data1$장르, justify = 'right')
이제는 가져온 데이터들을 wordcloud 를 사용해서 어떠한 성향이 제일 많은지 볼 것이다 .
write.csv(game_Genre_Filter_real,"C:/Users/user/Desktop/졸작/Steam_Crolling/Indie_Genre.csv",append=F)
// 일단 장르를 따로 csv파일로 저장시킨다.
상대경로를 지정해주는 부분이다.
news_path <- NULL
modi_txt <- NULL
news_path <- paste0(getwd(),"/Indie_Genre.csv")
modi_txt <- readLines(news_path)
csv 파일의 행의 갯수를 정하며 , 행마다 고유 번호를 지정한다 .
last_number_of_lines <- length(readLines(news_path))
line_numbers <- seq(1,last_number_of_lines,1)
doc_ids <- line_numbers
df <- data.frame(doc_id = doc_ids,text = modi_txt, stringsAsFactors = FALSE)
// 아까 만들어 준 고유 번호를 기반으로 데이터 프레임을 만든다.
modi_data <- Corpus(DataframeSource(df))
// Corpus
tdm_modi <- TermDocumentMatrix(modi_data)
// Matrix 생성
TDM1 <- as.matrix((tdm_modi))
// TDM 생성
v=sort(rowSums(TDM1), decreasing = TRUE)
profile = data.frame(word=names(v),freq=v)
//빈도수 계산
head(profile,10)
// 상위 10개
word_path <- paste0(getwd(),"/Indie_Genre.csv")
// 경로 지정
write.csv(profile, word_path)
// 경로에 csv파일 생성
data <- read.csv(word_path)
// 만들어준 csv파일 읽어옴
data <- data[,-1]
// 첫 행은 중복이니까 삭제
data_pick <- subset(data, freq >= 0)
// 빈도수 정하기 .
head(data_pick,10)
// 상위 빈도수 10개
in_out_colors = "function(word,weight)
{return(weight > 5 ? '#4B088A':'#81F7F3')}"
// 색상 설정
wordcloud2(data_pick,shape = "diamond",size=0.7,color=htmlwidgets::JS(in_out_colors), backgroundColor = "black")
// wordcloud 출력
최종 출력물은 다음과 같다 .
나는 Indie 태그에서 1~2 페이지 까지만 알아 보았다 .
역시나 , indie 성향이 제일 강한것을 볼 수 있다 .
왜냐하면 Indie 태그였으니까 말이다.
그 다음으로 Action Access , Early ... 등등이 있다.
indie 태그라고 해서 다른 성향이 없는 건 아닌것 같다 .

'졸업작품_preparing.... > R_작업' 카테고리의 다른 글
| Steam_game_Analysis_3(Genre , Recommendation Count , Metacritic ) (1) | 2019.01.24 |
|---|---|
| Steam_game_Analysis_2(FreeVsPair_Game 비교) (0) | 2019.01.20 |
| Steam_game_Analysis_1 (0) | 2019.01.20 |
#IT #먹방 #전자기기 #일상
#개발 #일상