![[Stanford University CS231n, Spring 2017] Lecture 2 | Image Classification](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FbmuDJk%2FbtqAsSttPn2%2FAAAAAAAAAAAAAAAAAAAAACHikXUFs1aoiIYKBaL7v2nm541JOtYAYMJG1CJsrs5k%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3DzOH%252Fg2GHfF139AjoZ%252FDjIeeXaNg%253D)

오늘은 cs231n 2강을 제 소신껏 정리를 해보겠습니다
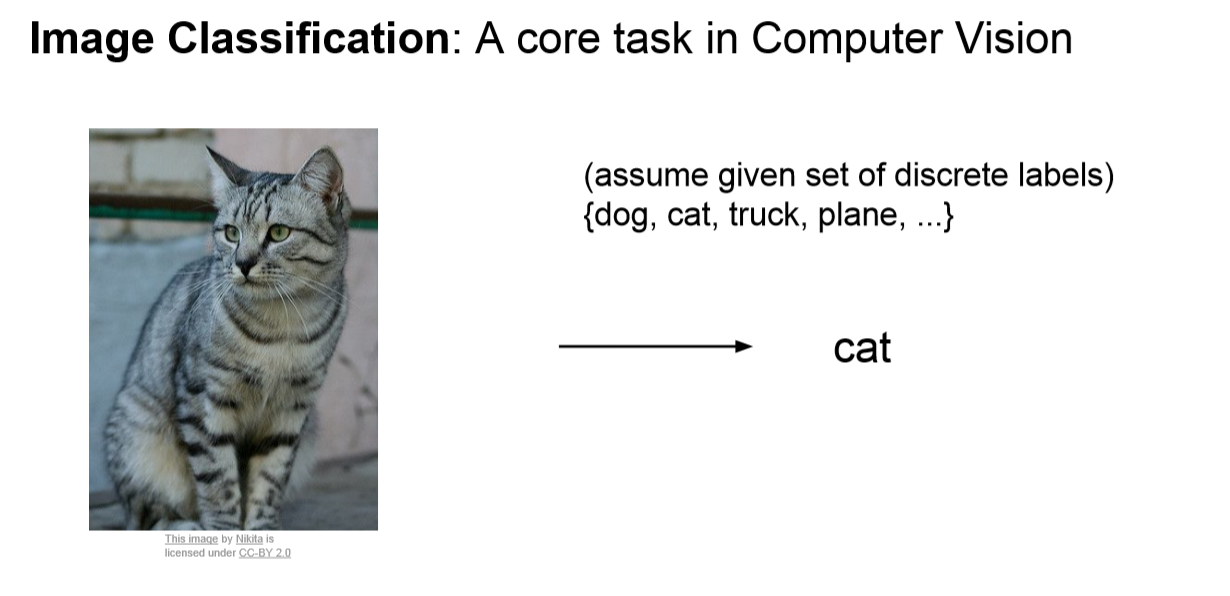
2강의 시작은 이미지 분류가 무엇인지에 대해서 설명하고 시작합니다.
위 사진을 보았을 때 , 저희는 고양이라고 이미지를 보고 판단하게 됩니다.
그러나 컴퓨가 이 이미지를 보고 고양이라고 생각할 수 있을까요!?
컴퓨가 이미지를 보고 이 이미지는 고양이라고 판단할 수 없습니다.
그 이유는 다음 이미지를 통해 설명해 보겠습니다.
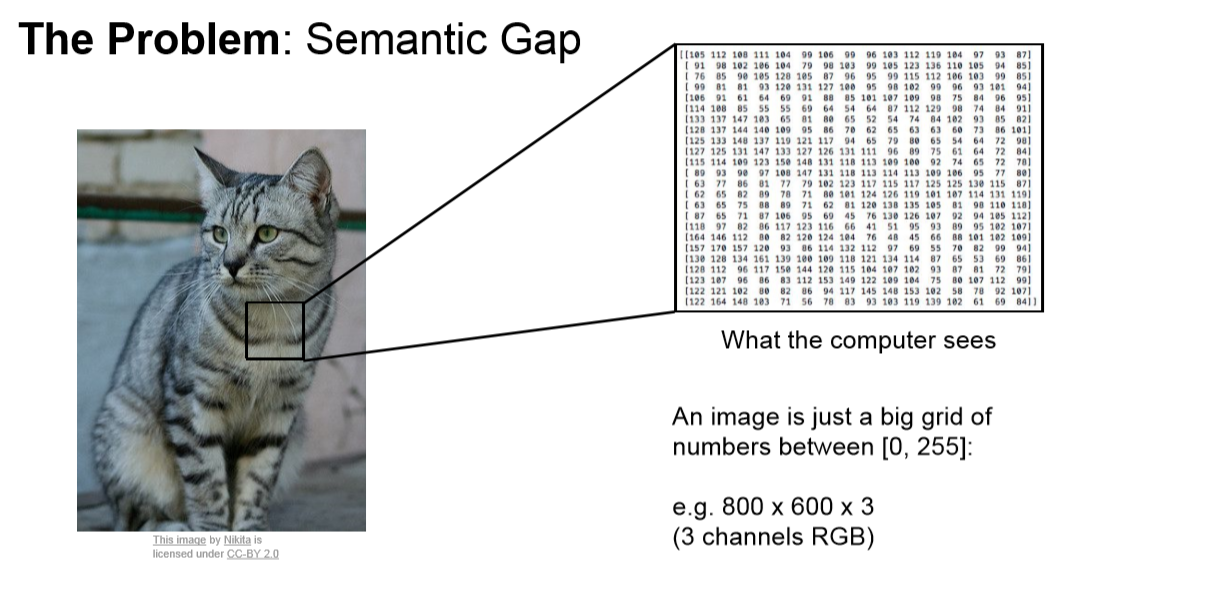
컴퓨터는 이미지를 바라 볼 때 RGB값인 수많은 숫자로 인식을 하게 됩니다.
그렇기 때문에 컴퓨터가 이미지를 한번에 알아 보기는 당연히 힘든일입니다.
거꾸로 생각해 보면 쉬울것 같습니다
만약 우리가 숫자로 된 화면을 보고 있다고 하면 우리 또한 이미지를 한번에 알아차리기는 힘들 것 입니다.
그 외에도 이미지 분류를 할 때 몇가지 문제점들이 있습니다.


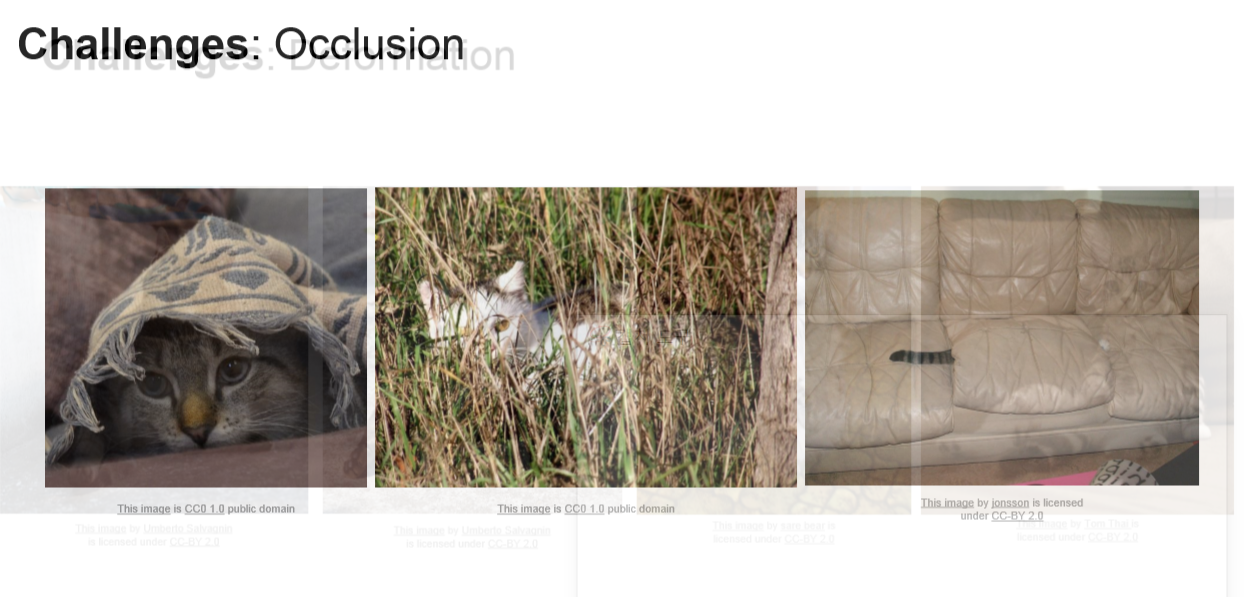


위의 사진들 처럼 조명이 다르거나 자세가 다르거나 배경과의 색깔차이 혹은 많은 고양이들이 존재한다면
구별하기 힘들 것입니다.
인식을 할 때 숫자로 인식하기 때문에 더욱 그럴것입니다.
이처럼 이미지를 분류하는 작업은 말처럼 쉬운 작업이 아님을 알 수 있습니다.
숫자를 정렬시키는 것과 같이 단순히 코딩을 열심히 한다고 해서 분류할 수 있는 작업이 아니기 때문입니다.

그래서 우리는 수많은 시도를 해왔습니다.
그 중 예로 이미지의 꼭지점을 찾아서 연결하여 이미지를 판별하는 것인데요.
이것 또한 쉬운일은 아니였습니다.

그래서 우리는 "데이터에 기반한 접근법"을 생각하게 됩니다.
무수히 많은 사진들을 기반하여 이미지가 무엇이다 라고 알려주는 것입니다.
그 후에 머신러닝을 통하여 분류기를 만들어 이미지를 분류한다면
"이미지를 분류할 수 있지 않을까?" 라고 생각을 하게 된 것입니다.
예를 들자면 정말 어린아이에게 어떠한 이미지를 보여준 다음
이 이미지는 ~야 라고 얘기를 합니다.
그렇다면 그 어린아이는 한번에 알수 있을까요~?!
그렇지 않다는 것입니다.
어린아이가 인지하기 위해서 그 이미지와 비슷한 이미지를 보여주면서
이것은 아까 그 이미지와 똑같은 거란다~ 라고 가르친다면
훨씬더 빠르게 인지하게 될 것입니다.
위와 같이 이러한 접근법이 " 데이터에 기반한 접근법 " 이라고 말할 수 있습니다.
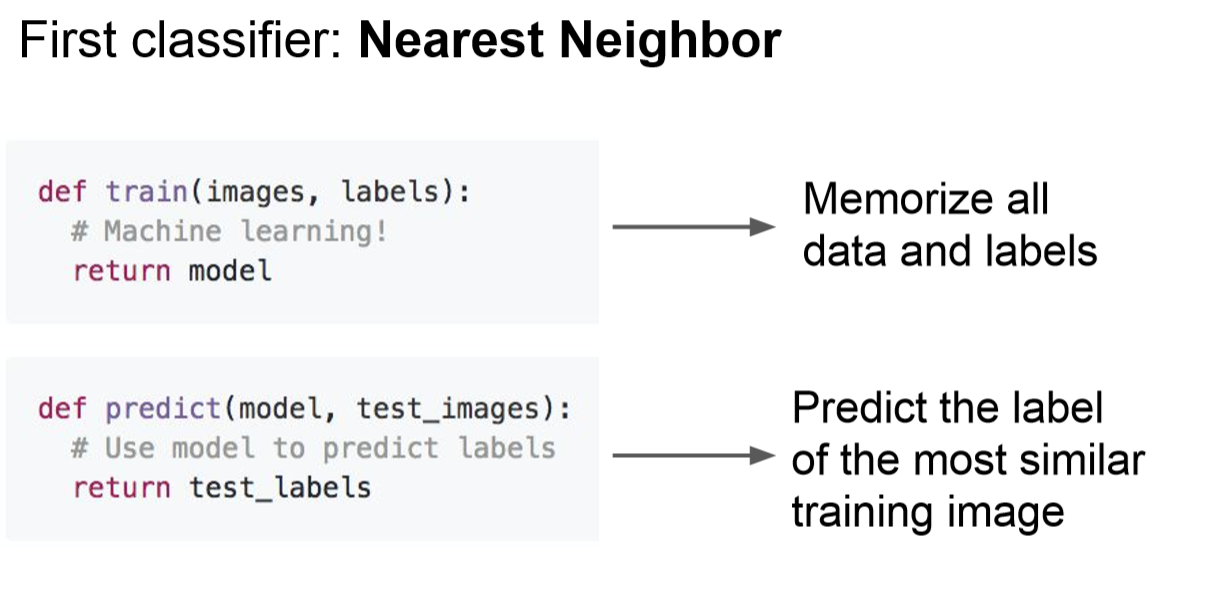
위의 내용을 기반으로 나온 첫 분류방법이 Nearest Neighbor 입니다.
즉 , "가장 가까운 이웃 찾기 " 입니다.
간략하게 말해서 주어진 이미지를 모두 외운다음에
어떠한 이미지가 다시 주어졌을 때
외운 이미지들 중에서 가장 비슷한 이미지를 찾아내는 것입니다.
예를 들자면 어린아이들에게 이미지를 보여주고 대략적으로
이 이미지는 독수리이고 ~ 이 이미지는 꽃이야 ~
라고 알려주는 것입니다!

우리는 데이터셋이란 것을 사용할 것인데요. 사용될 데이터셋은 CIFAR 10이란 데이터 셋을 사용할 것입니다.
이 이미지 데이터셋들은 앞면에는 이미지가 있을 것이고 , 표면적으로 보이진 않지만 뒷면에는 이 이미지에 해당하는 정보들이 있을 것입니다.
여기서 class는 개,말,배,트럭 등과 같이 물체의 이름을 말합니다.
그리고 이 데이터셋을 기반으로 어린아이에 해당하는 "컴퓨터"에게 가르친 다음
"Nearest Neighbor" 을 사용하여 이미지 분류를 할 것입니다 !!
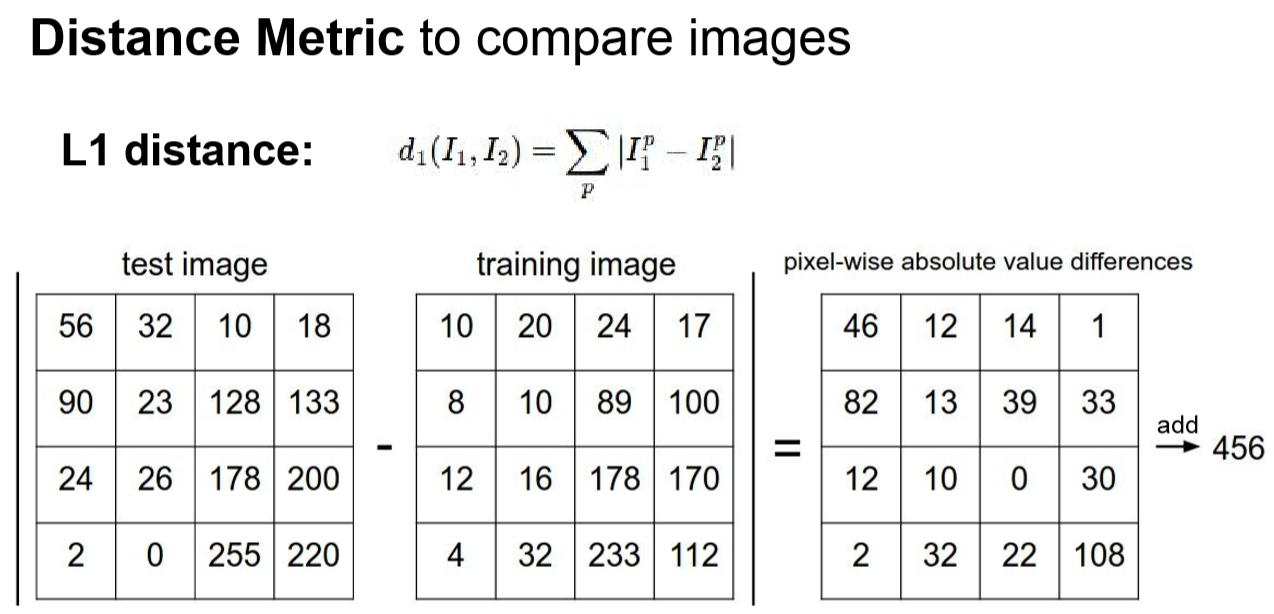
한가지 궁금점이 생길 수 있습니다.
어떻게 이미지를 비교하고 비슷한 이미지인지를 분별하는 걸까?! 라고 말입니다.
그 해답은 위의 Distance Metric 공식을 통하여 답을 얻을 수 있습니다.
이 공식은 이미지 각 픽셀마다 적용되는 공식인데요!
컴퓨터는 이미지를 볼 때 숫자로 본다고 했었는데요! 컴퓨터의 입장에서 볼 때
숫자가 비슷하다면 비슷한 이미지로 인식할 것입니다!!
위 생각을 기반으로 알고자 하는 이미지와 훈련되어진 이미지를 비교하게 되는데요!
알고자 하는 이미지에서 훈련되어진 이미지를 뺀 다음 ! 절대값을 씌어주게 되면
우리가 알고 있는 거리 공식이 성립되게 되는 것입니다!
이 때는 이미지에 해당 하는 모든 픽셀에 이 공식을 적용시켜 주는 것이고 ~
거리 공식을 적용하여 나온 값들을 모두 더해주게 되면 하나의 정수 값이 나올 것입니다.
즉, 두 이미지의 거리를 구하는 것이 L1 distance라고 할 수 있겠습니다.

어린아이에 해당하는 "컴퓨터"에게 분류하는 방법을 가르치기 위해서는 크게 2가지로 나눌 수 있습니다.
위의 그림을 보시죠.
크게 train이라는 학습 부분과 학습분 내용을 기반으로 predict 하는 예측 부분이 있습니다.

위의 그림을 보겠습니다.
Nearest Neighbor classifier 에서 이미지 분류는 모든 이미지를 외운다음에 알려주는 것이라고 하였습니다.
그렇다면 train은 모든 이미지를 외워버리는 것 이라고 생각하면 될것입니다.

다시 위 그림을 보겠습니다.
위 그림은 predict 예측하는 부분입니다.
위 그림을 간략하게 설명해 보자면 train에서 모든 이미지를 외웠던 것을 기반으로
사진이 보여지면 이 사진과 train된 사진의 차를 구해서 사진의 비슷한 정도를 분류하여
" 아 ~ 이 사진은 이만큼 차이가 나기 때문에 ~ 이네 "
라고 생각하는 과정이 바로 이 부분이 Nearest Neighbor classifier 에서 predict 예측하는 부분입니다.

그렇다면 여기서 질문입니다.
N개의 샘플을 가지고 얼마나 빠르게 훈련하고 예측할 수 있을까요?!

한개의 객체 ( O ) 를 가지고 N개의 객체 ( O ) 를 인지할 수 있습니다.

그런데 말입니다.
여기서 한가지 문제점이 있습니다.
우리가 예를 들어 설명하고 있는 컴퓨터라는 아이는 학습하는 데에는 매우 뛰어난 능력을 가지고 있지만
예측하는데는 많은 시간을 필요로 합니다.
예를 들어 보겠습니다.
만약 10000장의 이미지를 학습을 했고 , 만장의 이미지를 기반으로 새로운 이미지가 들어온다고 할 때
컴퓨터라는 아이는 새로운 이미지에서 알고 있는 이미지를 빼주어야 할 것입니다.
물론 만장의 이미지를 하나하나를 빼줘야 하기 때문에 오랜시간이 소요될 거라 생각이 들긴합니다.
그런데 의문인점은 왜(?) 이게 문제인지입니다.
이미지를 예측 하는 어플이나 프로그램이 있다고 가정을 해봅시다.
훈련하는데에는 짧은시간이 걸리지만 예측하는데 2시간이 걸린다고 하면
사용자들의 입장에서 사용하고 싶을까요?!
아마 사용자들은 기다리다가 지쳐 버릴지도 모릅니다.
훈련은 한번만 하면 되는 것이고 문제는 없지만
예측을 하는데 오래 걸린다면 큰 문제가 된는 것입니다 !!

위 사진을 보겠습니다.
위 사진은 Nearest Neighbor classifier 방식으로 교육받은 아이가 자기가 이해한 대로
그린 그림이라고 가정하겠습니다.
총 5가지 색깔이 있는데 색깔 별로 특정한 물체를 가르키는 것이고 점들은 각각의 이미지 사진들을 의미한다고 가정해 보겠습니다.
그렇다면 아이가 교육받은 내용을 토대로 위 그림을 설명해 보자면 다음과 같겠군요
" 자동차에 해당하는 이미지 사진들이 13개 정도 있네~!? " 라고 말입니다.
과연 맞을까요..??
한가지 의문점이 드는데요.
가운데를 보겠습니다.
초록색 범위 내에 노란색 점이 찍혀 있는 걸 알 수 있습니다.
저희가 알고 있는 Nearest Neighbor classifier 에 따르면 뭔가 이상하다는 생각이 들 것입니다.

그래서 보완이 된 것이 K-Nearest Neighbor 입니다.
가장 가까운 것을 찾는건은 그대로이지만 여기서 한가지 추가가 됩니다.
주변에 매개변수인 K개를 보았을 때 가장 비슷한 것이 정답이라고 말할 수 있게 되는 것입니다!!
K = 1 일때를 보겠습니다. 가운데 초록색들이 울퉁불퉁하고 초록색 가운데애 주황색이 껴있는 것을 알 수 있습니다. 반면 K = 3 일 때를 보면 K = 1 일 때 뽀다 초록색의 울퉁불퉁이 약간 모여있는 형태를 보여주고 있습니다. 또한 초록색 가운데에 있던 주황색이 사라짐을 확인 할 수 있습니다. K = 5 일 때를 보겠습니다. 보면 K = 3 일 때 보다 자기 색깔끼리 더 모여있음을 확인할 수 있습니다.

위 사진을 보겠습니다.
CIFAR-10을 K-nearest Neighbor로 훈련시킨 결과입니다. 왼쪽은 정답 종류를 의미하고, 오른쪽은 훈련된 컴퓨터가 예측한 사진입니다.
얼핏 보면 컴퓨터가 사진을 잘 예측한 것으로 보일 수 있습니다. 그러나 자세히 보면 전혀 다른 사진들을 골라내고 있습니다. 비슷한 사진들을 골라내는 것이지요.
뭔가 아직은 많이 부족해 보이네요.
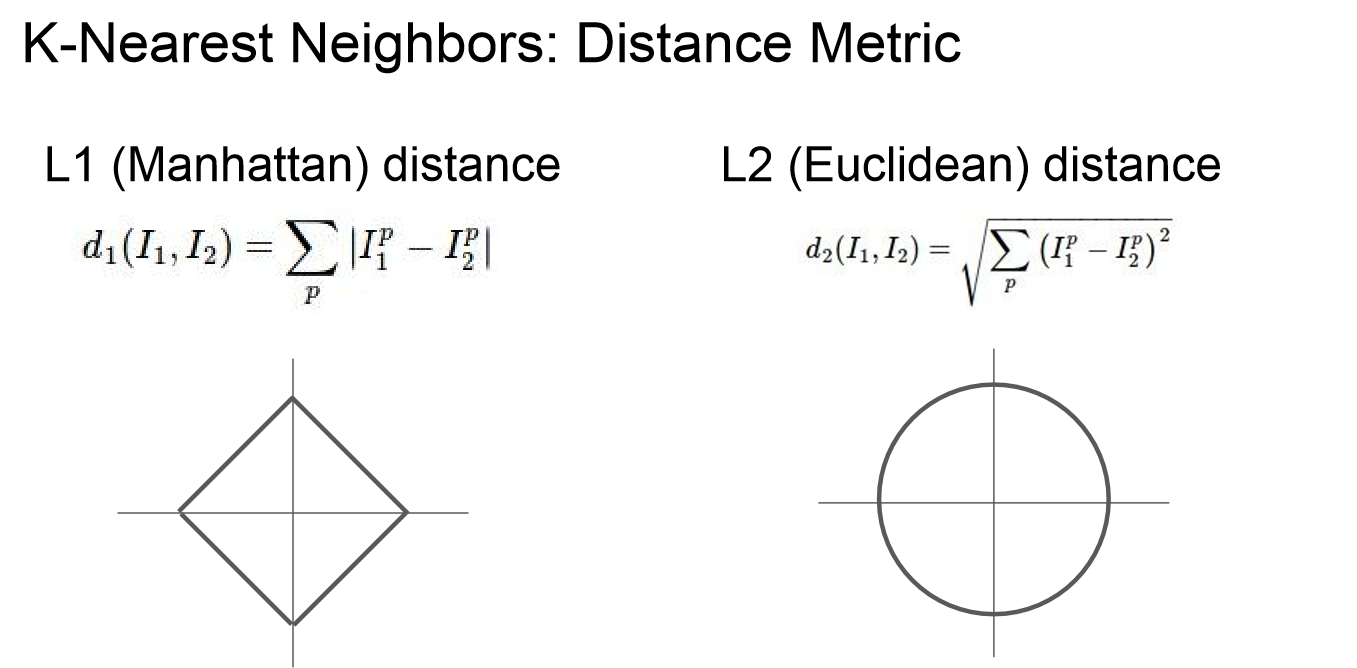
저희는 지금까지 L1 distance에 대해서 알아 보았는데요. 쉽게 말해 사진을 분류하기 위해 이미지 사이의 거리 공식을 이용하고 있습니다. 그 거리 공식에는 위 사진처럼 2가지가 있는데요. L2 distance를 이용한다면 어떻게 될까요??
L1 distance는 위 사진처럼 마름모의 형태를 나타내며, L2 distance는 위 사진처럼 원형의 형태를 나타냅니다.
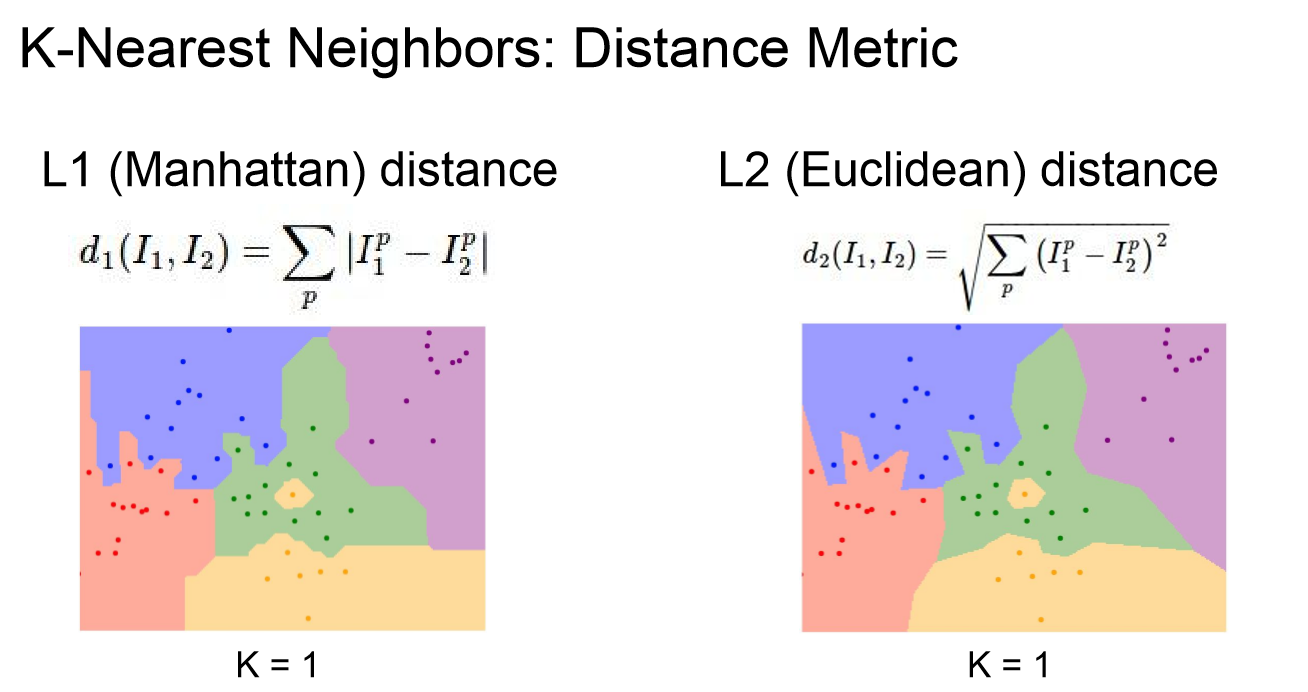
L1 distance와 L2 distance는 어떻게 다를까요?
위 그림을 통해 K = 1 일 때를 비교해 보겠습니다.
얼핏보면 비슷해 보이지만, 자세히 보면 다르게 생긴것을 알 수 있습니다.

혹시나 직접 실습을 해보고 싶으신 분이 계신다면
다음 링크를 들어가셔서 해보시는 것도 좋을거 같습니다 ^^
http://vision.stanford.edu/teaching/cs231n-demos/knn/
http://vision.stanford.edu/teaching/cs231n-demos/knn/
vision.stanford.edu

위 링크를 통하여 실습을 해보셨는지요 ~??
그렇다면 궁금한게 생기셨을 겁니다 !! 베스트 값인 K와 distance는 무엇일까?? 입니다.
정답 부터 말하자면 딱! 정해진 답은 없습니다 !!
각각의 상황에 따라 다른 값을 넣어 봄으로써 최고의 결과가 나오는 값을 선택하는 것이지요~
그리고 K와 distance는 파라미터라고 불리어 지는데요!! 사용자가 직접 값을 입력하는 값입니다.
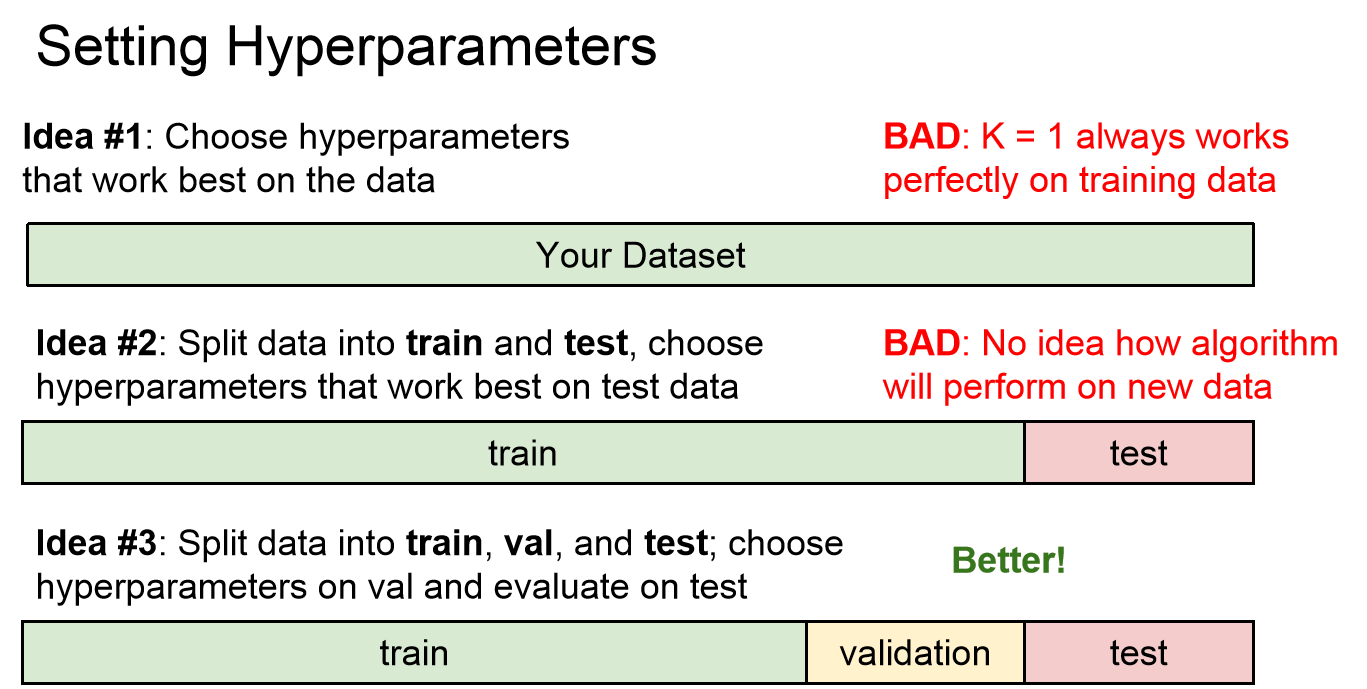
그러면 우리는 어떻게 베스트 값인 하이퍼파라미터의 값을 정할 수 있을까요?!
우리는 몇 가지 생각을 해 볼 수 있습니다.
첫 번째로는 우리가 가지고 있는 데이터셋에 그냥 넣어버리면 되는거 아닌가? 하고 생각을 할 수 있습니다.
아쉽게도 이런 방법은 문제점을 야기합니다.
K = 1 일때 아까 위에서 보았듯이 우리의 데이터셋에서 좋은 결과를 나타냈음을 알 수 있습니다.
그러나 이 결과는 다른 사진이 들어오지 않을 때 K = 1 일때에만 해당됩니다.
다른 사진들이 들어왔을 때 위에서 보았듯이 이상하게 나온다는 것을 확인할 수 있었습니다.
우리는 우리가 가지고 있는 데이터셋에서 어떤 이미지가 ~~이다 라고 예측을 하는 것이 아닙니다.
우리의 목표는 임의의 이미지 데이터가 들어왔을 때 이 이미지는 ~~이다 라고 분류를 하는 것이지요.
위 생각 말고도 다음 생각도 해볼 수 있습니다.
그렇다면 train과 test로 분류한 다음 test 할때 제일 좋은것으로 선택하면 되지 않을까? 입니다.
물론 이 방법도 결론부터 말하자면 좋은 선택은 아닙니다.
test에 적절한 K 또는 distance 값을 바꿔주면서 한다고 하더라도, 결국에는 test 내에서만 작동할 수 있는 것이고 새로운 데이터가 들어왔을 때는 결과값이 또 어떻게 될지 모르기 때문입니다.
마지막으로 다음과 같은 생각도 해 볼수 있습니다.
사용자의 데이터셋을 세 부분으로 나누어 보는 것입니다.
train,validation,test 로 나누어 준 후에 train 되어진 데이터셋을 , validation 데이터셋으로 확인하며 hyperparameter를 바꾸어 주며 , test는 마지막에 한번 확인해 주는 것입니다.
이렇게 되면 기존의 데이터가 아니라 완전한 새로운 데이터세트에서 테스트를 해볼수 있을 것입니다.
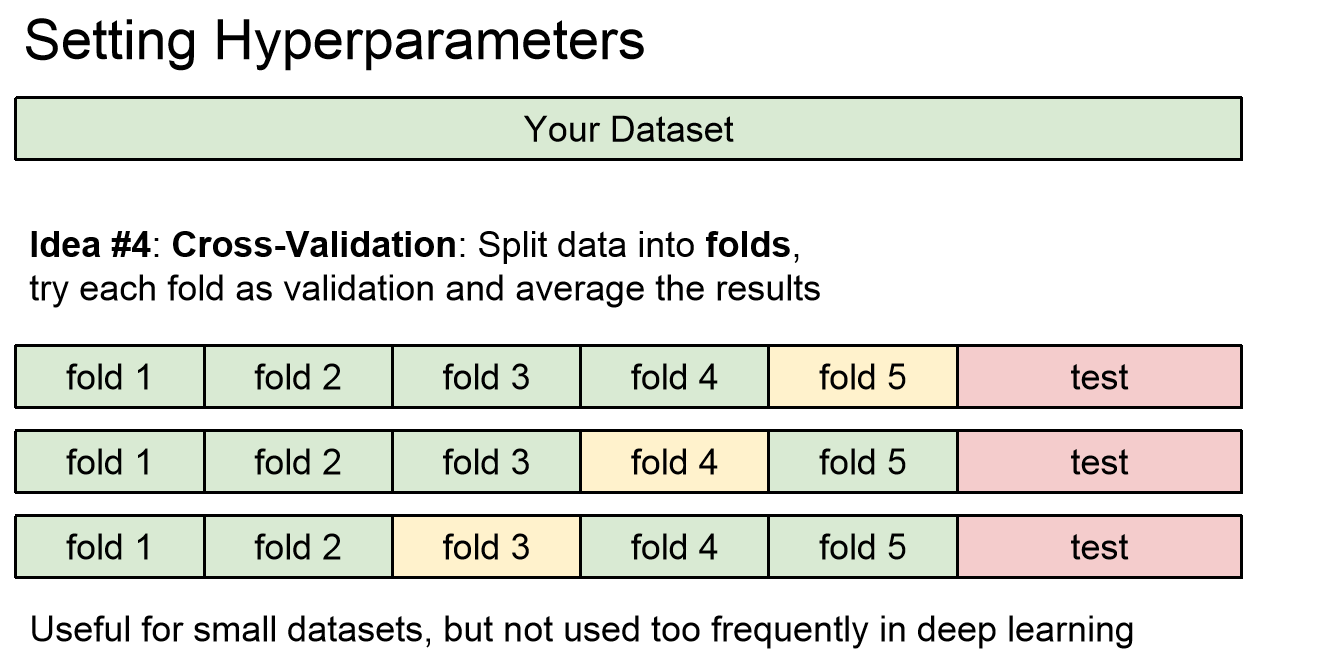
위 사진을 보겠습니다.
위 사진은 Cross-Validation이라는 방식으로 생각을 해본 것입니다.
위 방식은 먼저 데이터셋을 두개의 폴더로 나누게 되는데 폴더라는 것은 데이터셋으로 생각하면 쉬울거 같습니다.
나누어진 하나의 폴더는 큰폴더로 나머지 폴더는 작은폴더로 나눕니다.
작은폴더는 test 셋으로 설정을하고 큰 폴더를 다시 여러개의 폴더로 나누게 됩니다.
이 때 첫번째 폴더는 validation 으로 놓고 나머지는 train으로 놓은 뒤에 hyperparameter 를 설정한뒤 다시 두 번째 폴더만을 validation 으로 놓고 나머지 모두 train 으로 놓은 뒤에 hyperparameter 로 설정하고...
이 과정을 반복하여 나온 결과값의 평균값을 hyperparameter로 결정하는 방식입니다.
이 과정은 확실하게 hyperparameter의 값을 구할 수 있을 듯합니다.
그러나 Cross-Validation은 딥러닝에서 많이 사용되지 않는 기술입니다.
정확하긴 하나 연산을 굉장히 많이 해야 하기 때문에 하나하나 할 수 없기 때문입니다.
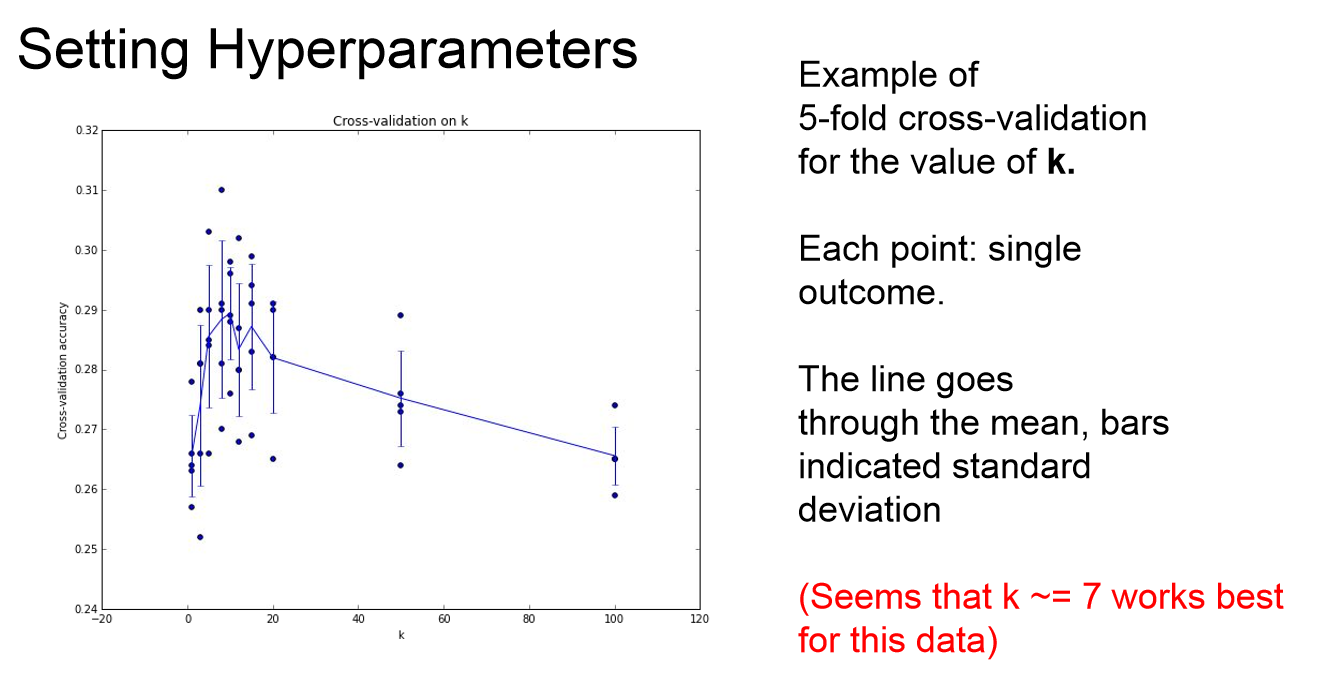
위 그림을 보겠습니다.
아까 언급한 과정을 그래프로 나타내 본 것입니다.
X축은 K의 값을 의미하며 Y값은 test에서의 정확도 값을 의미합니다.
위 그래프에서 알 수 있듯이 K의 값이 대략적으로 7일 때 가장 높은 정확도를 나타내고 있음을 알 수 있습니다.
즉 K = 7일 때 가장 효율적이다 라고 생각을 할 수 있을듯합니다.
주의해야할 점은 이렇게 나온 hyperparameter 들은 각각의 다른 문제,데이터셋에 따라 모두 다르다는 것입니다.
예를 들면 다음과 같습니다.
같은 방식으로 훈련된 데이터셋에서 하나의 이미지가 주어졌을 대
"이 이미지가 고릴라일까요? 원숭이 일까요? " 라는 문제에 최적화된 hyperparameter 의 값과
"이 이미지가 자동차일까요? 오토바이 일까요? 라는 문제에 최적화된 hyperparameter의 값은 다르다는 것입니다!
결론적으로 얘기를 하자면 모든 데이터셋과 문제들마다 한번씩 위 과정을 실행하여 설정하는 가장 좋다는 것입니다.

그러나 지금까지 설명해 왔던 Nearest Neighbor 이라는 방식은 절대로 사용되지 않습니다.
약간 허무하실 것입니다...
Nearest Neighbor 방식은 Predict 할때의 과정이 많은 시간을 요구하고 사진과 사진사이의 distance 는 사실상 그렇게 중요한 값이 아니기 떄문입니다.
위 그림을 보겠습니다.
Boxed , Shifted , Tinted 사진은 왼쪽의 Original 사진과 같은 L2값을 가지고 있다고 합니다.
이것으로 학습을 하게 된다면 위 3개의 사진을 같은 사진으로 인지한다는 얘기입니다.
맞는 얘기일까요...?
분명 위 3가지 사진은 original의 사진과 다릅니다.
박스칠이 되어 있고,색깔이 다릅니다.
이처럼 사진이 비슷하다고 해서 같은 사진이 아니란 말입니다.
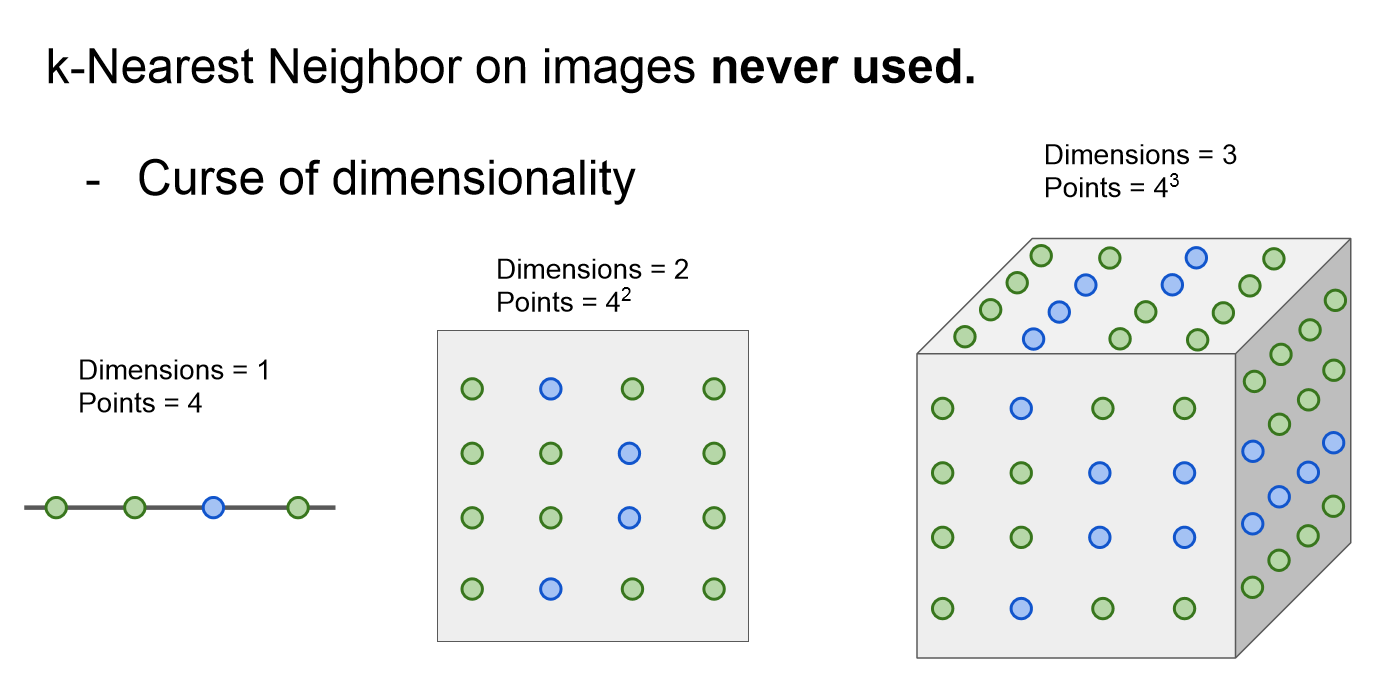
더 큰 문제로는 차원이 넓어질 수록 필요한 데이터의 개수가 굉장히 많아진다는 것입니다.
위 그림을 보겠습니다.
1차원일 때는 4개의 데이터를 필요로 하지만 2차원일 때는 4*4 인 16개의 데이터를 필요로 합니다.
3차원 일 때는 4*4*4인 64개의 데이터를 필요로 하지요.
이렇게 보면 별거아닌 것처럼 느껴질 수가 있는데요
99999의 수가 1차원에서 데이터를 필요로 한다면 99999일 것이고 , 2차원에서 데이터를 필요로 한다면 99999 * 99999 일 것이고 , 3차원에서 데이터를 필요로 한다면 99999 * 99999 * 99999를 필요로 할 것입니다.

어차피 사용안되는 것이지만 왜 배웠는지 의문점이 드실 것입니다...!!
사용이 안되더라도 이미지 분류를 입문할 때의 과정을 배울수 있기 때문입니다.
저희는 지금 다음과 같은 것을 배웠습니다.
이미지 분류를 할 때 트레이닝 이미지와 그에 맞는 각각의 카테고리들이 필요하고 test셋에서 그것을 predict해야 한다는 것을 알게 되었습니다.
K-nearest는 그 카테고리 , 라벨들을 가장 가깝고, 유사한 training 셋의 사진으로 맞춘다는 것 또한 알게 되었습니다.
L1 distance , L2 distance , k 값은 hyperparameter 라는 것도 알았으며 hyperparameter의 값을 고를 때에는
validation 셋에서 골라야 하며 test 셋에서 마지막에 한번 돌려봐야 된다라는 것도 알게 되었습니다.
이처럼 우리는 기본적인 Nearest-Neighbor을 통하여 이미지 분류의 기본적인 것을 익혀본 것이며
어떻게 이루어 지는지를 알게 된 것입니다.
우리가 배운 내용을 토대로 Linear Classification ( 선형 분류 ) 가 무엇인지 새롭게 도전을 해 볼 것입니다.

선형 분류를 하기 위해 우리는 다시 CIFAR10 데이터셋을 불러올 것입니다.
이 데이터셋은 10개의 카테고리로 이루어져 있으며 그에 맞는 사진들이 모여있는 데이터셋입니다.
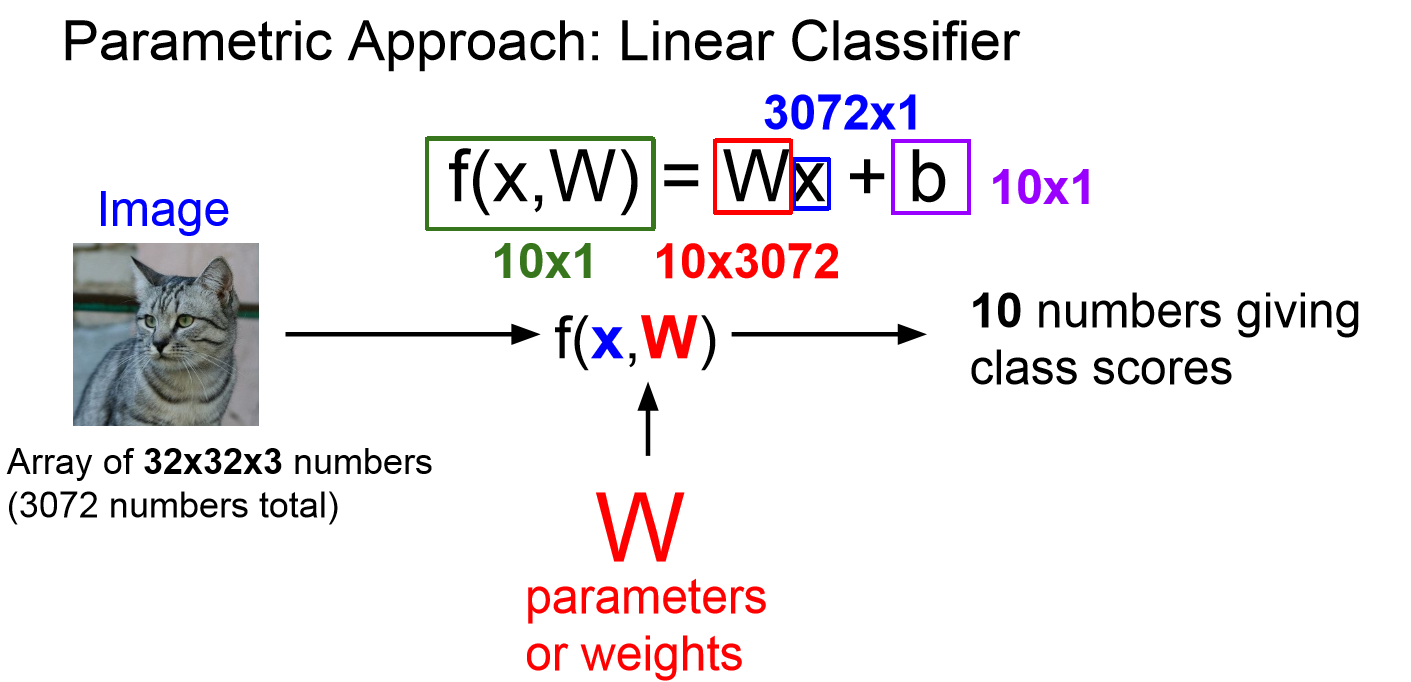
선형 분류는 어떻게 접근해야 할까요??
일단 먼저 이미지가 32 x 32 x 3 ( 가로 x 세로 x RGB ) 개의 숫자들로 이루어져 있다고 생각을 해봅니다.
이미지 크기는 CIFAR10에서의 이미지 크기입니다.
그리고 이 이미지의 크기와 weight(가중치) 라는 변수를 어떠한 특수한 함수에 넣어서 10개의 카테고리에 대한 점수를 구한다면 어떨까요??
위 과정이 Linear Classification 의 Parametic (매개 변수적) 접근 방식입니다.
딱 보았을 때는 괜찮다는 생각이 확 들진 않지만 Nearest-Neighbor 과는 다르게 w값만 가지고 predict를 할 수 있으니 좀 더 간단해 보인다는 생각이 들 수 있을듯합니다!!
한가지 궁금한 점이 생기셨을 겁니다.
그렇다면 저 함수식은 무엇을 의미하는지 말입니다.
일단은 x의 이미지 크기를 평면에 핀다는 의미로 하나의 숫자로 나타내 보겠습니다.
임의로 2000 이라고 하겠습니다 . 그러면 이 2000은 카테고리 별로 2000 * 10 의 크기의 배열이 생성된다고
생각하시면 될 것 같군요.
그리고 이 배열의 값을 W라고 임의로 정해 보겠습니다.
그렇다면 W의 첫번째 줄과 x를 곱하고 W의 두번째 줄과 x를 곱하고 .... 해서 W의 열번째 줄과 x를 곱하여서 10개의 수를 구할 수 있습니다.
이제 b가 남았습니다.
b 또한 카테고리 개수만큼인 1 * 10 의 크기를 만들어 줍니다. 왜냐하면 10가지의 카테고리에 대한 각각의 점수를 구하고 싶기 때문입니다.
그런데 여기서 b의 값은 편향값이라고 해서 특정 이미지가 더 많다고 하였을 때 일종의 보너스라고 하는 점수를 추가로 주는 것입니다.
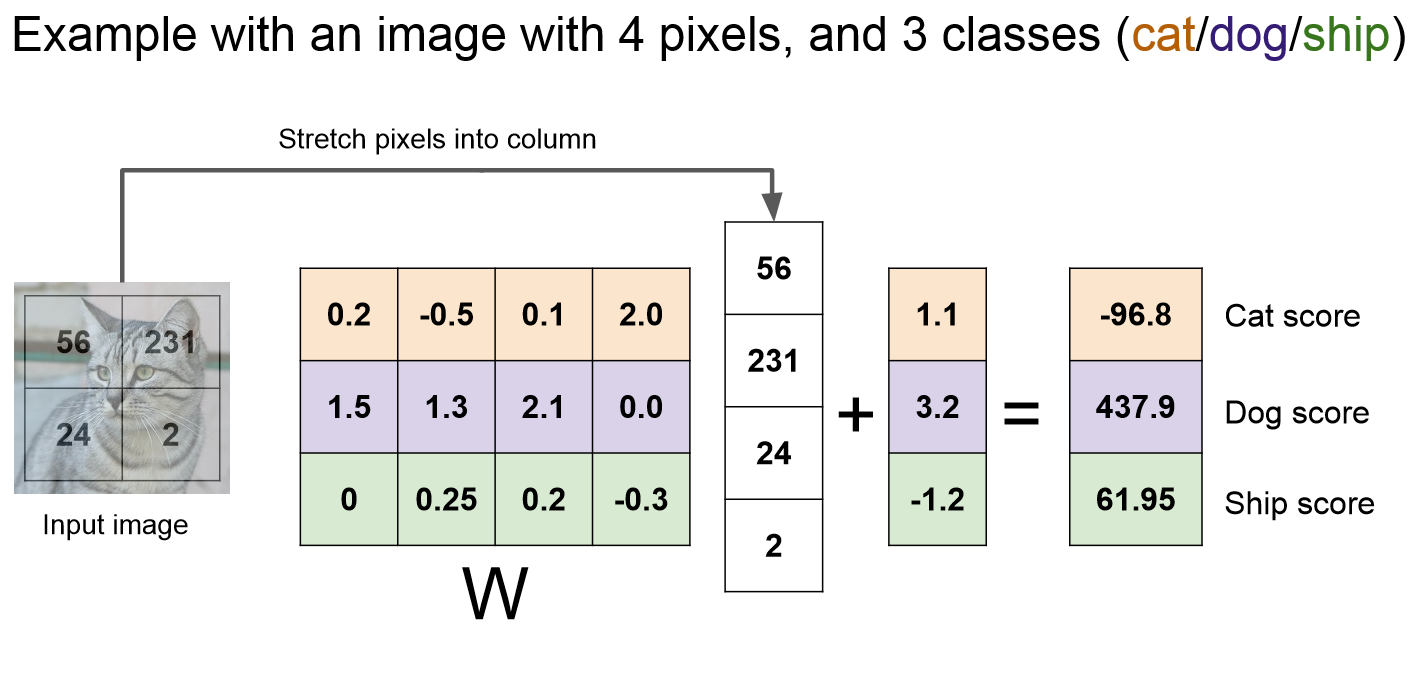
다시 위 사진을 보겠습니다.
위 사진은 앞서 말한 특정함수의 계산법을 도식화하여 그림으로 나타낸 것입니다.
이미지는 2*2 크기의 4개의 픽셀로 단순화된 이미지라고 가정을 할 것이고 세 가지 카테고리의 점수만 알아본다고 가정을 할 것입니다.
그리고 아까 앞서 말한 방법으로 해보겠습니다.
보면, 사진의 크기는 2*2 이기 때문에 1*4 크기로 평평하게 만들어 줍니다.
그리고 나서 (사진의 크기) * (카테고리의 개수) 인 4 * 3 크기의 임의의 W값을 만들어 줍니다.
그 후에 x 와 W 를 곱해주게 되는데 이렇게 곱하는 것을 스칼라 곱 ( Scalar Product ) 또는 점곱 ( Dot Product ) 라고 합니다.
간단하게 고양이의 점수를 계산해 보겠습니다.
첫 번째 줄을 보면 고양이를 나타내는 W값인 0.2,-0.5,0.1,2.0을 각각 x값인 56,231,24,2에 곱해주게 됩니다.
구해 주게 되면 각각 11.2,-111.5,2.4,4.0이 될 것이고 이를 합해준다면 -97.9가 될 것입니다
그 후에 고양이의 bias 값인 1을 더하면 결과적으로 -96.8이 나오고 이것이 바로 위 함수 f(x,W)에서의 고양이의 점수라고 할 수 있습니다.

특정함수에 대해서 자세히 알아보았는데요...!!
확실히 이해가 될 필요는 없습니다 !! 대충 이렇게 되는 거구나 라고 지금은 이해하시면 될것 같구요!
그렇다면 이 과정을 왜 했는지 궁금하실 것입니다!!!

위 그림을 보겠습니다.
위 그림은 CIFAR10 데이터셋에 존재하는 각각의 카테고리들로 훈련된 weight값을 사진으로 표현한 것입니다.
위 그림을 보면 알겠지만 카테고리에 따른 이미지의 모양과 비슷한 모양으로 나온것을 알 수 있습니다.
특히나 car 카테고리는 정말 자동차 처럼 생긴것을 알 수 있습니다.
그러나 말같은 경우에는 어떻게 보이시나요..?
머리가 두개인것 처럼 보이시나요...?
맞습니다.
이 것이 Linear Classification의 문제점 중에 하나인데요.
왼쪽을 보고 있는 말과 오른쪽을 보고 있는 말들이 존재할 텐데 이러한 말들을 하나로 묶어서 점들을 평균을 내 버립니다.
그렇기 때문에 위 사진처럼 머리가 두개인 말의 모습을 띄어주게 됩니다.
이처럼 Linear Classification은 카테고리마다 하나의 결과밖에 내지 못한다는 한계가 있음을 알 수 있습니다.
그러나 이 한계점 치고는 결과가 잘 만들어 짐을 알 수 있습니다.
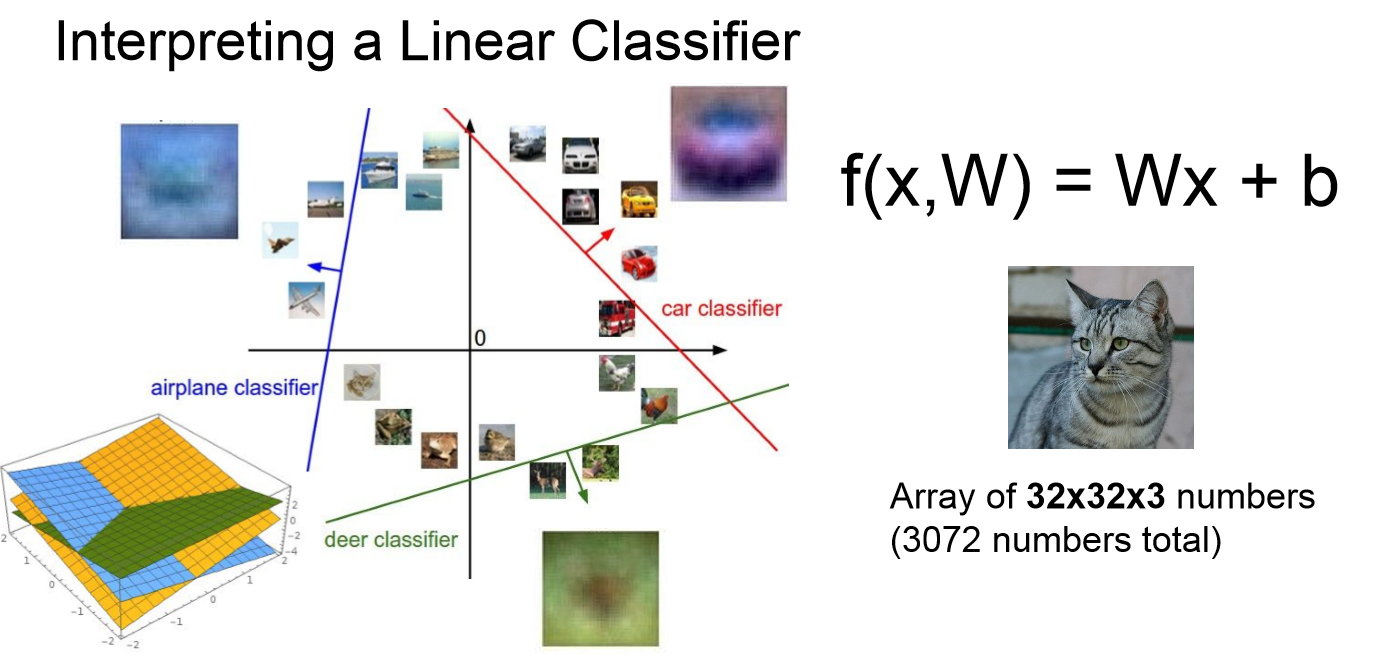
위 얘기를 좀더 알기 쉽게 위 그림처럼 그래프에 놓고 본다면 위 그림이 나올 것입니다.
함수 직선들이 가득한 좌표평면을 확인하실 수 있을 것입니다.
각각의 선 옆에는 비행기,사슴,자동차... 등으로 나누어진다고 말 할 수 있습니다.
실제로 w는 기울기 값을 나타내며 b는 y절편을 나타내므로 많은 사진들이 있는 점들 중에서 최대한 많은 정답을 직선 한쪽으로 몰아넣을 수 있는 w,b값을 정하는 것으로 Linear Classification의 훈련과정이 동작하게 되는 것입니다.
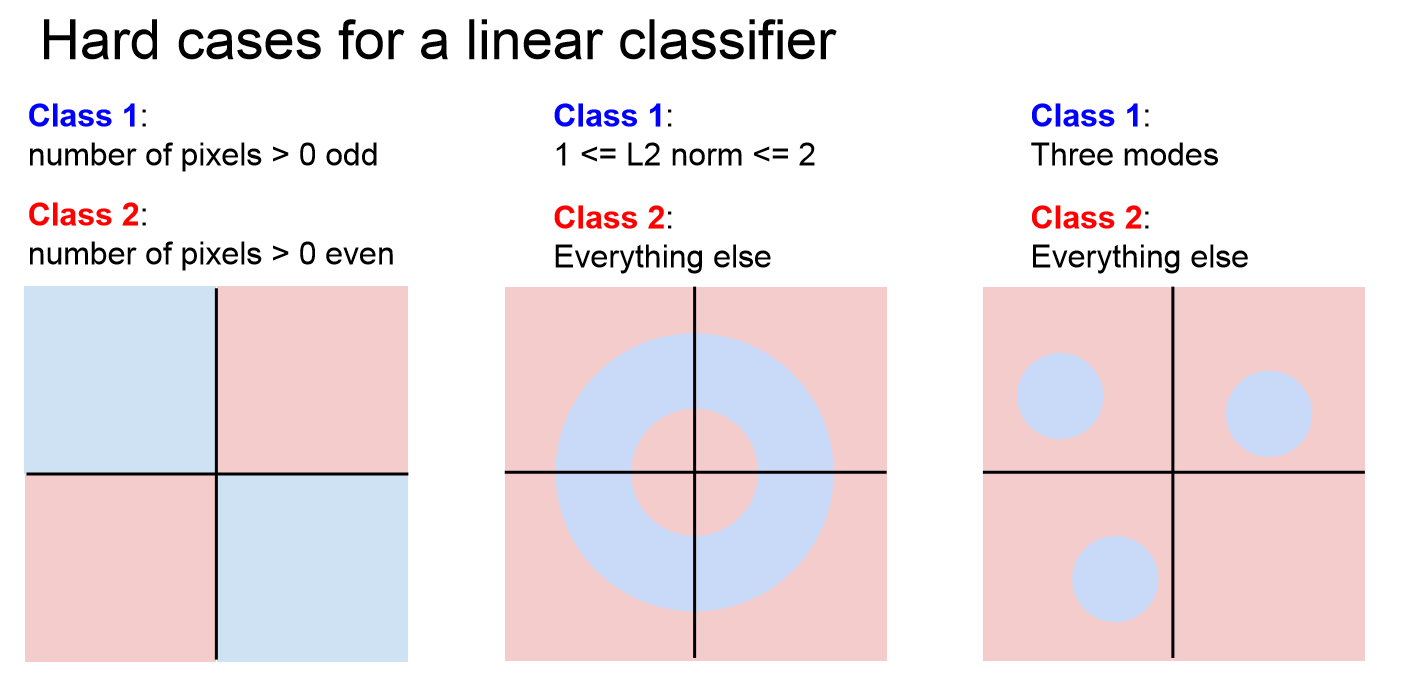
그러나 위 사진처럼 문제점이 발생할 수도 있습니다.
일차함수 직선으로는 제대로 나눌 수 없는 위의 세 가지 경우들이 있을 것입니다.
위 처럼 분포가 되어있다면 어떠한 방법을 사용해도 직선으로는 완벽하게 나눌 수 없을 것입니다.

위 그림을 보겠습니다.
저희가 계산한 값들의 결과가 위처럼 나왔다고 생각을 해보자 이겁니다.
고양이를 보죠.
고양이의 경우 개의 점수가 가장 높고, 고양이는 중위권 정도를 하고 있는데요
정답을 아예 맞추지는 못하였지만, 어느정도는 맞추었다고 할 수 있네요!!
두번째로 자동차를 보겠습니다.
놀랍게도 자동차는 맞추었네요...?? w의 값을 랜덤값으로 두었는데 맞추었다는게
정말 신기한 일입니다!!
마지막으로 개구리를 보겠습니다.
개구리를 보면 정답이 뒤에서 2번째인것을 알 수 있습니다.
성능이 정말 좋지 않군요.
그렇다면 위 결과들을 보았을 때
W의 값을 어떻게 설정해야 하는 것일까요...??

W를 어떻게 설정하는지는 다음 강의를 통해 정리를 해보도록 하겠습니다
'컴퓨터비전' 카테고리의 다른 글
#IT #먹방 #전자기기 #일상
#개발 #일상
-
![[Stanford University CS231n, Spring 2017] Lecture 4 | Introduction to Neural Networks](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FchC31L%2FbtqAQkCGeSR%2FAAAAAAAAAAAAAAAAAAAAAJIVfvi5WdqDbDxqpomLxXpSQYzdDKeh6latEYcaP4h3%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3DiOgfNBCoUbtRMUg4nQp%252F5bhIrWA%253D) [Stanford University CS231n, Spring 2017] Lecture 4 | Introduction to Neural Networks2019.12.30
[Stanford University CS231n, Spring 2017] Lecture 4 | Introduction to Neural Networks2019.12.30 -
![[Stanford University CS231n, Spring 2017] Lecture 3 | Loss Functions and Optimization](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FALLME%2FbtqAErDdTDo%2FAAAAAAAAAAAAAAAAAAAAABVw-QSgd6n4PNIBBnCs8j-F5POmKiEZXhUrPUCMVSvH%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3DZZeIG%252FU6HzfeHRtBlQlKI%252BiFgC0%253D) [Stanford University CS231n, Spring 2017] Lecture 3 | Loss Functions and Optimization2019.12.24
[Stanford University CS231n, Spring 2017] Lecture 3 | Loss Functions and Optimization2019.12.24 -
![[Stanford University CS231n, Spring 2017] Lecture 1 | Introduction to Convolutional Neural Networks for Visual Recognition](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FsWuwb%2FbtqAskX5RX7%2FAAAAAAAAAAAAAAAAAAAAAOXHNrMXtoijKIaPf0juybin-kyxDCi3Fj-NYRxakZmU%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1769871599%26allow_ip%3D%26allow_referer%3D%26signature%3D2Mrt0gAJ47%252BAKJCy8HW%252FCP0DzOc%253D) [Stanford University CS231n, Spring 2017] Lecture 1 | Introduction to Convolutional Neural Networks for Visual Recognition2019.12.02
[Stanford University CS231n, Spring 2017] Lecture 1 | Introduction to Convolutional Neural Networks for Visual Recognition2019.12.02 -
 ModuleNotFoundError: No module named 'torch'2019.09.24
ModuleNotFoundError: No module named 'torch'2019.09.24