

영상처리관련 공부를 시작한지 1주일 정도 되었다.
그럼에도 불구하고 머리에 와닿지가 안아서 코드를 통하여 공부를 해본것을 설명해 보고자 한다.
YOLO란??
YoLo( you only look once ) 는 물체 감지 방법이다.
코드가 이미지에서 객체를 감지하는 방식을 도와주는 알고리즘/전략이다.
이 아이디어의 구현은 DarkNet을 통해 제공되고 있다.
현재 다음 깃허브 주소를 통해서 확인할 수있다.
https://github.com/meenavyas/Misc/tree/master/ObjectDetectionUsingYolo
meenavyas/Misc
Contribute to meenavyas/Misc development by creating an account on GitHub.
github.com
전체 이미지에 단일 신경망을 적용한다. 이 네트워크는 이미지를 영역으로 나누고 각 영역의 경계 상자 및 확률을 예측한다.
이러한 경계 상자는 예측 된 확률로 가중치가 적용된다. 테스트 시간에 전체 이미지를 확인하여
이미지의 글로벌 컨텍스트로 예측을 알린다.
R-CNN 보다 1000배 이상 빠르며 Fast R-CNN보다 100배 빠르다고 한다.
다음은 전체 코드이다.
간략하게 주석을 달아놓았다.
import cv2
import numpy as np
import os
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
IMAGE ="C:/Users/inkim/PycharmProjects/Practice1/Example/돌진.mp4"
CONFIG = "C:/Users/inkim/PycharmProjects/Practice1/Example/yolov3.cfg"
CLASSES = "C:/Users/inkim/PycharmProjects/Practice1/Example/yolov3.txt"
WEIGHTS = "C:/Users/inkim/PycharmProjects/Practice1/Example/yolov3 (1).weights"
# Path Confirm
print(os.path.exists(CLASSES))
print(os.path.exists(CONFIG))
print(os.path.exists(WEIGHTS))
print(os.path.exists(IMAGE))
# read class names from text file
classes = None
with open(CLASSES, 'r') as f:
classes = [line.strip() for line in f.readlines()]
scale = 0.00392
conf_threshold = 0.5
nms_threshold = 0.4
# generate different colors for different classes
COLORS = np.random.uniform(0, 255, size=(len(classes), 3))
# function to get the output layer names
# in the architecture
def get_output_layers(net):
layer_names = net.getLayerNames()
output_layers = [layer_names[i[0] - 1] for i in net.getUnconnectedOutLayers()]
return output_layers
# function to draw bounding box on the detected object with class name
def draw_bounding_box(img, class_id, confidence, x, y, x_plus_w, y_plus_h):
label = str(classes[class_id])
color = COLORS[class_id]
cv2.rectangle(img, (x,y), (x_plus_w,y_plus_h), color, 2)
cv2.putText(img, label, (x-10,y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
def processImage(image, index):
Width = image.shape[1]
Height = image.shape[0]
# read pre-trained model and config file
net = cv2.dnn.readNet(WEIGHTS, CONFIG)
# create input blob
blob = cv2.dnn.blobFromImage(image, scale, (416, 416), (0, 0, 0), True, crop=False)
# set input blob for the network
net.setInput(blob)
# run inference through the network
# and gather predictions from output layers
outs = net.forward(get_output_layers(net))
# initialization
class_ids = []
confidences = []
boxes = []
# for each detetion from each output layer
# get the confidence, class id, bounding box params
# and ignore weak detections (confidence < 0.5)
for out in outs:
for detection in out:
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
if confidence > 0.5:
center_x = int(detection[0] * Width)
center_y = int(detection[1] * Height)
w = int(detection[2] * Width)
h = int(detection[3] * Height)
x = center_x - w / 2
y = center_y - h / 2
class_ids.append(class_id)
confidences.append(float(confidence))
boxes.append([x, y, w, h])
# apply non-max suppression
indices = cv2.dnn.NMSBoxes(boxes, confidences, conf_threshold, nms_threshold)
# go through the detections remaining
# after nms and draw bounding box
for i in indices:
i = i[0]
box = boxes[i]
x = box[0]
y = box[1]
w = box[2]
h = box[3]
draw_bounding_box(image, class_ids[i], confidences[i], round(x), round(y), round(x + w), round(y + h))
# display output image
out_image_name = "object detection" + str(index)
# cv2.imshow(out_image_name, image)
# wait until any key is pressed
# cv2.waitKey()
# save output image to disk
cv2.imwrite("C:/Users/inkim/Desktop/Object detection/object-detection-opencv-master/object-detection-opencv-master/Sample2" + out_image_name + ".jpg", image)
# open the video file
cap = cv2.VideoCapture(IMAGE)
print(cap)
index = 0
while (cap.isOpened()):
ret, frame = cap.read()
if type(frame) == type(None):
break
processImage(frame, index)
index = index + 1
# release resources
cv2.destroyAllWindows()
yolo를 통하여 객체 식별을 맛보기로 알아 보았는데.
Yolo를 통한 객체 식별을 하기 위해서는 다음과 같은 것들이 필요했다.
동영상파일
Config file
클래스분류되어진txt파일
가중치를 주는 weight
동영상 길이는 대략 2초 정도 된 mp4파일을 사용하여 돌려보았다.
동영상은 다음과 같다.
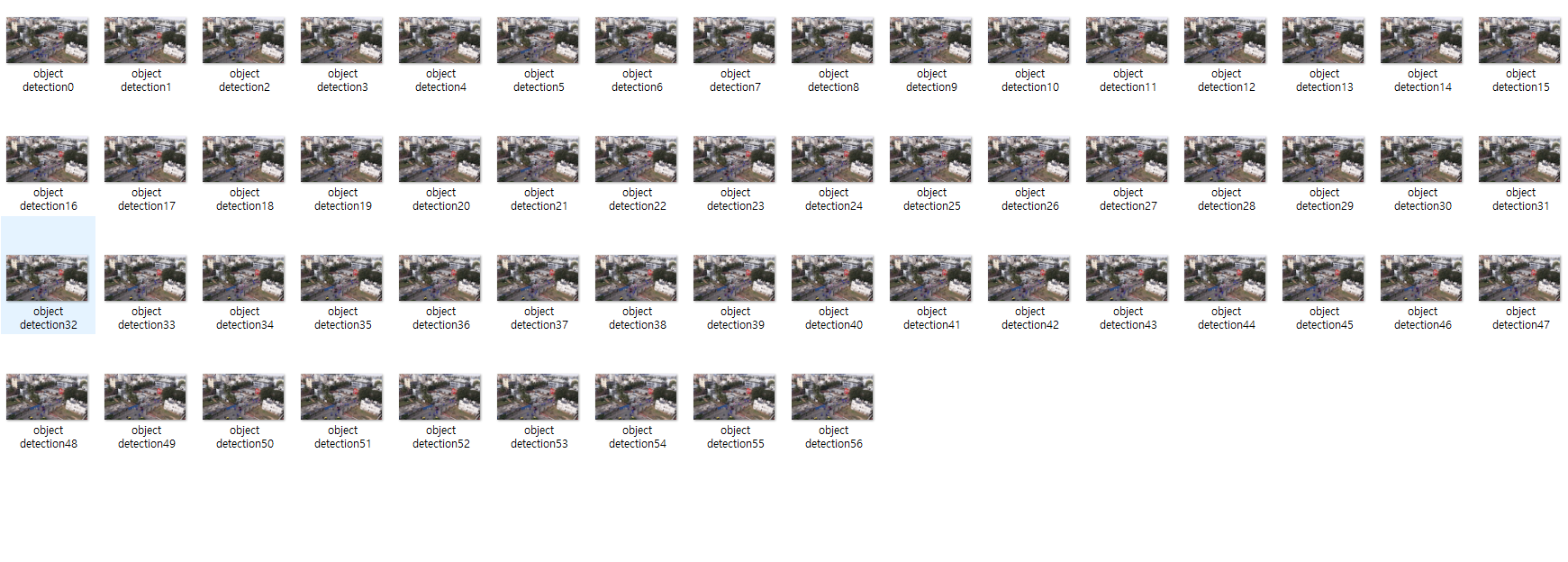
저장되어진 사진갯수는 56개 였다.
다음그림처럼 동영상내에 있는 객체를 식별함을 알 수 있었다.

다음그림처럼 모든 객체를 식별하지는 못하였다.

'컴퓨터비전' 카테고리의 다른 글
#IT #먹방 #전자기기 #일상
#개발 #일상
-
![[Stanford University CS231n, Spring 2017] Lecture 1 | Introduction to Convolutional Neural Networks for Visual Recognition](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FsWuwb%2FbtqAskX5RX7%2F2RaGmbqU7I1SANa6P08R6k%2Fimg.png) [Stanford University CS231n, Spring 2017] Lecture 1 | Introduction to Convolutional Neural Networks for Visual Recognition2019.12.02
[Stanford University CS231n, Spring 2017] Lecture 1 | Introduction to Convolutional Neural Networks for Visual Recognition2019.12.02 -
 ModuleNotFoundError: No module named 'torch'2019.09.24
ModuleNotFoundError: No module named 'torch'2019.09.24 -
 AttributeError: 'NoneType' object has no attribute 'shape'2019.09.23
AttributeError: 'NoneType' object has no attribute 'shape'2019.09.23 -
 cv2.error: OpenCV(4.1.1) C:\projects\opencv-python\opencv\modules\highgui\src\window.cpp:621: error: (-2:Unspecified error) The function is not implemented. Rebuild the library with Windows, GTK+ 2.x or Cocoa support. If you are on Ubuntu or Debian, ins..2019.09.23
cv2.error: OpenCV(4.1.1) C:\projects\opencv-python\opencv\modules\highgui\src\window.cpp:621: error: (-2:Unspecified error) The function is not implemented. Rebuild the library with Windows, GTK+ 2.x or Cocoa support. If you are on Ubuntu or Debian, ins..2019.09.23