
K-NN 분류기와 KNeighborsClassifier analysis를 코드를 통해서 어떠한 결과값이 나오고 ,
어떻게 나오는지 자세히 알아볼 것이다 .
코드를 통해서 확인해 보자 .
import mglearn
import matplotlib.pyplot as plt
--> mglearn과 matplotlib를 import를 한다 . 그래프 , 시각화 라이브러이다.
# Forge 데이터를 사용해서 , mglearn을 사용해 본다 .
# 여기서 mglearn이란 : 그래프나 데이터 적재와 관련한 세세한 코드를 일일이 쓰지 않아도
# 되게끔 해준다.
# 간단하게 그림을 그리거나 필요한 데이터를 바로 불러들이기 위해서 사용한다 .
X, y = mglearn.datasets.make_forge()
먼저 , forge데이터셋을 사용하여 , X,y로 나눈다 .
plt.figure(1)
mglearn.plots.plot_knn_classification(n_neighbors=1)
--> plt.figure를 사용해 주는 이유는 plt에 찍어서 한번에 show를 해주기 위함이다 .
--> n_neighbors가 1일 때 이다.

plt.figure(2)
mglearn.plots.plot_knn_classification(n_neighbors=3)
--> plt.figure2로 지정해 주며 , n_neighbors=3일 때를 plot해 본다 .

plt.show()
# plt에 show를 해주는 이유는 , plt에 찍어준 그래프를 모두 출력해 준다 .
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
--> 지도학습에 필요한 라이브러리와 그 라이브러리를 사용하여서 , 훈련용과 테스트로 나눈다.
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=3)
--> 이웃의 수 ( 매개변수 ) 를 3으로 지정해 준다 .
이제는
훈련 세트를 사용하여서 , 분류 모델을 학습시킨다.
KNeighborsClassifier에서의 학습은 예측할 때 , 이웃을 찾을 수 있도록 데이터를 저장하는 것이다.
clf.fit(X_train, y_train)
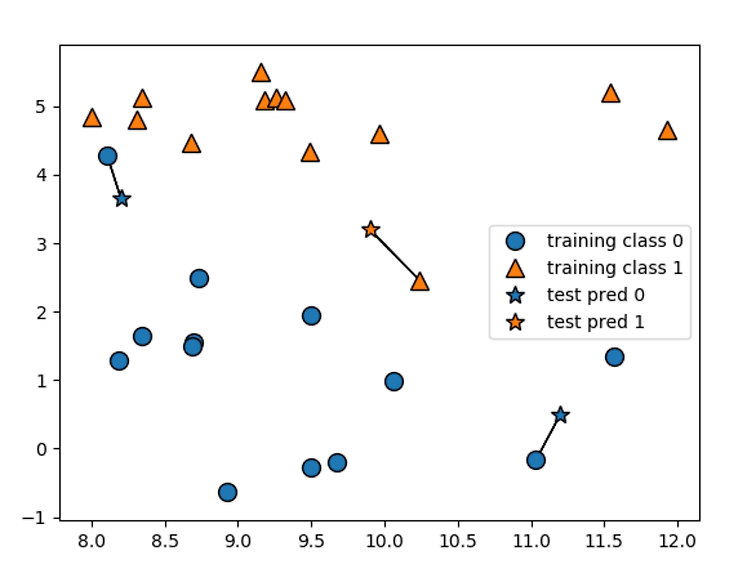
print("Test set prediction: {}".format(clf.predict(X_test)))
print("Test set accuracy: {:.2f}".format(clf.score(X_test, y_test)))
-->
테스트 데이터에 대해 predict 메서드를 호출해서 예측을 한다.
테스트 세트의 각 데이터 포인트에 대해 훈련 세트에서 가장 가까운 이웃을 계산한 다음 가장 많은 클래스를 찾는다 .
결과값을 보면 다음과 각각 같다.
Test set prediction: [1 0 1 0 1 0 0]
Test set accuracy: 0.86
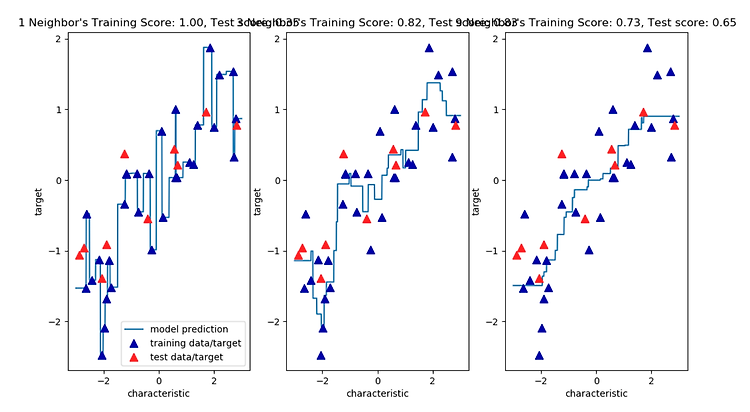
KNeighborsClassifier analysis
2차원 데이터셋이므로 가능한 모든 테스트 포인트의 예측을 xy평면에 그려볼 수 있다.
그리고 각 데이터 포인트가 속한 클래스에 따라 평면에 색을 칠한다.
이렇게 하면 알고리즘이 클래스 0과 클래스 1로 지정한 영역으로 나뉘는 결정 경계를 볼 수 있다.
다음은 , 이웃이 하나 , 셋 , 아홉 개일 때의 결정 경계를 보여준다.
fig, axes = plt.subplots(1, 3, figsize=(10, 3))
for n_neighbors, ax in zip([1, 3, 9], axes):
# fit 메소드는 self 오브젝트를 리턴합니다
# 그래서 객체 생성과 fit 메소드를 한 줄에 쓸 수 있습니다
clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X, y)
mglearn.plots.plot_2d_separator(clf, X, fill=True, eps=0.5, ax=ax, alpha=.4)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax)
ax.set_title("{} neighbors".format(n_neighbors))
ax.set_xlabel("characteristic 0")
ax.set_ylabel("characteristic 1")
axes[0].legend(loc=3)
plt.show()
위의 plt를 실행해 보면 , 이웃을 하나 선택했을 때는 결정 경계가 훈련 데이터에 가깝게 따라가고 있는것을 확인할 수 있다.
이웃의 수를 늘릴수록 결정 경계는 더 부드러워 진다.
부드러운 경계는 더 단순한 모델을 의미한다.
즉 , 이웃을 적게 사용하면 모델의 복잡도가 높아지고 , 많이 사용하면 복잡도는 낮아진다.
훈련 데이터 전체 개수를 이웃의 수로 지정하는 극단적인 경우에는 모든 테스트 포인트가 같은 이웃을 가지게
되므로 테스트 포인트에 대한 예측은 모두 같은 값이 된다 .
훈련 세트에서 가장 많은 데이터 포인트를 가진 클래스가 예측값이 된다 .
결과값은 다음과 같다.

'학부공부 > 빅데이터기술' 카테고리의 다른 글
| KNeighbors 장단점과 매개변수 (0) | 2019.04.07 |
|---|---|
| KNeighborsRegressor Analysis (0) | 2019.04.07 |
| 지도학습..? (0) | 2019.04.02 |
| K-최근접 이웃 분류 (0) | 2019.03.28 |
| CancetDataset을 이용해서 복잡도와 일반화관계알아보기 (0) | 2019.03.28 |
#IT #먹방 #전자기기 #일상
#개발 #일상