
Iris Dataset은 머신러닝을 연습하기 위한 좋은 예제이다 .
코드를 통해서 알아보자 .
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import pandas as pd
import mglearn
import matplotlib.pyplot as plt
위 코드는 머신러닝을 통하여서 , 시각화할 것인데 , 이 때 필요한 패키지들이다 .
sklearn이 메인 library이다 .
pandas는 데이터들을 데이터프레임으로 만들 때 사용할 것이고 ,
mglearn 과 matplotlib 은 가공한 데이터를 시각화 할 때 사용한다 .
본격적으로 확인해 보자 .
다음은 iris dataset을 로딩하는 부분이다.
iris_dataset = load_iris()다음은 irs의 data를확인해 보기 위해 해본 작업인데 ,
특이점은 .keys로써 특성들을 가져올 수 있다는 것이고
그 특성중 특정 데이터만 가져오고 싶다면 이중배열형태로써 가져올 수 있다 .
# 데이터셋에 대한 설명 , iris_dataset.DESCR[:193] 도 가능하다 .
print("iris_dataset의 키 : {}".format(iris_dataset.keys()))
print(iris_dataset['DESCR'][:193] + "|n...")
위의 실행 화면은 다음과 같다 .
iris_dataset의 키 : dict_keys(['data', 'target', 'target_names', 'DESCR', 'feature_names', 'filename'])
.. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, pre|n...
keys를 통해서 특성값들을 가져오는 것을 확인 가능하다 .
위와 같이 다른 특성들을 읽어오는 작업을 해본다 .
# 붓꽃 품종의 이름
print("타깃의 이름 : {}".format(iris_dataset['target_names']))
# 특성 설명
print("특성의 이름: {}".format(iris_dataset['feature_names']))
# data의 타입
print("data의 타입: {}".format(type(iris_dataset['data'])))
# data의 크기
print("data의 크기: {}".format(iris_dataset['data'].shape))
특성의 이름과 , 타입 , 크기를 가져오는 방법을 익혀보면 된다 .
타입은 type 을 사용해서 , 크기는 shape 를 사용한다는 것을 익힌다 .
위의 결과 값
타깃의 이름 : ['setosa' 'versicolor' 'virginica']
특성의 이름: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
data의 타입: <class 'numpy.ndarray'>
data의 크기: (150, 4)
# data의 처음 다섯 행 :
print("data의 처음 다섯 행 : \n{}".format(iris_dataset['data'][:5]))
위는 data라는 특성의 5번쨰까지 행을 가져온다는 것을 의미한다 .
위의 결과 값
data의 처음 다섯 행 :
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]
다음은 target의 타입 , 크기 , 데이터를 가져오는 것이다.
# target의 타입
print("target의 타입: {}".format(type(iris_dataset['target'])))
# target의 크기
print("target의 크기: {}".format(iris_dataset['target'].shape))
# target의 데이터
print("타깃: \n{}".format(iris_dataset['target']))
위 결과 값
여기서 특이점은 , 타입이 numpy.ndarray 형태라는 것이다 .
자세한건 나중에 알아보고 , numpy형태이며 배열형태라는 것이고 ,
3D array까지 지원한다고 한다 .
target의 타입: <class 'numpy.ndarray'>
target의 크기: (150,)
타깃:
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
이제 ,
from sklearn.model_selection import train_test_split
위를 사용해서 학습을 해볼 것인데 ,
이 때 , 훈련 데이터와 테스트 데이터로 나뉜다 .
훈련에 사용한 데이터는 테스트 ( 일반화 ) 에 사용하지 않는다 .
데이터 분리 : 훈련 세트 , 테스트 세트
X ( 2차원 배열 - 행렬 , 대문자 )
Y ( 1차원 배열 - 벡터 , 소문자 )
먼저 , 다음처럼 data와 target의 값을 기반으로 데이터를 분리하는 과정이며 , random_state 는 랜덤 시드를 의미한다 .
X_train, X_test, y_train, y_test = train_test_split(iris_dataset['data'],
iris_dataset['target'],
random_state=0
)
위처럼 나눈 데이터 값을 확인해 주기 위해 아래를 통해서 확인해 본다
# X , Y train 크기
print("X_train 크기 : {}".format(X_train.shape))
print("y_train 크기 : {}".format(y_train.shape))
# X,Y test 크기
print("X_test 크기: {}".format(X_test.shape))
print("y_test 크기: {}".format(y_test.shape))
아래는 결과값
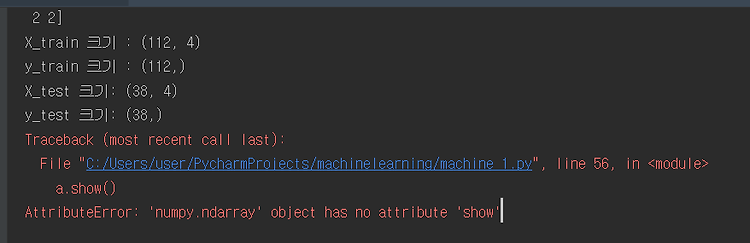
X_train 크기 : (112, 4)
y_train 크기 : (112,)
X_test 크기: (38, 4)
y_test 크기: (38,)
--> 이를 통해서 알 수 있는 것은 나눌 때 , 3:1 비율로 "훈련용 : 테스트"를 나눈다 .
이제 , 위 값을 기반으로 시각화를 해볼 것이다 .
시각화에 필요한 library는 다음과 같다.
import pandas as pd
import mglearn
import matplotlib.pyplot as plt
다음은 , X_train 데이터를 사용해서 데이터프레임을 만들고 , y_train 에 따라 색이 구분되는 산점도를 만드는 코드이다.
# X_train 데이터를 사용해서 데이터프레임을 만든다
# 열의 이름은 iris_dataset.feature_name에 있는 문자열을 사용한다
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
# 데이터프레임을 사용해서 y_train에 따라 색으로 구분된 산점도 행렬을 만든다
pd.plotting.scatter_matrix(iris_dataframe, c= y_train, figsize=(15,15),
marker ='0', hist_kwds={'bins': 20}, s=60, alpha=.8, cmap=mglearn.cm3)
plt.show()
보면 , plt.show() 라는게 있을 것이다 이것은 matplotlib.pyploy에 포함된 library이다 .
다음은 plt.show없이 코드를 돌렸을 때 , 산점도 그래프가 뜨지 않아서 , a라는 변수에 값을 넣어주고
a.show 를 했더니 오류가 떴다 .
보니까 , numpy.ndarray는 show가 아니라 , plt를 사용해서 show를 해주면 된다는 것을 알게 되었다 .
이 때 , plt.show는 만든 모든 plt를 show 해주는 기능을 한다.

다음은 산점도를 출력해 본 결과이다 .
꽃의 종류에 따라 색깔이 다르게 찍히며 , 분포를 확인할 수 있으며 , 관계를 알 수 있다.

'학부공부 > 빅데이터기술' 카테고리의 다른 글
| Dataset들을 사용해 보자 (0) | 2019.03.28 |
|---|---|
| 분류 ( classification ) 와 회귀 ( regression ) (0) | 2019.03.26 |
| 머신러닝이란?? (0) | 2019.03.23 |
| 데이터 과학이란?? (0) | 2019.03.16 |
| 머신러닝 프로젝트 과정 (0) | 2019.03.16 |
#IT #먹방 #전자기기 #일상
#개발 #일상