
분류 ( classification ) 와 회귀 ( regression )
1. 분류는 가능성 있는 클래스 레이블 중 하나를 예측
è 이진 분류 ( binary classification ) : 두 개의 클래스 분류
è 다중 분류 ( multiclass classification ) : 셋 이상의 클래스 분류 ( 붓꽃 품종 )
è 언어의 종류를 분류 ( 한국어와 프랑스어 사이에 다른 언어가 없다 )
2. 회귀는 연속적인 숫자(실수)를 예측
è 교육, 나이, 주거지를 바탕으로 연간 소득 예측
è 전년도 수확량, 날씨, 고용자수로 올해 수확량 예측
è 예측 값에 미묘한 차이가 크게 중요하지 않음
3. 일반화, 과대적합, 과소적합
è 일반화 ( generalization ) : 훈련 세트로 학습한 모델을 테스트 세트에 적용하는 것
è 과대적합 ( overfitting ) : 훈련 세트에 너무 맞추어져 있어 테스트 세트의 성능이 저하
è 과소적합 ( underfitting ) 훈련 세트를 충분히 반영하지 못해 훈련 세트 , 테스트 세트에서 모두 성능 저하
4. 모델 복잡도 곡선

훈련 세트를 통해서 , 일반화를 할 때 , 최적점이 존재하게 되는데 , 이 최적점에서 정확도를 최대화 할 수 있다.
5. 데이터셋과 복잡도 관계
è 데이터가 많으면 다양성이 커져 복잡한 모델을 만들 수 있다.
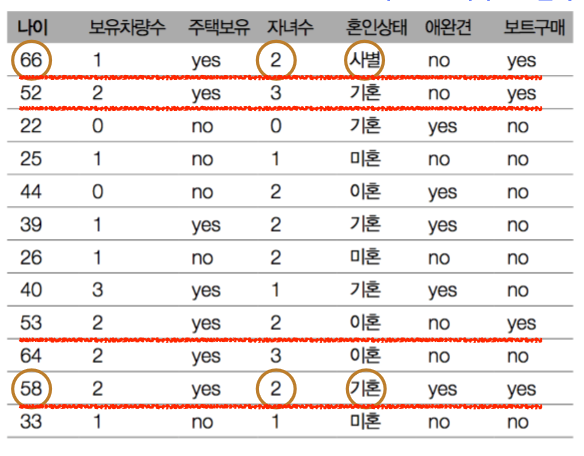
è 10,000명의 고객 데이터에서 45세 이상 , 자녀 셋 미만 , 이혼하지 않은 고객이 요트를 사려한다면 이전보다 훨씬 신뢰 높은 모델이다.

6. K-최근접 이웃 분류
è 새로운 데이터 포인트에 가까운 이웃 중 다수 클래스(majority voting)가 예측이 된다 .
è Forge 데이터셋에 1 : 최근접 이웃 , 3 : 최근접 이웃 적용
이 부분은 코드를 통해서 확인해 보겠다.
import mglearn
import matplotlib.pyplot as plt
X, y = mglearn.datasets.make_forge()
plt.figure(1)
mglearn.plots.plot_knn_classification(n_neighbors=1)
plt.figure(2)
mglearn.plots.plot_knn_classification(n_neighbors=3)
plt.show()
아주 간단하게 , neighbors = 1 일 때와 n_neighbors = 3일 때로 나누어서 확인해 본다 .

--> neighbors = 1일 때

--> neighbors = 3일 때
7. K-NN 분류기
이 부분 또한 코드를 통해서 확인해 본다 .
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=3)
clf.fit(X_train, y_train)
print("Test set prediction: {}".format(clf.predict(X_test)))
print("Test set accuracy: {:.2f}".format(clf.score(X_test, y_test)))
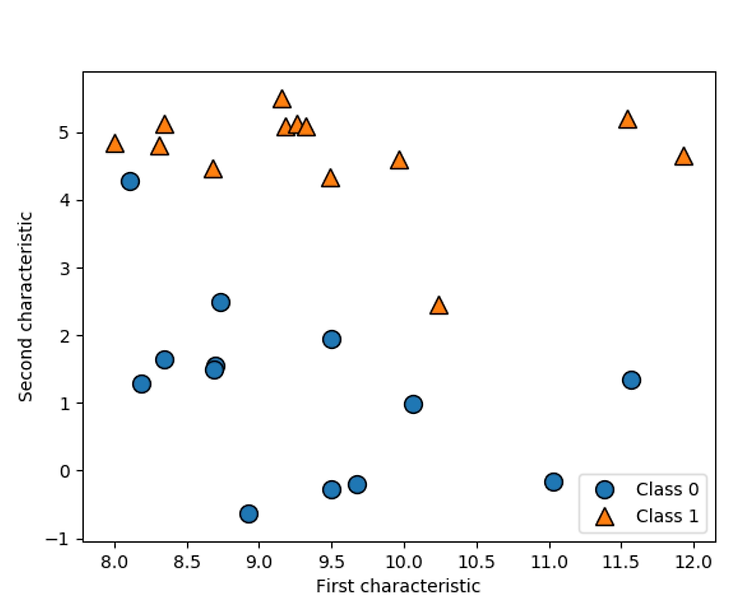
fig, axes = plt.subplots(1, 3, figsize=(10, 3))
for n_neighbors, ax in zip([1, 3, 9], axes):
# fit 메소드는 self 오브젝트를 리턴합니다
# 그래서 객체 생성과 fit 메소드를 한 줄에 쓸 수 있습니다
clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X, y)
mglearn.plots.plot_2d_separator(clf, X, fill=True, eps=0.5, ax=ax, alpha=.4)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax)
ax.set_title("{} neighbors".format(n_neighbors))
ax.set_xlabel("characteristic 0")
ax.set_ylabel("characteristic 1")
axes[0].legend(loc=3)
plt.show()

위는 neighbors가 1 일 때 , 3 일 때 , 9 일 때
일정한 간격으로 생성한 생성한 포인트의 예측 값을 이용해 , 결정 경계 구분한다 .
8 . k-NN 분류기의 모델 복잡도
이 부분 또한 코드를 통해서 확인해 본다 .
from sklearn.datasets import load_breast_cancer
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
import mglearn
import matplotlib.pyplot as plt
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state=66)
training_accuracy = []
test_accuracy = []
# 1에서 10까지 n_neighbors를 적용
neighbors_settings = range(1, 11)
for n_neighbors in neighbors_settings:
# 모델 생성
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X_train, y_train)
# 훈련 세트 정확도 저장
training_accuracy.append(clf.score(X_train, y_train))
# 일반화 정확도 저장
test_accuracy.append(clf.score(X_test, y_test))
plt.plot(neighbors_settings, training_accuracy, label="Training Accuracy")
plt.plot(neighbors_settings, test_accuracy, label="Test Accuracy")
plt.ylabel("accuracy")
plt.xlabel("n_neighbors")
plt.legend()
plt.show()
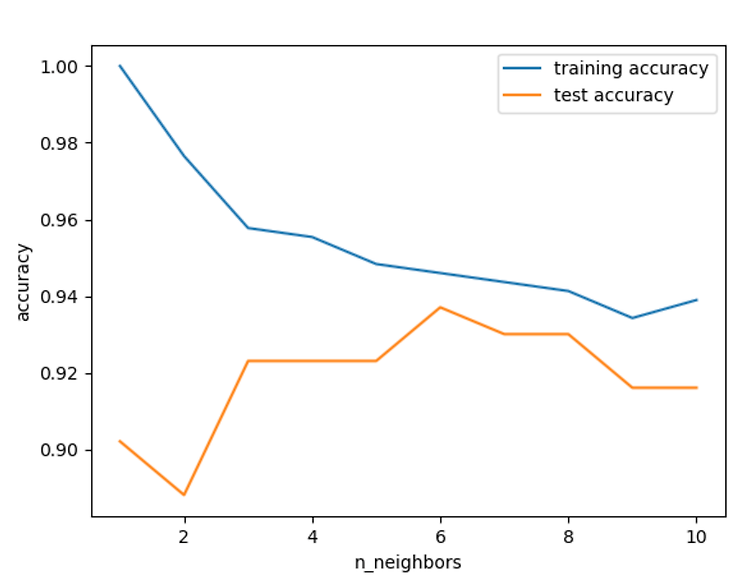
결과 값은 다음과 같다 .

위 결과를 통해서알 수있는 것은 앞에서 다룬 overfitting 과 underfitting 의 위치를 알아 놓으면 된다.
왼쪽에서 training 과 test의 격차가 굉장히 큰데 , 이 때 overfitting 된다 라고 한다.
반면에 오른쪽에는 training과 test의 격차가 굉장히 작은데 , 이 때 underfitting이라고 한다 .
test가 6에 있을 때 , 이때를 최적점이라고 한다 .
'학부공부 > 빅데이터기술' 카테고리의 다른 글
| CancetDataset을 이용해서 복잡도와 일반화관계알아보기 (0) | 2019.03.28 |
|---|---|
| Dataset들을 사용해 보자 (0) | 2019.03.28 |
| Iris Dataset을 다뤄보자 . (0) | 2019.03.23 |
| 머신러닝이란?? (0) | 2019.03.23 |
| 데이터 과학이란?? (0) | 2019.03.16 |
#IT #먹방 #전자기기 #일상
#개발 #일상