머신러닝이란 ?
1. 데이터에서 지식을 추출하는 작업
2. 통계학, 인공지능, 컴퓨터 과학이 어우러진 연구분야
3. 예측 분석이나 통계적 머신러닝으로도 불림
딥러닝 , 머신러닝 , AI 포함관계
딥러닝 < 머신러닝 < AI
머신러닝에는 지도학습과 비지도학습이 존재한다 .
지도 학습 ( Supervised Learning )
1. 알고리즘에 입력과 기대하는 출력을 제공
2. 알고리즘은 입력으로 부터 기대하는 출력을 만드는 방법을 찾음
비지도 학습 ( Unsupervised Learning )
1. 알고리즘에 입력은 주어지지만 출력은 제공되지 않음
2. 따라서 비지도 학습의 성공을 평가하기 어려움
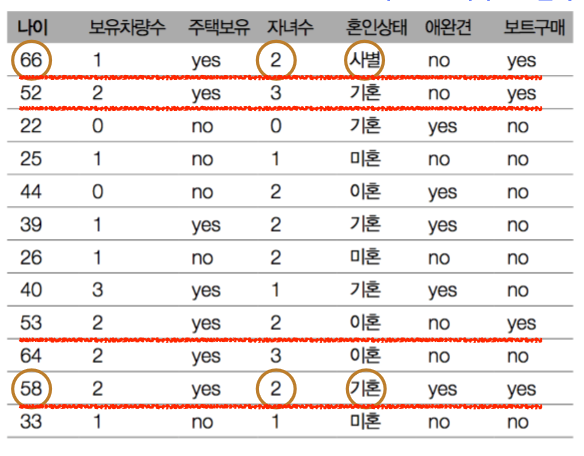
데이터와 특성
다음과 같은 데이터가 있을 때, [나이,성별,구매빈도,이메일]은 특성(features) = 속성이라고 함
[27,남,10,qweqwe@naver.com]은 샘플 = 데이터 포인트 라고 함
|
나이 |
성별 |
구매빈도 |
이메일 |
|
27 |
남 |
10 |
qweqwe@naver.com |
문제와 데이터 이해
알고리즘마다 잘 들어맞는 데이터나 문제의 종류가 다르다 .
1. 어떤 질문에 대답을 원하는가 ? 원하는 답을 만들 수 있는 데이터를 가지고 있는가?
2. 어떻게 머신러닝의 문제로 가장 잘 기술할 수 있는가?
3. 충분한 데이터가 있는가?
4. 좋은 예측을 위한 특성을 가지고 있는가?
5. 애플리케이션의 성과를 어떻게 측정할 것인가?
6. 다른 연구나 제품에 어떤 영향이 있는가 ?
Python 주도 딥러닝 라이브러리 : TensorFlow , PyTorch , Theano …
Scikit-Learn
1. 회귀 , 분류 , 군집 , 차원축소 , 특성공학 , 전처리 , 교차검증 , 파이프라인 등 머신러닝에 필요한 도구를 두루 갖춤
2. 오픈소스 : https://github.com/scikit-learn/scikit-learn
3. Numpy , SciPy를 기반으로 한다.
4. Numpy : 다차원 배열 , 선형 대수 , 다양한 수학 함수 , 난수 생성기 포함
5. Scikit-learn의 기본 데이터 구조
6. Scipy : 선형 대수 , 최적화 , 통계 등 많은 과학 계산 함수를 모아놓은 파이썬 패키지
è Scikit-learn은 알고리즘 구현에 SciPy에 많이 의존한다 .
è 0이 많이 포함된 행렬을 효율적으로 표현하기 위한 희소 행렬 scipy.sparse 패키지 주요하게 사용한다 .
7. Matplotlib : 과학 계산용 그래프 라이브러리선 , 히스토그램 , 산점도 등 다양한 그래프
8. Pandas : 데이터 처리와 분석을 위한 라이브러리 , DataFrame inspired by R’s data.frame엑셀과 비슷하다 , numpy와 달리 이중 데이터 포함 가능
'학부공부 > 빅데이터기술' 카테고리의 다른 글
| Dataset들을 사용해 보자 (0) | 2019.03.28 |
|---|---|
| 분류 ( classification ) 와 회귀 ( regression ) (0) | 2019.03.26 |
| Iris Dataset을 다뤄보자 . (0) | 2019.03.23 |
| 데이터 과학이란?? (0) | 2019.03.16 |
| 머신러닝 프로젝트 과정 (0) | 2019.03.16 |
#IT #먹방 #전자기기 #일상
#개발 #일상