
오늘은 구글에서 비정상트래픽을 검사한 뒤 , 서칭된 결과들을 바탕으로 ,
본문기사의 url을 가져와서 , 그 url에 해당하는 논문의 초록을 가져와 볼 것이다.
먼저 , 구글에 “비정상트래픽”을 검색해 본다
검색해 보면 , 비정상트래픽에 관련된 , 또는 이 단어가 포함된 결과들이 나올 것이다.
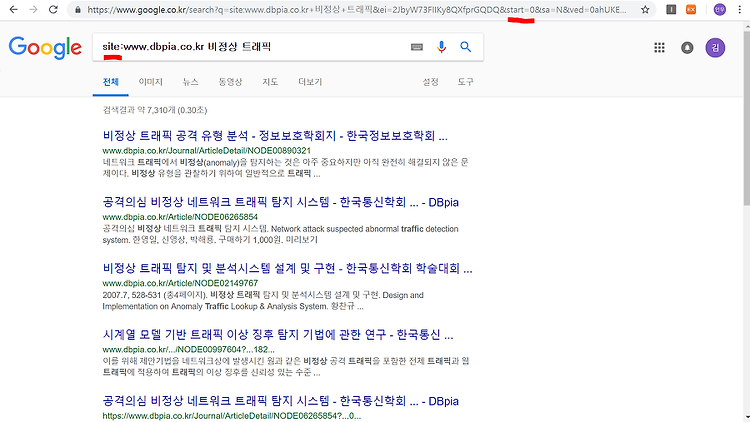
나는 특정 사이트를 기준으로 검색해 보고 싶었다.
그래서 site:www.dbpia.co.kr 비정상 트래픽 으로 검색을 해보았다.

검사결과는 위의 그림처럼 , 내가 검색하고자 하는 사이트별로 , 검색결과들이 추출된 것을 확인할 수 있었다.
그리고 주소를 보면 구글은 start 변수가 page 이동 변수인 것을 알 수 있었다.
특이한 점은 구글은 page의 이동이 있을 경우에 , page 이동값이 10씩 증가하는 것을 알 수가 있었다.

이렇게 해서 구글에서 특정 사이트를 기반으로 검색을 하는 것과 페이지의 이동 변수가 무엇인지 알 수 있다.
그러면 이제 코드를 통해서 어떻게 크롤링을 할 것이며 , 이 크롤링 값들을 csv파일로 어떻게 저장시키는지 확인해 보자
library(rvest)
library(dplyr)
library(XML)
우선 위의 이 작업을 하기 위한 위 library를 로딩시켜 준다.
우리는 1~5페이지 까지의 검색결과들을 다룰 것이다 .
그렇기 때문에 주소를 2개로 나누어서 각각 별도의 변수를 만들어서 다룰 필요를 느낀다.
First_url <- "https://www.google.co.kr/search?q=site:www.dbpia.co.kr+%EB%B9%84%EC%A0%95%EC%83%81+%ED%8A%B8%EB%9E%98%ED%94%BD&ei=2JbyW73FIIKy8QXfprGQDQ&start="
# start를 기준으로 앞 주소
Second_url <- "&sa=N&ved=0ahUKEwi9kebxpeDeAhUCWbwKHV9TDNIQ8tMDCEI&biw=1218&bih=650&dpr=1.5"
# start를 기준으로 뒤 주소
urls <- NULL
# 완전한 url의 주소값을 저장시킬 변수
for(num in 1:5)
{
urls[num] <- paste0(First_url,as.character(num*10),Second_url)
}
è 1~5페이지의 주소값들을 가져올 것이며 , 여기서 중요하게 볼 곳은 , num*10이다
è 왜냐하면 페이지의 이동이 10씩 증가하는 것을 알 수가 있었기 때문이다.
Urls의 결과값
> urls
[1] "https://www.google.co.kr/search?q=site:www.dbpia.co.kr+%EB%B9%84%EC%A0%95%EC%83%81+%ED%8A%B8%EB%9E%98%ED%94%BD&ei=2JbyW73FIIKy8QXfprGQDQ&start=10&sa=N&ved=0ahUKEwi9kebxpeDeAhUCWbwKHV9TDNIQ8tMDCEI&biw=1218&bih=650&dpr=1.5"
[2] "https://www.google.co.kr/search?q=site:www.dbpia.co.kr+%EB%B9%84%EC%A0%95%EC%83%81+%ED%8A%B8%EB%9E%98%ED%94%BD&ei=2JbyW73FIIKy8QXfprGQDQ&start=20&sa=N&ved=0ahUKEwi9kebxpeDeAhUCWbwKHV9TDNIQ8tMDCEI&biw=1218&bih=650&dpr=1.5"
[3] "https://www.google.co.kr/search?q=site:www.dbpia.co.kr+%EB%B9%84%EC%A0%95%EC%83%81+%ED%8A%B8%EB%9E%98%ED%94%BD&ei=2JbyW73FIIKy8QXfprGQDQ&start=30&sa=N&ved=0ahUKEwi9kebxpeDeAhUCWbwKHV9TDNIQ8tMDCEI&biw=1218&bih=650&dpr=1.5"
[4] "https://www.google.co.kr/search?q=site:www.dbpia.co.kr+%EB%B9%84%EC%A0%95%EC%83%81+%ED%8A%B8%EB%9E%98%ED%94%BD&ei=2JbyW73FIIKy8QXfprGQDQ&start=40&sa=N&ved=0ahUKEwi9kebxpeDeAhUCWbwKHV9TDNIQ8tMDCEI&biw=1218&bih=650&dpr=1.5"
[5] "https://www.google.co.kr/search?q=site:www.dbpia.co.kr+%EB%B9%84%EC%A0%95%EC%83%81+%ED%8A%B8%EB%9E%98%ED%94%BD&ei=2JbyW73FIIKy8QXfprGQDQ&start=50&sa=N&ved=0ahUKEwi9kebxpeDeAhUCWbwKHV9TDNIQ8tMDCEI&biw=1218&bih=650&dpr=1.5"
주소값들이 제대로 들어온 것을 확인할 수 있다.
links <- NULL
# 본문기사에 있는 링크를 저장시킬 변수
for(url in urls)
{
html <- read_html(url)
links <-c(links, html %>% html_nodes('.r') %>% html_nodes('a')%>% html_attr('href')%>% unique() )
}
è 저장되어 있는 구글 1~5페이지를 기준으로 html을 긁어온다 .
è 긁어온 html에서 본문기사에 해당하는 url 주소를 가져온다

그런데 , links를 긁어오면 한가지 문제점을 알 수 있을 것이다 .
위의 그림처럼 href의 속성값을 보면 특정 주소값을 기반으로 검색하는 본문 주소값이 없다…
그래서 우리는 긁어온 links에 구글주소값을 넣어줄 필요가 있다.
links <- paste0("https://www.google.co.kr/",links[1:50])
이제 본문기사에 해당하는 links도 구했다.
Links를 기반으로 본문 기사에 해당하는 초록부분을 크롤링해 보자
Simlple_Contxt <- NULL
# 크롤링한 초록의 내용이 담길 변수

우리는 본문기사에 들어가서 con_txt가 초록의 내용을 담고있는 태그라는 것을 알 수 있다.
for(link in links)
{
html <- read_html(link)
Simlple_Contxt <- c(Simlple_Contxt, html %>% html_nodes('.con_txt') %>% html_text())
}
è 위 for문을 통해서 초록부분을 크롤링한다
그런데 , 가져온 초록의 내용을 보면 데이터가 너무 안이쁘게 되어있다.
그래서 정제 작업을 해 준다.
Simlple_Contxt <- gsub("\r","",Simlple_Contxt)
Simlple_Contxt <- gsub("\n","",Simlple_Contxt)
Simlple_Contxt <- gsub(" ","",Simlple_Contxt)
위 작업을 통해 불필요한 부분을 대체해 준다.
Simlple_Contxt
[430] "DBpia추천논문더많은추천논문을확인해보세요!웹트래픽분석을통한유해트래픽탐지신현준,최일준,추병균,오창석,한국컴퓨터정보학회,한국컴퓨터정보학회논문지12(2),2007,221-229K29PLH아키텍츠,UAB아키노바,현대건축사,월간CONCEPT(211),2016,78-87클러스터링을이용한유해트래픽탐지신동혁,최형기,한국정보과학회,한국정보과학회학술발표논문집,2015,912-914공격탐지를위한트래픽수집및분석알고리즘유대성,오창석,한국콘텐츠학회,한국콘텐츠학회논문지4(4),2004,33-43유해트래픽방향에따른침입탐지기법분석최병하,한국정보과학회,한국정보과학회학술발표논문집39(1A),2012,57-59"
특정 부분을 가져와 본 것인데, 나름 이쁘게 잘 나왔다.
이제 크롤링한 결과값들 csv 파일로 컴퓨터 특정 경로에 지정시켜 보자
write.csv(Simlple_Contxt,"C:/Users/user/Desktop/3학년2학기/데이터마이닝과통계/기말고사/기말_HW2/비정상 트래픽/Simple_Contxt.csv")
è 이 때 write함수를 사용해서 csv로 저장시켜 준다 .

정확하게 csv파일로 저장이 되었따!!
'학부공부 > 데이터마이닝과통계' 카테고리의 다른 글
| 통계학의 개념 (0) | 2018.11.27 |
|---|---|
| 다양한 확률분포 (0) | 2018.11.24 |
| Corpus --> VCorpus (2) | 2018.11.18 |
| 논문제목+논문저자+논문발간일 크롤링 / wordcloud2 (5) | 2018.11.18 |
| API를 사용해서 실시간 버스 위치정보 시각화 (1) | 2018.11.15 |
#IT #먹방 #전자기기 #일상
#개발 #일상