
Python 으로 SteamAPI를 사용해서 , 데이터를 수집할 때 , 다음과 같은 오류가 났다 . IndexError: list assignment index out of range 나는 json으로 넘겨져 받아오는 데이터를 Python에서 이중딕셔너리로 해서 받아왔다. 결론부터 말해보자면 , 배열에 값을 추가할 때는 다음처럼 해야한다 . Q = [] Q.insert(배열주소값,대입되는값) 습관적으로 , Q [값을 넣을 배열 주소값] = 값 이렇게 했었는데 , Python에서 배열에 값을 넣을때는 insert를 사용하도록 하자 .
Python: Pandas pd.read_excel giving ImportError: Install xlrd >= 1.0.0 for Excel support Python 으로 Exel 작업을 해야할 것이 있어서 pandas를 사용하려 했더니 위와같은 오류가 났다. 해결방법은 간단하다 . xlrd를 다운받는다 . pip install xlrd
저번에는 그냥 출력만 해보았다. 결과값들을 DataFrame으로 만든다음에 CSV 파일로 저장을 시키는 부분을 추가했다. 코드를 보면서 확인해 본다 . 먼저 pandas를 로딩시켜 준다 . import pandas as pd game_name ~ game_langauges를 칼럼의 제목으로 지정할 것이며 , 그거에 해당하는 각각의 값들은 우리가 구해놓은 변수들을 대입해 준다.# data 집합 data =[['game_name','game_score_rank','game_userscore','game_owners','game_All_tags','game_languages'], [json_data[keys[Count]]['name'],json_data[keys[Count]]['score_rank'],json..

Steam_game 의 몇가지 필요한 정보들이 있었다.예를 들면 , 특정 게임의 태그 . 이름 . 출시일 . 추천수 . 소유자 .. 등등이다. 크롤링을 사용하여서 할 수 있다 . 다만 , 시간적이 오래걸릴 뿐더러 , 데이터의 손실의 가능성이 있다. 그리고 내가 필요로 하는 정보가 사이트에 없는 경우가 있으며 , 이 정보를 따로 만들어서 합치는 작업을 생각하면많은 시간을 필요로 한다. 그래서 알게된 api가 있다. https://steamspy.com/api.php --> 위 사이트는 steamspy 사이트이며 , Steam 게임에 대한 dataset을 가지고 있으며 , 무료 api를 제공한다. 위 api를 사용해서 사용자의 입력을 받아서 , 특정 태그에 따른 게임의 정보들을 출력해 보는 자동화도구를 만들..
Python에서 데이터 분석을 할때 , 유용하게 사용되는 라이브러리 Pandas를 사용하는데 , Pandas를 사용해서 Exel , csv 파일을 불러오는 방법은 다음과 같다. import pandas as pd excel파일 불러올 때 data = pd.read_excel('C:/Users/user/Desktop/졸작/Steam게임데이타(Github)/Steam_game_data.xlsx',sheet_name='Steam_game_data')data.columns csv파일 불러올 때 data = pd.read_csv('C:/Users/user/Desktop/졸작/Steam게임데이타(Github)/Steam_game_data.csv')data.columns 이 두 방법다 Pandas를 로딩해야 한다 .
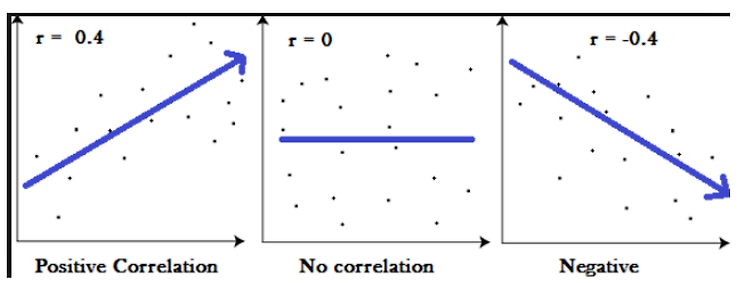
협업필터링 알고리즘 연습3(Collaborative filtering _ algorithm)저번에 사용한 유클리디안 거리공식을 활용한 유사도 측정에는 문제점이 있다. 특정인물의 점수기준이 극단적으로 너무 낮거나 높다면 제대로 된 결과를 도출해낼 수 없는 것이다. 예를 들어 나에게 영화를 평가할 때 일정 기준이 있어 , 기대를 충족하지 못하면 모두 0점을 주고 , 아니면 모두 만점을 주면 전체 데이터를 해치는 결과를 낳는다. 이것을 보완한 것이 Correlation_analysis(상관분석)이다. 상관분석은 두 변수간의 선형적 관계에 대한 분석이다. 쉽게 말해서 점수간 관계에 따라 점을 찍은 후 그 점이 분포한 모양에 따라 상관관계를 도출해내는 것이다 . 아래 그림과 같이 두 변인 x,y에 대해 x가 변화..