
오늘은 웹 크롤링한 데이터를 csv ( 엑셀 ) 형태로 저장을 시키고 , 저장시킨 엑셀 파일을 정제시키고 , 데이터를 가져와서 시각화 해보는 작업을 해 볼 것이다. 내가 크롤링할 사이트는 https://www.greenclimate.fund/home 이며 영어로 된 뉴스 사이트다. 코드를 보면서 분서해 보자 . 크게 rvest 패키지와 XML패키지가 필요하며 시각화 할 때 필요한 wordcloud2 패키지가 필요하다 . 문서를 다루는 tm패키지가 보통 깔려있는데 , 나는 없어서 깔아 주었다. library(rvest)library(XML) # 크롤링을 해오기 위해서 필요한 라이브러리들 install.packages("tm")install.packages("wordcloud2") # 필요한 패키지들 #wo..
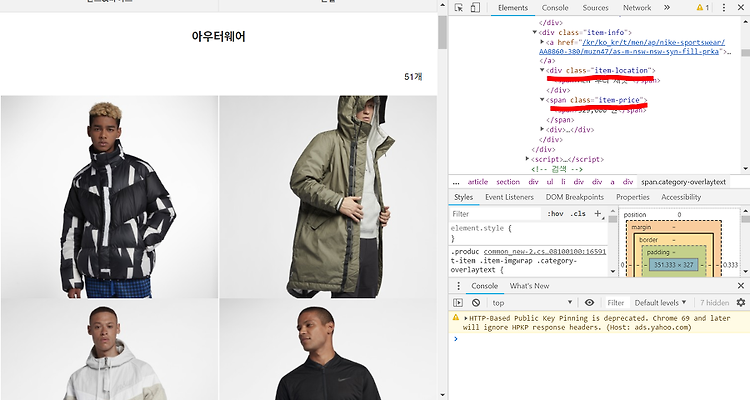
이번에는 나이키(nike) 사이트를 크롤링 해 볼 것이다. 내가 가져올 값들은 아우터 부분의 아우터 이름명과 가격이다. R을 실행해서 , 크롤링에 필요한 , xml과 rvest 패키지를 로딩시켜 준다 . library(rvest)library(XML) url url에 내가 크롤링 하고자 하는 사이트의 url 값을 넣어준다. doc 이 url을 html으로써 읽어 온다 이제 html에 접근하기 위해서 nike 사이트를 접속해 주면 되는데 , Nike 사이트는 다음과 같은 구조를 가졌다. 다음을 보게 되면 아우터의 class 명은 item-location으로 지정되어 있는 것을 확인할 수 있었다. # 옷 이름 가져오기 부분 prod_name % html_nodes(".item-title") %>% html_..
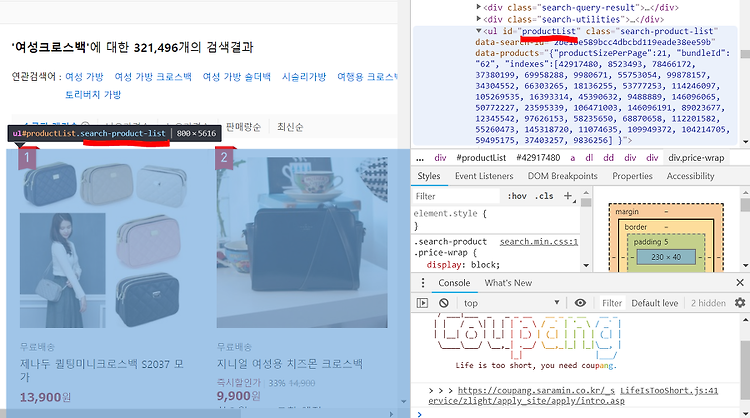
웹 크롤링할 일이 생겨서 하다가 , 안되는 부분이 있어서 적어보고자 한다. 기존 코드이다. XML 라이브러리를 통해서 크롤링에 접근할려고 했다. library(XML) url 먼저 내가 Parsing 하고자 하는 url을 긁어온다. doc 긁어온 url을 html 코드로 변환하며 encoding 방식도 설정해 줄수 있다. prod_name 내가 긁어온 html 코드에 접근을 하고 , ul태그내에 있는 id 값이 productList인것에 1차 접근을 하고 //을 통해서 건너뛴 다음 , div 태그 내에 있는 class 값이 name인 것에 2차 접근을 하는 것이였다. 그런데 여기서 오류가 나는 것이다. Class 가 NULL이라고 한다… 내 뇌피셜이지만 class를 못찾거나 , class명이 잘못된것이라..