

글을 쓰기 앞서 본 글은 다음 논문을 참고하여 공부를 한 내용이므로
참고바람.
# 참고논문 : 다중모드 센서와 LSTM 기반의 딥 러닝을 이용한 인간의 행동인식 시스템 = Human Activity Recognition System Using Multimodal Sensor and Deep Learning Based on LSTM / 신수연(Soo-Yeun Shin), 차주헌(Joo-Heon Cha), (大韓機械學會論文集A, Vol.42 No.2, [2018])[KCI등재]
영상을 컴퓨터가 학습을 하여 인간의 행동을 예측하고 위험행동을 분별할 수 있을것인가?
할 수 있다면 어떻게 그게 가능한 것인가?
를 주제로 다음 논문을 읽어 보았다.
머신러닝에서 인간의 위험행동 분석 공부
--> 공항에서 출입국 할 때, 사람의 행동으로 위험행동인지 구별하는 것
참조사이트 :
https://m.post.naver.com/viewer/postView.nhn?volumeNo=8637181&memberNo=36733075
--> 인공지능형 ( AI ) 비디오영상분석 " 딥러닝 적용 인간행동 분석과 산업 활용 사례 "
기업용 비디오 현황
--> 많은 기업이 영상 감시를 위해 많은 CCTV 카메라를 설치합니다. 2016년 기준 전세계저으로 약 3억 5천만대의 가시카메라가 설치된 것으로 추정된다. 이러한 카메라에서 방대한 양의 데이터가 실시간으로 생성되고 있는데 일반적으로 보안 담당자가 영상을 보고 범죄자, 수상한 행동 또는 안전 관련 행동 들을 감시한다. 하지만 이러한 방식에는 많은 문제점들이 있다.
1.수작업으로 이루어지는 모니터링은 비용이 많이 들고 인적 오류 (human error)에 취약하다. 1999년 연구에 따르면 20분이 지나면 비디오 장면을 보고 있는 감시관은 발생하는 전체 행동의 95%를 놓친다고 한다.
딥러닝 적용을 통한 영상에서의 인간 행동 이해
--> 딥러닝 적용을 통한 영상에서의 인간 행동 이해 딥러닝은 인간의 뇌가 작동하는 방식을 기반으로 한 머신러닝의 종류이다. 컴퓨팅 용량과 대용량 데이터세트의 폭발적인 증가로 딥러닝은 이미지, 텍스트, 음성 및 영상과 같은 비정형 데이터에서의 패턴을 찾는데 있어 매우 강력한 역량을 보여주었다. 딥러닝은 많은 사례에서 인간의 정확도를 능가하는 높은 정확도를 보여준 이후 기존의 컴퓨터 비전과 자연어처리 기술을 빠른 속도로 대체하고 있다
딥러닝 모델은 특정 아키텍처 내 서로 연결되어 있는 여러 층의 신경세포로 구성된 심층 신경망( deep neural network ) 을 활용하여 만들어진다. 딥러닝 네트워크는 ( deep learning network ) 사용자가 학습하기를 희망하는 데이터 예시를 입력함으로써 훈련을 거치게 된다.
네트워크의 각 층은 가기 다른 종류의 패턴을 학습하게 된다.
예를 들면 첫 번째 층은 윤곽선 (Edge)를 찾고, 두 번째 층은 객체 부분을 찾고, 다음 층은 객체를 찾는 방식을 통해 망의 더 높은 층은 훈련 데이터 세트와 관련된 점점 더 복잡해 지는 패턴의 조합을 학습하게 된다.
여러 개의 심층 신경망 아키텍처가 있고, 각각의 아키텍처는 망에서 신경세포를 연결하는 각기 다른 구조를 가지게 된다. 합성곱 신경망 ( CNNs : Convolutional neural networks ) 은 이미지 이해를 위해 일반적으로 쓰이는 딥러닝 아키텍처이다.
순환 신경망 ( RNNs : Recurrent Neural Networks ) 과 좀 더 구체적으로 장단기 기억 네트워크 ( LSTMs : Long short term memory networks ) 는 순차적 데이터에서의 패턴 이해를 위해 널리 사용되는 아키텍처이다. 영상 데이터의 경우 CNN와 LSTMs을 같이 사용함으로써 각각의 프레임에서의 공간적 패턴 뿐만 아니라 프레임 시퀀스에서 시간적 패턴을 추출할 수도 있다.
그렇다면 딥러닝을 영상 감시 데이터에서 행동 패턴을 찾기 위한 목적으로 적용하면 어떻게 될까??
1. 영상에서 곧바로 행동 패턴을 자동 식별함으로써 영상을 수동적인 방식으로 모니터링 할 필요성이 줄어들고, 그로 인해 비용이 줄어들 뿐만 아니라 인력 오류 발생 가능성도 제거된다
2. 유의미한 행동만이 담긴 선별적 영상만을 저장하고 관리함으로써 스토리지 인프라에 대한 니즈가 크게 줄어든다.
3.실시간 행동 파악을 통해 빠른 대응이 가능하다
4.행동 시퀀스에서 추가적인 패턴을 추출함으로써 결과 예측이나 규정 준수를 보장한다.
5.딥러닝 기술은 영상 데이터를 지속적으로 학습함으로써 행동과 관련된 좀 더 세부적인 내용을 구분할 수 있게 된다.
기업용 행동 인식
--> 삼성 SDS는 영상에서 행동을 이해하기 위한 딥러닝 기술을 활용한 선도적인 기업용 플랫폼을 개발하였다.
영상데이터에서 직접 자동적으로 행동을 이해함으로써 다양한 산업에서 높은 비즈니스 가치를 가진 다양한 활용 사례를 만들 수 있다.
다중모드 센서와 LSTM 기반의 딥 러닝을 이용한 인간의 행동인식 시스템 = Human Activity Recognition System Using Multimodal Sensor and Deep Learning Based on LSTM
본 논문에서는 인간의 다양하고 복잡한 행동을 인식하기 위한 기존의 두 가지 방법인 직접 센서 측정 방법과 인공지능 기반의 방법론에 대한 문제점들을 보완하기 위한 새로운 시스템을 제안한다 이를 구현하기 위해 가속도, 자이로, 고도 센서로 구성된 다중모드 센서를 개발하고, 센서의 물리적 측정값과 딥 러닝의 학습 결과를 실시간으로 병합함으로써 보다 정확한 자세 및 행동을 인식할 수 있는 방법론에 대해 기술하고 있다.인간의 행동별 데이터를 수집,분석하여 인간의 정적인 행동에 대해 정의한다.
다중모드 센서로부터 수집된 데이터를 이용하여 RNN(Recurrent Neural Network)의 변형 알고리즘인 LSTM(Long Short Term Memory Networks)를 이용하여 인간의 자세와 행동을 학습한다. 마지막으로 실제 환경 실험을 통하여 본 논문에서 제안한 시스템의 효율성과 타당성을 확인한다.
본 논문에서는 웨어러블 디바이스(Wearable Device)에 대한 관심이 높아지면서 인간의 신체활동 및 행동을 인식하는 제품들이 많이 출시되고 관심을 받고 있다. 그러나 웨어러블 디바이스는 인간의 행동이나 신체 활동을 측정하는데 있어 그 정확성과 효용성에 대한 근거는 부족한 상황이다.
이러한 문제를 해결하기 위해서 매우 복잡하고 다양한 개개인의 행동 패턴을 정밀하게 측정,분석하고 복수의 인간들에게 적용이 가능한 행동인식 시스템을 구현하기 위해서는 딥 러닝(Deep Learning)과 같은 인공지능 기술을 적용한 가변형 인터페이스 시스템 개발이 필요함을 말해주고 있었다.
그리고 본 논문에서는 시스템 구성을 다음과 같이 구성하고 있었다.

위 사진처럼 인간의 몸통에 부착하는 하드웨어(다중모드 센서) 와 하드웨어로부터 측정된 데이터를 처리하는 소프트웨어(딥 러닝)로 구성된다. 다중모드 센서로부터 측정된 10개의 센서 값을 입력하여, 딥 러닝에 의한 인간의 행동에 대한 학습을 진행함과 동시에 다중모드 센서로부터 계산된 가속도,각속도,각도,고도 값을 실시간으로 병합함으로써, 인간의 특정한 동적자세 및 정적자세를 정확하게 인식하고자 하는 시스템이다. 여기서 각도 값은 가속도 센서와 자이로 센서로부터 계산하여 얻는다.
본 논문에서는 구글의 인공지능 플랫폼인 텐서플로우(Tensor Flow)를 사용하여 인간의 특정 행동 학습을 진행하며, 다중모드 센서는 가속도 센서, 자이로 센서, 고도 센서 등 3개의 센서로 구성되며, 컴퓨터와의 통신을 위한 블루투스 모듈로 구성되어 있다.
하드웨어 구성은 다음과 같다.

9 자유도 센서(가속도 센서, 자이로 센서, 지자기 센서)인 Inven Sense사의 MPU-9150와 고도 센서인 MS6511로 구성되며, 측정 데이터 처리를 위한 MPU(Micro Controller Unit)와 데이터 전송을 위한 블루투스, 데이터 확인을 위한 LCD로 구성된다.
각 센서의 사양은 다음과 같다.

다음 그림은 실제로 제작한 PCB로 다중모드 센서의 실제 모습이다. 다중모드 센서는 행동 데이터 측정과 실제 생활에서의 사용에 있어서 편리함을 위해 소형으로 제작하였다.

다중모드 센서는 전원이 공급되면 바로 MCU의 Interrupt, GPIO(General Purpose Input/output), LCD, 12C(Inter Integrated Circuit), UART( Universal asynchronous receiver/transmitter ) 통신 등 모든 기능이 초기화 된다. 모든 센서의 초기화와 켈리브레이션(Calibration)과 블루투스(Bluetooth)의 초기화가 완료되면 부트(Boot) 완료 상태가 된다.
다음 그림은 다중모드 센서의 시스템 알고리즘을 나타낸 흐름도이다.

Main Process 에서 6축 센서 값(가속도 3축, 자이로 3축)과 고도계의 센서 값을 받는다. 각도 3축 값은 가속도 3축과 각속도(자이로) 3축을 통하여 다음과 같이 계산한 후에 서로 보완해주는 칼만필터(Kalman Filter)를 사용한다.
알고리즘 및 전처리 적용은 어떻게 하였을지 궁금하였다.
텐서플로우를 이용하여 인간의 행동을 학습하기 위해서는 먼저 데이터 전처리(Preprocessing) 과정이 필요하다. 전체 데이터 범위를 일정하게 하기 위해 정규화(Normalization)를 한다. 총 10축(가속도 3축. 각속도 3축, 각도 3축)을 각 축마다 [-1,1] 사이의 범위를 기준으로 정규화를 적용한다.
각도는 자이로 센서와 가속도 센서의 값을 통하여 얻는다. 정확한 각도 값을 도출하기 위해 칼만 필터를 적용한다. 특정 시점에서의 상태는 이전 시점의 상태와 선형적인 관계를 가지고 있다는 가정 하에 시스템의 상태변수를 찾아내는 최적화 추정기법이다. 즉, 실제 상태 값과 추정된 상태 값의 오차 공분산을 최소화하는 필터이다.
다음은 칼만 필터의 흐름도이다.

위의 그림에서 아래첨자는 데이터의 시간을 의미하여 위첨자 중 '-'는 예측 값, '^'는 추정 값을 나타낸다. Time Update는 시스템 방정식이고, Measurement Update는 관층방식이다.
x는 칼만 필터 통해 최적화 하고자 하는 상태변수이며, A는 이전단계에서 다음단계로 연결하는 변환계수이다. B와 u는 시스템에 무관한 추가 입력 값이다. 오차 공분산 값인 p는 시스템 오차인 Q값과 이전 상태의 공분산 값에 의해 도출한다. R은 센서 자체의 오차이며, 센서 사양(Specification)을 통하여 확인이 가능하다.
칼만 이득(Kalman Gain)은 시스템 방정식에서 구한 사전/사후 오차(P)값과 측정 잡음(R)값을 통하여 알 수 있다. 이렇게 구한 칼만 이득을 통해 예측된 상태변수 값으로 올바른 상태변수 값을 알 수 있다. 칼만 이득으로 현재 상태의 P값을 재조정하여 다음 상태에 영향을 미치게 된다.
센서의 신뢰성 검증은 어떻게 하는 것일까??
정확한 자세인식을 위해서는 각 센서의 정확한 출력 데이터가 필요하다. 다중모드 센서의 고도계와 각도 값(가속도 센서와 자이로 센서를 보상하여 얻은 각도)의 분해능을 확인하였다.
고도계의 선형성 및 분해능을 확인하기 위해 바닥에서부터 10cm 간격으로 1분씩 10회를 측정하는 방식으로 100cm까지 10cm 간격으로 측정을 하였다.
측정 단위는 파스칼(Pa)이다.

위는 x축 높이(cm)마다의 y축 압력(Pa) 값을 측정한 그래프이다. 10cm 마다 고도 출력 값을 평균화하였으며, 고도계 센서의 선형성을 확인하였다.
각도의 선형성을 확인하기 위해 다음 그림처럼 y축 기준 (좌우 방향)과 x축 기준(상하 방향)으로 -90 ~ +90 까지 각도를 측정하였다.

다음 그림들은 각각 y축 기준의 각도와 x축 기준의 각도 변화를 측정한 그래프이며, 측정된 두 축의 각도 모두 선형성을 지니고 있음을 확인할 수 있었다.


다중모드 센서에 의한 행동 인식
1) 자세정의
자세를 정의하기 위해 위 그림Fig9와 같이 자세를 정의하였다. 누워있는 자세를 기준으로 정중앙 면의 법선 방향을 x축, 수평면의 법선 벡터 방향을 y축으로 정의한다. Fig 9를 통하여 3축 가속도, 3축 각속도, 1축 고도의 각 축의 방향 및 높이의 확인이 가능하다.
2) 다중모드 센서에 의한 행동 정의
다음그림과 같이 가슴 정중앙에 다중모드 센서를 부착하여 실험을 진행하였다. 5Hz(0.2s)로 샘플링(Sampling)을 통하여 데이터를 수집하였다. 즉 1초에 5번의 데이터를 수집하는 것이다.
각 자세는 피실험자 2명을 대상으로 위와 같이 1분씩 10번 이상 측정하였으며, 대표적으로 눕기, 오른 방향 모로 눕기, 왼 방향 모로 눕기, 엎드려 눕기, 앉기, 서기, 걷기, 뛰기로 8가지의 행동패턴으로 나누어 측정하였다. 그리고 대표적인 행동을 제외하고 각 행동별 다양한 상황을 추가적으로 측정하였다.

예를 들면 다음과 같은 것이다.
앉기의 경우 바닥에서의 앉기뿐만이 아니라 소파, 식탁의자,책상의자에 앉기에 대한 데이터를 수집하였으며, 걷기와 뛰기의 경우에도 제자리 걷기 및 뛰기와 실제 실외에서 걷기와 뛰기를 측정하여 데이터를 수집하였다. 이와 같은 방법으로 각 자세별 측정값으로서 가속도 3축과 각속도 3축, 각도3축, 고도 1축인 총 10축의 데이터를 수집하였다.
다중모드 센서를 이용하여 수집한 데이터를 바탕으로 정적인 자세인 6가지 자세(눕기,오른 방향 모로 눕기, 왼 방향 모로 눕기, 앉기, 서기)를 정의하였으며, 정적인 자세에 대한 각 축의 각도 데이터를 각각 평균화(Averaging)하여 += 10도까지의 범위로 정의하였다.
다음은 다중모드 센서의 출력 값을 바탕으로 정적인 자세의 각도를 정의한 표이다. 정적인 자세는 딥 러닝을 이용하여 학습을 진행한 후, 인식에 있어서 오류를 보상할 때 적용이 가능하다.
딥 러닝에 의한 행동 인식은 어떻게 하는 것일까??
1) 순환신경망(RNN,LSTM)
순환신경망인 RNN(Recurrent Neural Networks)는 시계열 데이터 등의 연속 데이터를 취급하기 위한 신경망 네트워크이다. RNN은 루프(Loop)를 가진 네트워크이며, 루프에 의해 정보를 지속시켜주며, 이전 데이터가 현재 결과에 반영되도록 한다.
그러나 RNN은 관련 정보와 그 정보를 사용하는 지점이 먼 경우에 역전파 기울기(Back Propagation Gradient)가 점차 줄어 학습 능력이 저하되며 기울기가 사라지는 문제(Vanishing Gradient Problem)가 발생한다. 이러한 문제를 극복하기 위한 알고리즘이 LSTM이며, RNN의 은익상태(Hidden State)에 셀상태(Cell State)를 추가한 구조이다.
LSTM(Long Short Term Memory networks)은 장기 의존성 학습이 가능한 종류의 순환 신경망이다. 장기간 이전 데이터를 기억하는 것이 LSTM의 기본이다. LSTM은 장기정인 정보를 저장하기 위한 복잡한 구조를 가지고 있다. 장기 메모리(Long Term Memory)는 메모리 셀(Memory Cell)에 저장되며, 시간과 주어진 입력 값에 따라 저장해둔 정보를 얼마나 가지고 있을지를 잊기 게이트(Forget Gate)에 의해 결정된다.

위 그림은 LSTM의 메모리 셀을 나타내는 그림이다. 위 그림에 대한 식은 다음과 같다. 식 (1)은 잊기 게이트 벡터를 도출하는 식이며, 이전의 정보들의 가중치를 결정한다. 식 (2)는 입력 게이트 벡터를 도출하는 식으로, 새로운 정보를 취득한다. 식 (3)은 은닉상태를 도출하며, 식 (4)는 셀 상태 벡터를 도출하며 , 식 (5)는 출력 게이트 벡터로 출력의 가능성이 큰 것을 구한다. 마지막으로 식 (6)에서 출력 벡터를 도출이 가능하다.


코드 구현 및 신뢰성 검증은 어떻게 한 것일까!?
딥 러닝의 라이브러리는 "Tensor Flow"를 사용한다. "Tensor Flow"의 인터페이스는 파이선(Python)의 기반인 'Jupyter'를 이용하여 알고리즘을 구현한다.
학습과 관련된 변수로 학습률(Learning Rate), 은닉층(Hidden Layer), 배치사이즈(Batch Size) 등 세 가지가 있다.
학습률은 학습횟수(Iteration)를 수행할 때, 다음점(Point)을 얼마큼 옮길지를 결정한다. 학습률이 너무 크면 최적치로 수렴하지 않고 발산한다. 반대로 너무 작으면 수렴하는 속도가 매우 느려지며, 국부 최적해(Local Minimum)에 빠질 확률이 증가한다.
배치사이즈는 한 번에 처리하는 데이터의 크기를 의미한다. 배치사이즈만큼의 샘플을 한 번에 넣고 그 샘플의 기울기를 계산하여 하나의 배치마다 가중치를 갱신하게 된다. 배치 사이즈가 클수록 속도가 빨라진다.
마지막으로 은닉층은 NN(Neural Network)에서 가중치 계산에 있어 필요한 변수이다. 은닉층 수가 적으면 Underfitting(High Bias)이 될 가능성이 높아지며, 반대로 은닉층 수가 많으면 Overfitting이 발생할 가능성이 높아진다.
이와 같은 3가지의 변수들에 대한 최적한 조건을 구하여, 딥 러닝을 이용한 인간의 자세 및 행동에 대한 학습률을 높인다.

위 사진은 딥 러닝의 한 종류인 LSTM을 바탕으로 추출된 사람의 행동 및 운동 패턴을 나타낸다.
LSTM을 이용하여 학습하기 이전에 알고리즘의 신뢰성 즉 학습률을 확인하는 것이다. 사용된 데이터는 위에서 설명한 정적인 자세를 정의하는데 사용한 데이터이다. 1축 고도 값을 제외한 가속도 3축과 각속도 3축, 각도 3축의 데이터를 학습에 이용한다. 고도계는 순간적인 데이터로서의 신뢰성은 높으나, 기압 측정을 원리로 측정되기 때문에 환경에 따라 기압의 변화가 크다. 그래서 장시간의 출력 값이 불안정하므로 학습 데이터로 이용하지 않는다.
새로운 데이터의 인식율을 알아보기 위해 각 행동별로 1분 동안의 데이터를 제외하고 기본자세 데이터와 행동별 다양한 자세의 데이터 모두 트레이닝 세트(Training Set)에 적용하여 학습을 진행한다. 트레이닝 세트를 바탕으로 학습을 진행한 후에 인식율을 확인하기 위한 테스트 세트(Test Set)를 이용하여 알고리즘을 검증한다.
테스트 세트에는 트레이닝 세트에 있는 데이터 중 각 행동별로 150개, 즉 30초 동안의 데이터를 입력하여 인식율을 확인한다.
학습결과는 다음과 같다.
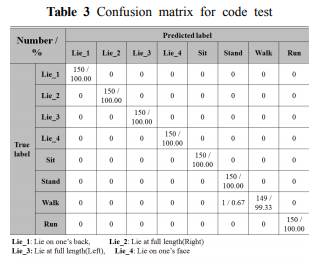
걷기에서 0.67% 서기로 인식하고, 그 외의 모든 행동은 다 100.00% 인식하였음을 확인하였다. 이에 대한 학습률은 99.54%이며, 인식율은 99.92%로서 본 알고리즘의 신뢰성을 확인할 수 있었다.
환경변수 설정은 어떻게 하였을까??
알고리즘의 최적화를 위해 각 변수별 학습률을 비교한다. 공통적으로 학습횟수는 193,886,000회 학습을 진행하였으며, 그 결과 모두 수렴하였음을 확인 할 수 있었다.
다음 그림은 학습횟수(Iteration)에 따른 트레인 정확도와 손실을 보여주는 그래프이다.

학습 정확도는 1로 수렴하고, 학습 손실은 0으로 수렴하고 있음을 알 수 있다.

위 그림은 각 변수별 학습 결과 정확도를 나타낸 것이다. 학습률이 0.005일 경우 가장 높은 정확도를 보였으며, 은닉층은 레이어의 수가 증가할수록 더 학습률의 정확도가 높아지는 것을 확인하였다. 한편 배치사이즈는 55,000인 경우 가장 높은 정확도 99.81%를 보였으며, 55,000을 초과하면서 학습률이 감소하는 경향을 보였다.
결과적으로 학습을 위한 최적화 변수값은 학습률의 정확도가 가장 높은 99.81%에 해당하는 학습률 0.005, 은닉충 50 , 배치사이즈 55,000로 각각 확인하였으며 이를 기반으로 본 논문에서의 학습을 진행하였다.
8가지 자세 인식
전절에서와 같은 조건으로 학습을 진행한 후, 기본자세인 8가지 자세인 눕기, 오른 방향 모로 눕기, 왼 방향 모로 눕기, 엎드려 눕기, 앉기, 서기, 걷기, 뛰기 등에 대한 실제 인식율을 확인하였다.
각 자세별로 1분 동안 수집된 300개의 데이터를 이용하여 인식 시험을 진행하였다.
학습은 다음과 같이 두 가지 경우로 나누어 진행하였다. 첫 번째 경우는 한 사람으로부터 측정한 데이터를 바탕으로 인식 시험을 진행하였다.
위 테이블은 전술한 두 가지 경우의 학습률과 인식율을 비교한 표이다. 위 테이블과 같이 두 가지 경우 모두 학습률에 있어서는 99% 이상으로 높은 학습률을 보였지만, 인식율은 두 사람의 데이터로 학습을 한 경우가 약 20% 정도 높은 인식율을 보였다. 데이터 양 또한 변수만큼 중요한 영향을 미치는 것을 확인할 수 있었다.
다음 테이블은 두 사람의 측정값으로 학습시킨 후의 인식율을 나타낸 표이다. 4가지 정적인 자세에서 눕기,앉기,서기는 100,00% 인식하였으나, 걷기의 경우에는 0.33%는 앉기로, 1.67%는 서기로 잘못 인식되었다. 전체적인 인식율은 99.75%로 높은 인식율을 보였다.

시스템 적용은 어떻게 하는 것일까??
딥 러닝 학습 결과와 다중모드 센서의 물리적 측정값을 실시간으로 병합시킴으로써 보다 정확한 자세 및 행동을 인식할 수 있는 시스템을 제안한다고 한다.

위 그림은 시스템의 블록 다이어그램을 나타낸 것이다. 위 그림처럼 다중모드 센서를 이용하여 행동별 데이터를 수집한 후, 행동 별 데이터 값을 정의하고 딥 러닝을 이용하여 행동 인식을 수행한다.
딥 러닝을 이용하여 학습하고 인식하였을 때, 행동을 다른 행동으로 인식하는 오류가 생기는 경우가 있다. 이러한 경우 행동별 데이터 값을 센서에 의해 인식된 행동을 병합함으로써 인간의 자세 및 행동에 대한 인식율을 높이려는 일종의 하이브리드(Hybrid) 시스템이다.
1) 동적 행동 인식
우선 동적인 자세의 인식율을 확인해보았다. 엘리베이터 타고 올라가기와 내려가기, 계단 올라가기와 내려가기, 걷기, 뛰기 등의 데이터를 학습시킨 후에, 일상 행동에 대한 인식율을 확인한다.
걷기와 뛰기의 자세는 4.4절에서의 8가지 기본 자세 인식과 동일한 데이터를 사용하였으며, 엘리베이터 타고 올라가기와 내려가기, 계단 오르기와 내려가기는 0~16층까지 총 3번씩 측정하였다. 여기에서는 테스트 세트로서 각 자세별로 30초 동안 150개의 데이터를 인식하도록 한다.

위 테이블은 동적인 자세의 인식 결과를 나타낸 표이다. 결과적으로 전체 인식율이 73.55%임을 확인한다. 엘리베이터 타고 올라가기와 내려가기, 걷기, 뛰기는 약 90.00% 이상의 높은 인식율을 보였으나, 계단 오르기와 내려가기는 각각 약 9.33%와 54.00%의 매우 낮은 인식율을 보였다. 계단 오르기와 내리기 경우, 계단 오르기와 내리기를 제외하면 대부분 걷기 혹은 뛰기로 인식되었다.
2) 시스템 적용 예시
딥 러닝을 이용하여 동적인 자세를 인식한 결과, 계단 오르기와 내리기의 경우 걷기와 뛰기로 인식하는 오류가 발생하였다. 본 논문에서는 이와 같은 문제점을 보완하기 위해, 다중모드 센서의 고도계로부터 측정된 순간적인 기압 변화를 이용하여 엘리베이터 올라가기, 내려가기, 계단 올라가기, 내려가기를 정확하게 인식하도록 한다.
다음그림은 x축 시간(Time)에 따라 실제로 고층아파트의 0층에서 16층까지 올라가고 내려가는 것에 대한 고도(Pa)를 측정한 y축 값을 나타낸 그래프이다.

실제 높이에 따라 고도 값이 선형적으로 변화하고 있음을 알 수 있다. 0~16층까지의 기압변화는 약 5.26Pa이었으며, 층당 기압변화는 약 0.329Pa이었다.
다음그림은 딥 러닝 학습 결과와 다중모드 센서의 측정값을 하나의 시스템으로 병합시켜 적용한 결과를 표로 나타낸 것이다. 표에서와 같이 딥 러닝 학습 결과를 기반으로 상대적인 기압 변화에 따라 엘리베이터 타고 올라가기와 내려가기, 그리고 계단 오르기와 내려가기 등의 특정 행동을 정확하게 인식하도록 적용하였다. 즉, 다중모드 센서로부터 측정된 고도값과 이를 딥 러닝의 인식율과 병합시킴으로써 테이블 7에서와 같이 73.55%로 비교적 낮은 인식율이었던, 딥러닝에 의한 계단 올라가기와 내려가기, 엘리베이터 타고 올라가기와 내려가기 등의 특정 행동을 더 정확하게 인식할 수 있음을 알 수 있었다.

결론은 무엇일까?!
본 논문에서는 다중모드 센서를 기반으로, 머신러닝(Machine Learning)의 기법의 하나인 딥 러닝 학습결과와 다중모드 센서의 물리적 측정값을 실시간으로 병합시킴으로써 보다 정확한 자세 및 행동을 인식할 수 있는 시스템을 제안하였다.
이를 구현하기 위해 가속도, 자이로, 고도 센서가 내장된 다중모드 센서를 직접 제작하여, 인간의 행동별 데이터를 수집,분석하여 인간의 정적인 행동에 대해 정의 하였다. RNN변형 알고리즘인 LSTM을 이용하여 인간의 정적인 행동 8가지와 동적인 행동 6가지에 대한 학습도 동시에 진행함으로써 인간의 다양한 자세와 행동에 대해 매우 높은 비율로 인식할 수 있음을 확인 하였다.
또한 딥 러닝 학습에 의한 행동 인식 오류가 발생하는 경우, 다중모드 센서의 측정값과의 병합을 통하여 인식율을 높일 수 있음을 확인하였다.
실제 환경에서의 실험을 통하여 본 논문에서 제안한 시스템의 효용성과 타당성을 확인하였다.
'컴퓨터비전' 카테고리의 다른 글
#IT #먹방 #전자기기 #일상
#개발 #일상
-
 ModuleNotFoundError: No module named 'torch'2019.09.24
ModuleNotFoundError: No module named 'torch'2019.09.24 -
 opencv 및 python을 사용한 YOLO 객체 감지2019.09.23
opencv 및 python을 사용한 YOLO 객체 감지2019.09.23 -
 AttributeError: 'NoneType' object has no attribute 'shape'2019.09.23
AttributeError: 'NoneType' object has no attribute 'shape'2019.09.23 -
 cv2.error: OpenCV(4.1.1) C:\projects\opencv-python\opencv\modules\highgui\src\window.cpp:621: error: (-2:Unspecified error) The function is not implemented. Rebuild the library with Windows, GTK+ 2.x or Cocoa support. If you are on Ubuntu or Debian, ins..2019.09.23
cv2.error: OpenCV(4.1.1) C:\projects\opencv-python\opencv\modules\highgui\src\window.cpp:621: error: (-2:Unspecified error) The function is not implemented. Rebuild the library with Windows, GTK+ 2.x or Cocoa support. If you are on Ubuntu or Debian, ins..2019.09.23