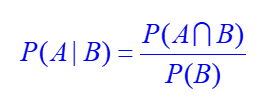

오늘은 기존에 알고 있던 , mtcars ( 기존 R에 내장되어 있는 데이터셋 ) 말고 , 새로운 데이터셋을 구해서 회귀분석을 다뤄보겠다.
데이터셋을 다루는 사이트는 굉장히 많다 . 그런데 , 자동차 특정 정보를 포함하는 데이터셋을 찾기에는 어려웠다.
다음은 내가 찾은 데이터셋 사이트중 괜찮은 곳 들을 정리해 보았다.
https://www.kaggle.com/ --> 데이터셋 사이트
https://archive.ics.uci.edu/ml/datasets.html --> 데이터셋 사이트
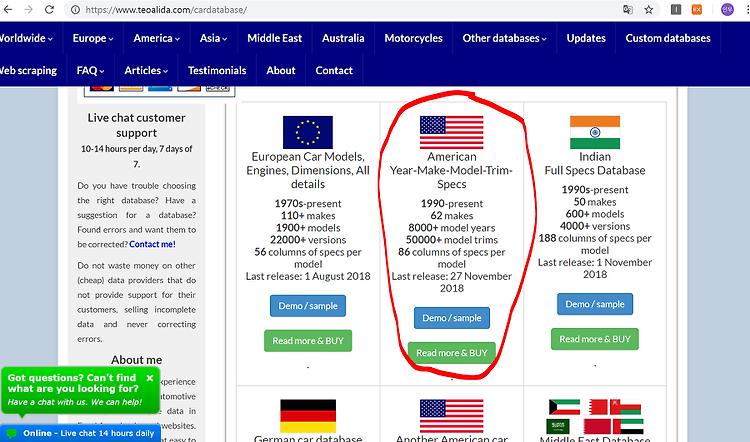
https://www.teoalida.com/cardatabase/ --> cardatabase 전문사이트
내가 사용할 곳은 cardatabase전문 사이트이다. 자동차 정보가 내가 원하는 곳이 있었기 때문이다.
사이트를 들어가면 다음과 같은 화면이 뜬다.
Read more & Buy를 사용해서 더 많은 정보를 보고 싶지만…돈이 부족하므로…다음에 이용해보겠다. Demo버전을 다운받아본다

다운받으면 xls파일이 다운받아 질 것이다.
열어보면 … 다음과 같다.
좋다 .. 정보가 많은것까지는 좋은데 너무 많다 그래서 걸러줄 필요를 느꼈다.

나는 다음처럼 정리해 보았다.
순서대로 브랜드 , 모델명 , 만든시기 , trim , 가격 , 기본curb무게 , MPG 3시리즈 , cur와 관련된2가지 데이터까지 해서 정리를 해보았다.

그런데 파랑색으로 된 셀은 밑으로 조금만 내리다 보니까 , 영문이 섞여 있었다.
나는 숫자로써 어떠한 수치를 보고싶었기 때문에 셀을 지워준다.

이제 Exel 파일이 어느정도 정리가 되었다.
이제 Rstudio를 켜서 이 Exel파일을 분석해 볼 것이다.
코드를 통해서 어떻게 회귀분석을 하게 되는지 확인해 본다.
install.packages("readxl")
library(readxl)
è 기본적으로 exel파일을 읽을수 있는 패키지를 로딩시키는 것이 1번이다.
# readxl 패키지를 설치하여 read.xlsx()함수를 사용한다.
Data <- read_excel("C:/Users/user/Desktop/3학년2학기/데이터마이닝과통계/기말고사/기말_HW4/Modify2_Sample.xlsx", sheet = "Database",range = "B3:K108",
col_names = TRUE,
col_types ="guess",
na = "NA")
è read함수를 이용해서 exel파일을 읽어 줄 것이다
è sheet = “ 특정 sheet를 보고 싶을 경우 “
è range = “ 다루고 싶은 셀의 범위 “
è col_names = 셀의 이름 여부
è col_type = 셀의 타입
è na = 빈공백일 경우 어떻게 할지
이렇게 Exel 파일에 있는 데이터를 가져온다.
그런데 , R에서 Exel파일을 읽어올 때 다음과 같은 오류가 났다.
나는 경로도 , sheet 이름도 , 모든것을 알맞게 해주었는데 오류가 났다.
이해할 수가 없었다. 그러던 중 Exel 파일의 형식을 볼 수 있었는데 , 형태가 보호되어 있는 것이였다. 그렇기 때문에 접근을 할 수가 없었던 것이다.
Exel 파일의 형태를 공공으로 바꾸어 주니 , 접근이 잘 되었다.
str(Data)
è str를 사용해서 str형태로 Data를 다룬다.
결과값은 다음과 같다.
Classes ‘tbl_df’, ‘tbl’ and 'data.frame': 105 obs. of 10 variables:
$ Make : chr "BMW" "BMW" "BMW" "BMW" ...
$ Model : chr "3-Series" "3-Series" "3-Series" "3-Series" ...
$ Year : num 2018 2018 2018 2018 2018 ...
$ Trim : chr "Gran Turismo 330i xDrive Specs" "Gran Turismo 340i xDrive Specs" "Plug-In Hybrid 330e iPerformance Specs" "Sedan 320i Specs" ...
$ MSRP : POSIXct, format: "2022-10-16" "2038-10-22" "2024-11-04" "1995-07-20" ...
$ Base Curb Weight (lbs) : num 3915 4010 3915 3295 3450 ...
$ EPA Fuel Economy Est - City (MPG) : num 23 20 NA 24 23 31 30 24 23 21 ...
$ EPA Fuel Economy Est - Hwy (MPG) : num 33 29 NA 35 34 43 40 34 33 32 ...
$ Fuel Economy Est-Combined (MPG) : num 27 23 30 28 27 36 34 27 27 25 ...
$ Turning Diameter - Curb to Curb (ft): num 38.7 38.7 37.1 37.1 38.4 37.1 38.4 37.1 38.4 37.1 ...
아주 잘 가져와 졌다.
#데이터의 변수를 직접 이용
attach(Data)
è Data변수에 접근한다.
#그래프의 창 크기를 설정
win.graph(7,5)
plot(`Base Curb Weight (lbs)` , `Fuel Economy Est-Combined (MPG)` , main="Ibs 대비 MPG 산점도", xlab="Base Curb Weight", ylab="Fuel Economy Est-Combined (MPG)", pch=19, cex=1.2)
è Plot을 통해서 , 커브무게인 IBS 와 연비 MPG에 산점도를 확인해 볼 것이다
è x축은 Ibs , y축은 MPG로 주었다.
Plot 결과값은 다음과 같다.

아주 잘 나타나 졌다.
이걸 통해 알 수 있는 사실은 , 많이 없지만 , 대략 짐작해 보았을 때 ,
무게가 3600~4000사이에 있는 것들이 많다… 정도로 생각해 볼 수 있었다.
이제 여기에 grid를 주어볼 것이다.
grid(col=3)

Grid 가 잘 들어간 모습이다.
#단순회귀 적합선 추가 : lm(y~x) 함수 , abline()함수
sr <- lm(`Fuel Economy Est-Combined (MPG)`~`Base Curb Weight (lbs)`)
sr
여기서 보면 lm이라는 것을 사용하는 것을 알 수 있다.
어떤 선을 추가하는 것같긴 한데 정확히 먼지 모른다.
그래서 알아보았다.
Lm은 linear model의 약자이다.
사용법은 다음과 같다.
Lm(종속변수(결과) ~ 독립변수(원인) , 데이터)
이렇게 하면 머리에 와닿지가 않을 것이다 . 나또한 그렇기 때문이다.
예를 들면 , 부모와 자식이 있을 때 키를 예로 들어보자.
Lm을 사용해본다고 하면 ,
Out = lm ( child~parent, data = data)
위 공식을 보게 되면 부모의 키에 의해 자녀의 키가 결정된다 라는 것을
Lm을 사용해서 예를 들어보았다.
다시 본론으로 들어가서 , 위에 공식을 보면 , ibs에 의해서 MPG가 결정된다 라는 것을 lm을 사용해 본 것이다
왜 이렇게 해보았냐면 , 보통 커브라는 것은 급브레이크를 하거나 , 순간적인 엔진을 많이 소비하게 된다 . 그렇기 때문에 커브의 무게도 상관있지 않을까 라는 생각이 들었다.
그래서 커브의 무게에 의해 MPG의 값이 결정될 것이라고 생각했다.
위의 결과를 출력해 보면 다음과 같다.
출처 :http://rstudio-pubs-static.s3.amazonaws.com/189354_277dfb3a83a34a2abaae855b90fcf269.html
Call:lm(formula = `Fuel Economy Est-Combined (MPG)` ~ `Base Curb Weight (lbs)`) Coefficients: (Intercept) `Base Curb Weight (lbs)` 34.412182 -0.002526
위와 같이 출력값이 나오는데 , 여기서 우리가 알 수 있는 사실은
y절편 ( intercept ) 가 34.41이고 , ibs의 기울기는 -0.002526이란 것을 알 수 있다.
고로 이사실을 통해서 y= 34.41x – 0.002526의 결과값을 도출할 수 있게 되는 것이다.
abline(sr , col="red")
è 선을 추가해주는 역할을 한다.
결과값

선이 추가된 것을 확인할 수 있으며 , 기울기가 – 이므로 내려져 가는 것을 확인할 수 있다.
이제 데이터를 통합해서 한번해 보는 작업을 해보겠다.
나는 먼저 모든 데이터들을 확인해 보았다.
pairs(Data[c(5,6,7,8,9,10)])
결과값은 다음과 같다.

보이긴 하는데 , 이렇게 보기에는 불편하다 .
그래서 총 6개의 셀들을 3개씩 나눠서 2번확인해 보기로 하였다.
pairs(Data[c(5,6,7)])


이렇게 2단계를 거쳐서 각각 확인이 가능했다.
이제 대충 어떤 식으로 회귀분석이 이루어 지는지 알게 되었는가.
마지막으로 산점행렬도로써 , 분석을 해보겠다.
내가 확인할 셀은 MPG , Ibs , year 이다.
pairs(~`Fuel Economy Est-Combined (MPG)`+`Base Curb Weight (lbs)`+Year, data = Data, main="자동차 특성 산점행렬도", panel=function(x,y)
{points(x,y, pch=19, col=4); abline(lm(y~x), col=2)})

확인해 보면 , 다음과 같은 결과값들을 얻을 수가 있다.
순서대로 분석을 해보면 , MPG가 높을수록 ibs는 조금씩 감소한다는 것을 알 수 있다 .
그리고 year은 여기서 2018로 동일하기 때문에 2018은 그대로 둔다.
MPG 와 Ibs만 살펴보았다.
이렇게 함으로써 좀 더 많은 데이터셋을 통해서 , 분석을 해 볼 수 있었다.
나의 예측은 조금 ? 맞는것 같다 .
커브의 무게가 클수록 연비가 약간 크게 증가하는 것을 확인할 수 있었다.
'학부공부 > 데이터마이닝과통계' 카테고리의 다른 글
| 특정 버스의 버스경로에서 특정 정류장 위치 뽑기. (0) | 2018.12.18 |
|---|---|
| 조건부 확률 , 곱의 법칙 , 독립 사상 , 베이즈 정리 , 마르코프 결정 과정 , 베이즈 네트워크 (0) | 2018.12.06 |
| R패키지의 데이터셋을 다뤄보기 ( with mtcars ) (0) | 2018.11.30 |
| 통계학의 개념 (0) | 2018.11.27 |
| 다양한 확률분포 (0) | 2018.11.24 |
#IT #먹방 #전자기기 #일상
#개발 #일상