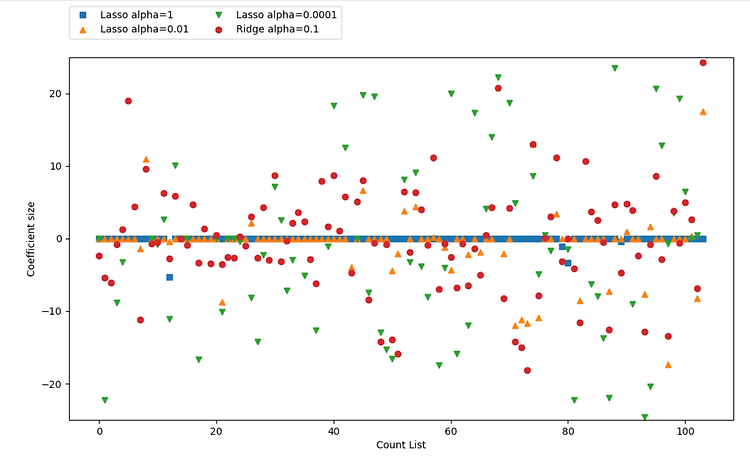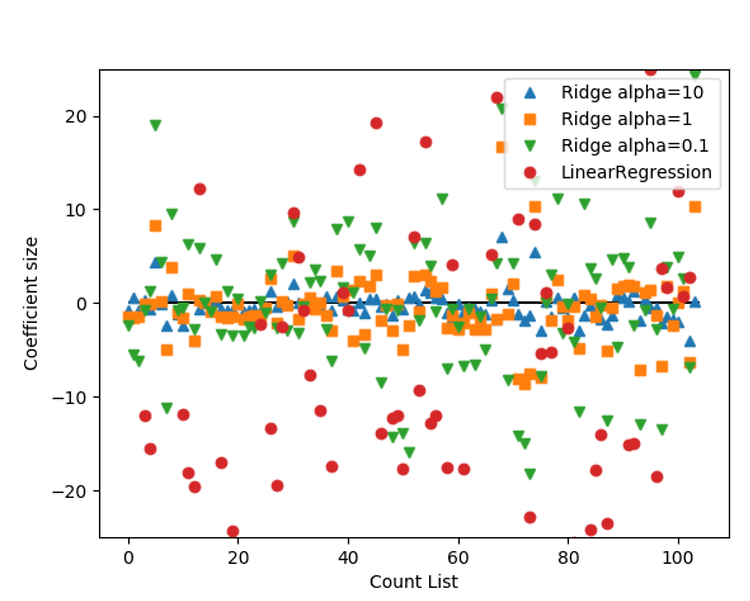

가중치
주택의 가치를 추정하는 프로그램을 어떻게 작성 할 수 있을까?
다음 내용을 읽기 전에 잠시 생각해 보자
만약 , 기계 학습에 대해 잘 모른다면 , 아마도 당신은 다음과 같이 주택 가격을
추정하기 위한 기본 규칙들을 작성하고자 할 것이다.

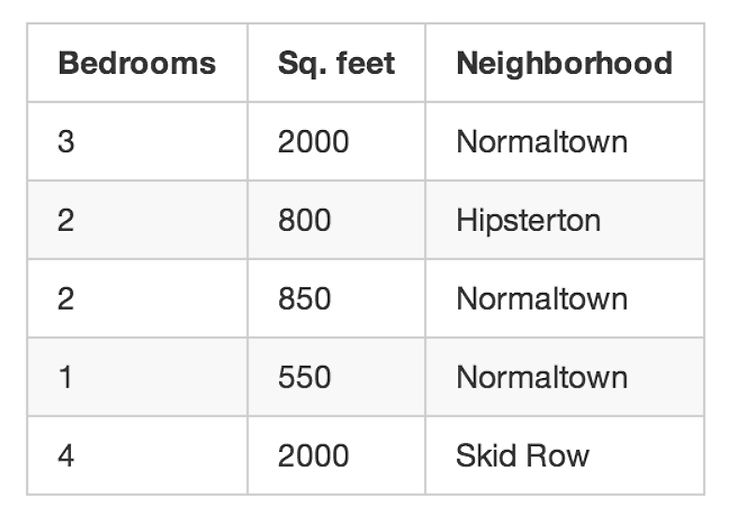
주택의 정보는 위와 같다 .
다음처럼 함수를 선언해 볼 수 있을 것 같다.
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price =0
#담당 지역내 평균 주택 가격은 평당 피트 당 200달이다 .
price_per_sqft = 200
if neighborhood == "hipsterton":
# 하지만 다른 지역은 조금 더 비싸다.
price_per_sqft = 400
elif neighborhood == "skid row":
# 그리고 다른 몇몇 지역은 싸다
price_per_sqft = 100
# 주택의 크기를 기반으로 주택 가격을 추정하는 것으로 시작한다.
price = price_per_sqft * sqft
# 이제 침실의 개수로 추정치를 조정한다
if num_of_bedrooms == 0:
# 원룸형 아파트는 가격이 싸다
price = price - 20000
else:
#일반적으로 많은 침실이 있는 주택이 더 비싸다
price = price + (num_of_bedrooms * 1000)
return price
위 과정을 몇 시간이고 계속하다 보면 , 원가 그럴듯한 ? 것을 만들어
낼 수도 있다 .
그러나 이 프로그램은 결코 완벽하지 않으며 가격이 변함에 따라 로직을
유지하기가 어려울 것이다.
이 문제를 해결할 수 있는 또다른 방법은 가격 ( price )에 영향을 미치는
침실의 개수 ( number of bedrooms ) , 평방 피트 면적 ( square footage )
및 지역 ( neighborhood ) 이라고 생각하는 것이다.
각 재료 ( 영향을 끼치는 것들 ) 가 최종 가격에 얼마나 많은 영향을 미치는지
파악할 수 있다면 , 이 최종 가격을 만들어줄 혼합 재료의 정확한 비율이 있을 것이다.
우리가 위처럼 생각을 한다면 다음처럼 간단하게 함수를 정의할 수 있다.
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# 고추장 한스푼
price += num_of_bedrooms * .841231951
# 간장 한스푼
price += sqft * 1231.1231231
# 김치 한 포기
price += neighborhood * 2.3242341421
# 마지막으로 , 약간의 소금 추가
price += 201.2343095
return price
가중치를 설명하기 위해서 , 요리의 과정을 빗대어 설명해 본 것이다.
위의 숫자를 주목하자 .
이 숫자들이 바로
가중치이다.
만약 모든 주택에 적용할 수 있는 완벽한 가중치를 찾아낼 수만 있다면 ,
우리의 함수는 집값을 예측할 수 있을 것이다.
가중치를 구하는 방법을 단계를 통해서 알아보자 .
step 1
def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood):
price = 0
# 고추장 한스푼
price += num_of_bedrooms * 1.0
# 간장 한스푼
price += sqft * 1.0
# 김치 한 포기
price += neighborhood * 1.0
# 마지막으로 , 약간의 소금 추가
price += 1.0
return price
step 2

알고 있는 모든 주택 데이터를 당신의 함수를 통해 실행해보고
각 주택의 정확한 가격과 이 함수가 얼마나 차이가 나는지 살펴보는 것이다.
예를 들면 , 실제 주택 가격이 있을 것이고 , 자신이 만든 함수의 예측 값이
있을 것인데 , 이 두 가격의 차이가 있을 것이다.
이 값을 바탕으로 , 데이터 세트에 있는 각 주택 마다 차이난 가격의 제곱값을
추가한다.
만약 데이터 세트에 500개의 주택 판매 정보가 있고
자신의 함수가 추정한 값과 실제 가격의 차이를 제곱한 값의 총합이
86,123,373 이라고 가정해 본다
그리고 자신의 함수가 현재 얼마나 "잘못되었는지를 알 수 있다"
이 합계를 500으로 나눠서 각 주택별로 얼마나 차이가 나는지 평균값을 구해볼 수 있고,
이 평균 오류 값을 이 함수의 비용 (cost)이라고 한다.
step3
가능한 모든 가중치를 조합해서 위 2단계를 계속 반복한다.
어떤 조합의 가중치든 비용을 0에 가깝게 만들어 주는 것을 사용하면 된다.
이런 가중치를 찾으면 문제를 해결한 것이다 .
'학부공부 > 빅데이터기술' 카테고리의 다른 글
| 기획이란 무엇인가 (0) | 2019.05.27 |
|---|---|
| 나이브 베이즈 분류기 ( Naive Bayes Classifier ) (0) | 2019.04.09 |
| 라쏘 (Lasso) (0) | 2019.04.08 |
| 릿지 ( Lidge ) (0) | 2019.04.08 |
| 최소제곱법 ( ordinary least squares ) - based on Extended_Boston datasets (0) | 2019.04.07 |
#IT #먹방 #전자기기 #일상
#개발 #일상