
이번에는 최소제곱법에 대해서 알아본다. 최소제곱법이란 ? 가장 간단하고 오래된 회귀용 선형 알고리즘 예측과 훈련 세트에 있는 타깃 y사이의 평균제곱오차를 최소화하는 파라미터 w와b를 찾음 평균제곱오차는 예측값과 타깃값의 차이를 제곱하여 더한 후에 샘플의 개수로 나눈 것이다. 선형 회귀는 매개변수가 없는 것이 장점이지만, 그래서 모델의 복잡도를 제어할 방법도 없다. from sklearn.linear_model import LinearRegression import mglearn from sklearn.model_selection import train_test_split --> 먼저 , 필요한 library를 로딩시켜주고 . X,y =mglearn.datasets.make_wave(n_samples=60..
일반적으로 KNeighbors 분류기에 중요한 매개변수는 두 개이다 . 데이터 포인트 사이의 거리를 재는 방법과 이웃의 수이다. 실제로 이웃의 수는 3개나 5개 정도로 적을 때 잘 작동하지만, 이 매개변수는 잘 조정해야 한다. k-NN의 장점은 이해하기 매우 쉬운 모델이라는 점이다. 그리고 많이 조정하지 않아도 자주 좋은 성능을 발휘한다. 더 복잡한 알고리즘을 적용해보기 전에 시도해볼 수 있는 좋은 시작점이다. 보통 최근접 이웃 모델은 매우 빠르게 만들 수 있지만, 훈련 세트가 매우 크면 (특성의 수나 샘플의 수가 클 경우) 예측이 느려진다. k-NN 알고리즘을 사용할 땐 데이터를 전처리하는 과정이 중요하다. (수백 개 이상의) 많은 특성을 가진 데이터셋에는 잘 동작하지 않으며, 특성 값 대부분이 0인 ..
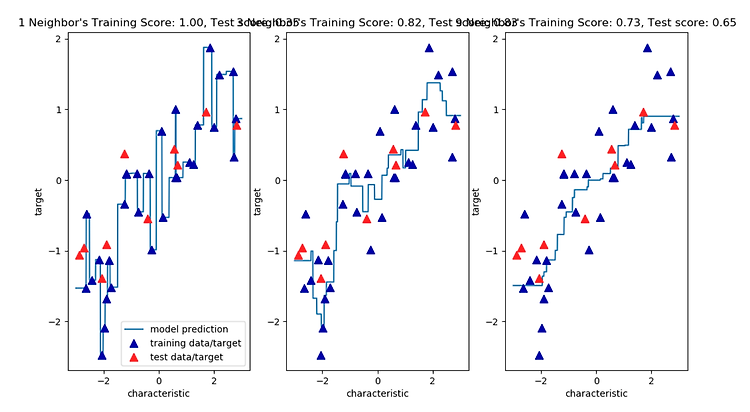
이번에는 KnKNeighborsRegressor Analysis 해볼 것이다. 코드를 통해서 확인해 보자 . import scipy as sp import numpy as np import matplotlib.pyplot as plt import pandas as pd import mglearn from sklearn.model_selection import train_test_split # from sklearn.neighbors import KNeighborsClassifier from sklearn.neighbors import KNeighborsRegressor --> 먼저 필요한 library를 로딩한다 . X, y = mglearn.datasets.make_wave(n_samples=40) #..
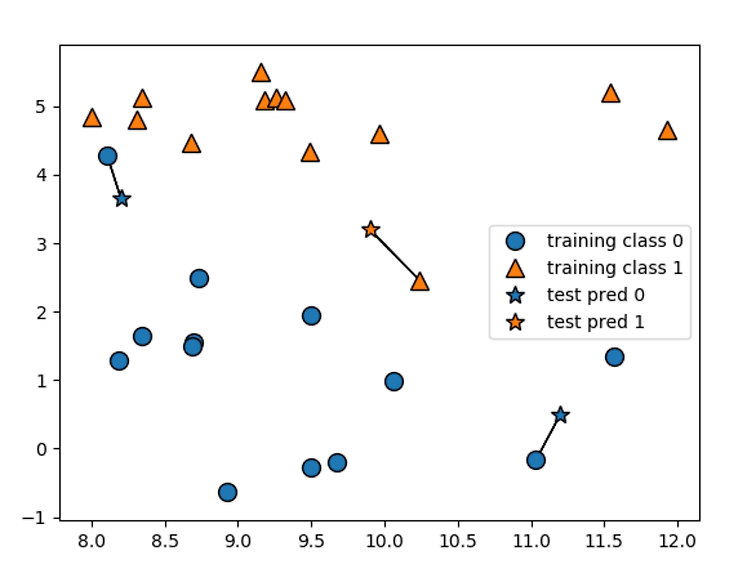
K-NN 분류기와 KNeighborsClassifier analysis를 코드를 통해서 어떠한 결과값이 나오고 , 어떻게 나오는지 자세히 알아볼 것이다 . 코드를 통해서 확인해 보자 . import mglearn import matplotlib.pyplot as plt --> mglearn과 matplotlib를 import를 한다 . 그래프 , 시각화 라이브러이다. # Forge 데이터를 사용해서 , mglearn을 사용해 본다 . # 여기서 mglearn이란 : 그래프나 데이터 적재와 관련한 세세한 코드를 일일이 쓰지 않아도 # 되게끔 해준다. # 간단하게 그림을 그리거나 필요한 데이터를 바로 불러들이기 위해서 사용한다 . X, y = mglearn.datasets.make_forge() 먼저 , f..
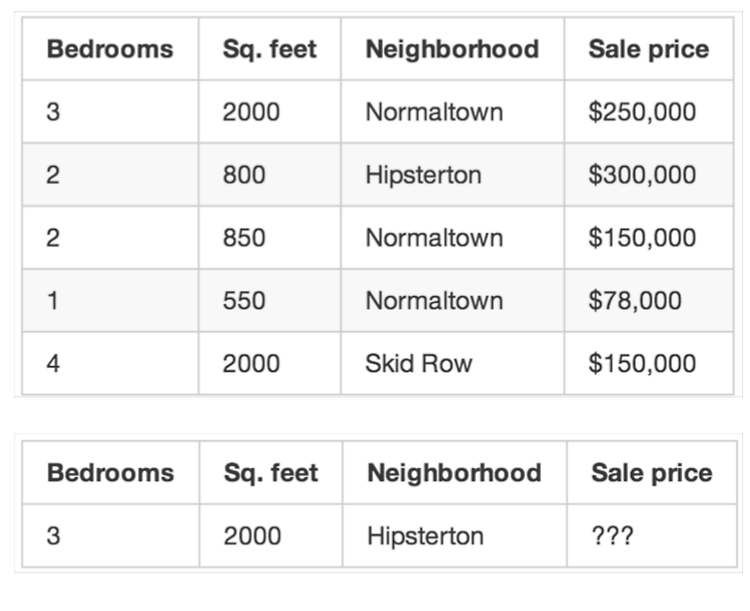
먼저 , 위와 같은 도표가 있다고 하자 . 보면 , 화장실 , 평수 , 위치 , 가격 순서대로 있다는것을 알 수 있다. 그리고 무엇이 생각나는가..? 지도학습은 , 기존의 데이터를 가지고 데이터를 예측해 보는 것인데 화장실 , 평수 , 위치를 기반으로 지도학습을 하여서 회귀를 통한 가격을 예측해 볼 수 있을까? 라는 의문점을 남긴다. 먼저 간단하게 개념정리를 해본다. 매개변수 à y =ax+b à a,b를 찾는 것 è 매개변수를 찾는 것 : 모델링 하이퍼 파라미터 à 일반화 = 최적화 , 사용자가 값을 조정하는 것 è 가중치 : 어떠한 것에 영향을 어느정도 미치는 가에 따라서 è 가중치를 줄 때 , 하이퍼 파라미터를 사용하며 , 위의 도표를 통해서 , 가격을 예측한다고 했을 때 화장실, 평수, 위치에 따..
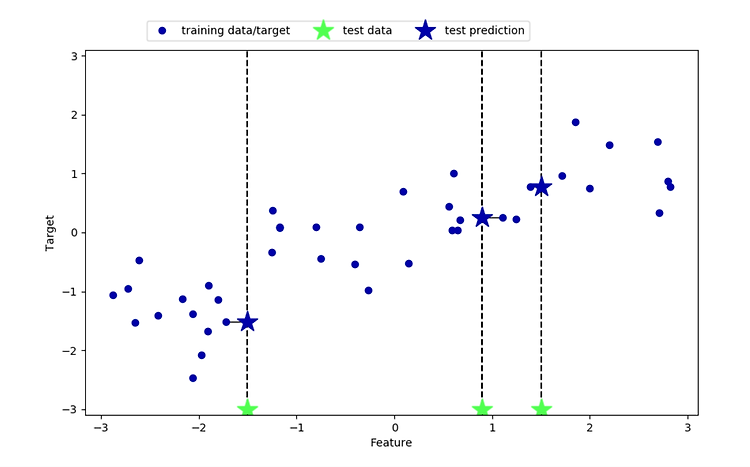
코드를 통해서 알아본다 . import scipy as sp import numpy as np import matplotlib.pyplot as plt import pandas as pd import mglearn mglearn.plots.plot_knn_regression(n_neighbors=1) mglearn.plots.plot_knn_regression(n_neighbors=3) plt.show() 결과값