
앞 전에 Automatic_API를 사용해서 Excel로써 태그에 해당하는 데이터들을 모아보았다.
모은 데이터들을 이제 MysqlDB에 넣어줄 것이다.
작업은 Python을 사용해서 작업했다.
코드를 보면서 확인해 본다 .
먼저 pymysql 의 cursors을 사용할 것이다.
Excel은 pandas를 사용해서 작업할 것이다 .
import pymysql.cursors
import pandas as pd
다음은 Mysql에 Connection하는 부분이다 .
password는 자신의 Mysql 정보를 입력해 주면 된다.
conn = pymysql.connect(host='localhost',
user='root',
password='',
charset='utf8mb4',
db ='test1'
)
다음은 database
# Python을 사용해서 Mysql database 만들기
# try:
# with conn.cursor() as cursor:
# sql = 'CREATE DATABASE test1'
# cursor.execute(sql)
#
# conn.commit()
#
# finally:
# conn.close()
다음은 Mysql table
# Python을 사용해서 Mysql table 만들기
# try:
# with conn.cursor() as cursor:
# sql = '''
# CREATE TABLE Game_IF(
# Count int(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
# game_name varchar(255) NOT NULL,
# game_owners int(255),
# game_all_tags varchar(255),
# game_languages varchar(255)
# ) ENGINE=InnoDB DEFAULT CHARSET=utf8
# '''
# cursor.execute(sql)
# conn.commit()
# finally:
# conn.close()
다음은 Automatic_API 를 사용해서 Excel에 저장했을 때와 똑같이 Excel을 읽어올 때도 똑같이 해준다 .
Userinput = ['SINGLE',
'MULTI',
'COOP',
'MMO',
'ISFREE',
'FREETOPLAY',
'PURCHASEAVAIL',
'CASUAL',
'DARK',
'CUTE',
'MUSIC',
'HUMOR',
'COMEDY',
'HORROR',
'STORYRICH',
'RELAXING',
'GORE',
'SURVIVE',
'STRATGY',
'PUZZLE',
'SCI-FI',
'FANTASY',
'ACTION',
'VIOLENT',
'SHOOTER',
'SPORT',
'RACING',
'FARM',
'SIMULATION',
'BUILDING'
]
코드가 길어서 나눠서 보겠다.
큰 for문은 내가 Excel파일을 찾아서 해당되는 Excel파일을 읽어와서 , 그 Excel파일에 존재하는 데이터를 MysqlDB에 넣어줄 것이다.
그런데 , 여기서 눈여겨 볼것은 , 애초에 Excel 파일로 만들 때 , json형태로 저장을 해주었었는데 , 이때 tags들은 딕셔너리 형태 그대로 저장되었다.
그래서 , 불필요한 ' , [ , ] 이런 문자들이 포함되어 있었다.
나는 이 불필요한 문자들을 제거해줄 필요가 있었기에 , function으로 이 문자들을 지워주고 지워준 데이터 자체를 return을 해주었다.
for Read in range(0,len(Userinput)):
df = pd.read_excel("C:/Users/user/Desktop/졸작/2019-03-16-Steam_API_코드수정/"+Userinput[Read]+".xlsx"
,sheet_name='Data')
Game_name = df['game_name']
Game_All_tags = df['game_All_tags']
# -----------Excel 에서 불러온 데이터를 각각의 배열 주소값에 각각 넣어준다 .
# Game_owners_array = []
# 여기서 tag는 엑셀에 저장되어 있는 배열값이 저장되어 있는데 , 먼저 문자열 형태로 그대로 가져온다.
# 문자열로 저장을 하고 , split으로 불필요한 문자들을 제거해 주기 위해서
Game_All_tags_array = ""
# 필요없는 문자 제거 함수
def character_removal_function(input):
input =input.replace("'","")
input =input.replace("[", "")
input =input.replace("]", "")
input = input.split(',')
return input
다음은 큰 for문내에 존재하는 첫번째 for문이다 .
이 for문의 역할은 Gane_name의 칼럼수를 가져오게 된다 .
굳이 game_name으로써 길이를 지정해준 이유는 Game_name은 DB에 조건을 줄 때 , NOT NULL로써 선언을 해주었을 뿐더러 ,
Game_name이 존재하지 않을리가 없기 때문이다 .
여기서 함수를 사용해줌으로써 , 태그의 구분자로써 , 배열을 만든다.
for col_index in range(0, len(Game_name.index)):
# 엑셀에서 가져온 특정 칼럼의 값을 변수에 저장 , 이때 문자열로
Game_All_tags_array = Game_All_tags[col_index]
#불필요한 문자 제거
Remove_Tag_name = character_removal_function(Game_All_tags_array)
다음은 2번쨰 for문이다 .
이 for문의 역할은 태그배열의 수만큼 for문을 돌려줌으로써 ,
게임이름에 해당하는 태그들을 DB에 Insert 해준다 .
# 태그가 존재하는 만큼
for count in range(0, len(Remove_Tag_name)):
with conn.cursor() as cursor:
sql = 'INSERT INTO Game_IF (game_name,game_all_tags) VALUES (%s,%s)'
cursor.execute(sql, (Game_name[col_index],Remove_Tag_name[count]))
conn.commit()
Game_All_tags_array = ""
# Game_languages_array = ""
conn.close()
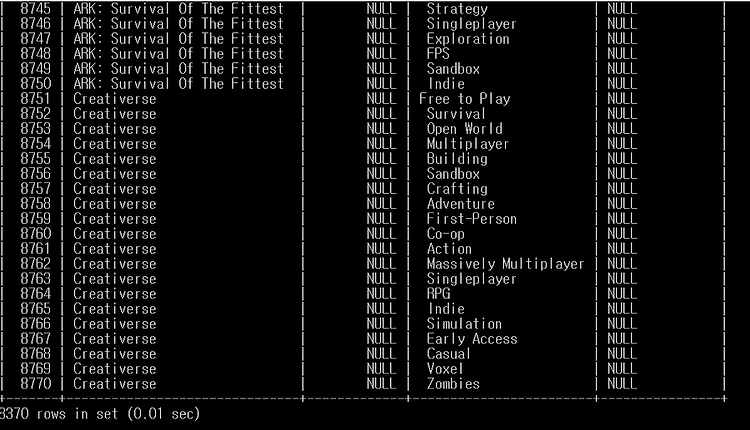
결과를 보면 , 다음처럼 8700여 개의 데이터가 DB에 들어갔다.

정리를 해보자면 다음과 같다 .
Put_Data_MysqlDB.py를 만든이유
1.일일이 태그에 해당하는 데이터를 저장해주기 귀찮았다
2.나중에 좀더많은 데이터를 모았을 때 , DB작업을 수월하게 하기 위해서 이다.
'졸업작품_preparing.... > python_작업' 카테고리의 다른 글
| 배열 초기화 ( Initialize array ) (0) | 2019.03.19 |
|---|---|
| Automatic_Steam_API 코드 수정3 (0) | 2019.03.19 |
| Automatic_Steam_API 코드수정2 (0) | 2019.03.17 |
| %s , %d 의 차이 (0) | 2019.03.17 |
| Automatic_Steam_API 코드수정 (0) | 2019.03.16 |
#IT #먹방 #전자기기 #일상
#개발 #일상