
역대 대통령님들 께서 연설문에서 어떤 말들을 많이 하였을까.
다음 library를 로딩해주자 .
만약 없다면 install.packages(" " )를 통해 다운받자.
library(KoNLP)
library(RColorBrewer)
library(wordcloud)
library(KoNLP)를 로딩시키면 useSejongDic을 사용할 수 있게 되는데 ,
한글 '세종사전' 이라고 한다.
useSejongDic
이제 팔레트를 생성해 준다.
pal2 <- brewer.pal(8,"Dark2")
이제 우리는 연설문을 선택을 변수에 저장을 시켜줄 것이다.
그리기 위해서는 연설문을 text 파일 형식으로 저장 시켜 놓아야 한다 .
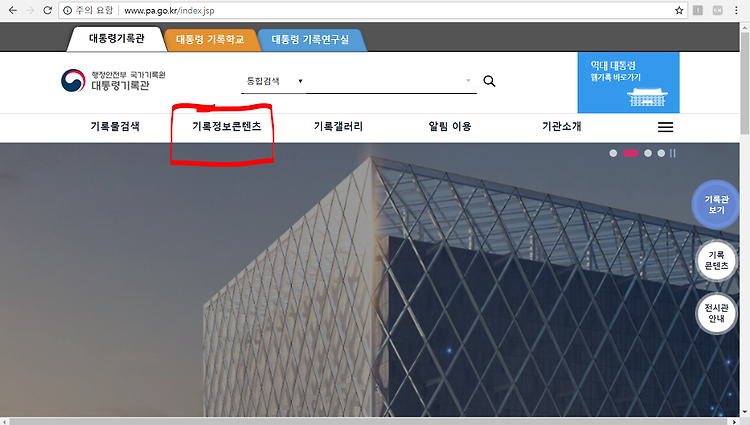
역대 대통령 연설문은 http://www.pa.go.kr/ <-- 이사이트에 들어가면 확인 할 수 있다.
들어가면 기록정보콘텐츠에 들어가준다.

저는 김영삼 대통령님의 연설문을 따오겠습니다.

따온 연설문을 speech.text 파일에 복붙을 하겠다. text파일 이름은 사용자 마음이다.
다음 처럼 말이다.

이제 준비는 되었고 이 연설문을 우리는 R에서 따올 것이다.
다음은 임의의 파일을 따와서 읽는다 이정도의 의미로 이해하길 바란다.
text <- readLines(file.choose())
이제 따온 연설문의 텍스트들을 정리?? 정리를 해야 하는데 ,
친절하게도 KoNLP 에서 메서드를 제공해 준다.
sapply는 결과를 벡터 or 행렬형태로 반환하고 , text에 있는 텍스트들을
extractNoun 을 통해서 정리를 할것이고 , USE.NAMES = F 로 줌으로써
단어 결과 위에 본문의 각 행이 포함되지 않게 할 것이다라고 이해한다.
extractNoun은 파일의 각 행에서 명사만 추출해주는 것
noun <- sapply(text,extractNoun,USE.NAMES = F)
우리는 이제 명사를 뽑아 왔고 , 이것들을 다시 정리를 해주는 작업이 필요하다
다음 작업은 추출된 명사를 통합하는 과정이다 라고 이해하면 된다.
noun2 <- unlist(noun)
통합된 명사들을 우리는 계산을 해서 텍스트 마이닝을 할 것이다.
단어수를 계산하는 방법은 다음과 같이 한다 .
word_count <- table(noun2)
마지막으로 wordcloud를 사용해서 시각화한다.
word_count의 이름으로 명하고 , 빈도수는 word_count , 크기 설정 , 제일 작은 빈도수 설정 , 정렬방식 , 색깔 설정 정도로 이해하면 된다.
wordcloud(names(word_count),freq = word_count,scale = c(6,0.3),min.freq = 3, random.order = F , rot.per = .1 , colors = pal2)

'학부공부 > 데이터마이닝과통계' 카테고리의 다른 글
| 네트워크의 개요 , 지표 (0) | 2018.09.22 |
|---|---|
| 문재인 대통령님의 취임사 데이터 분석하기 (0) | 2018.09.19 |
| Global Environment clear in R (0) | 2018.09.18 |
| 통계치를 통해서 전입수가 제일 많은 지역을 나타내 보자 (0) | 2018.09.15 |
| 벡터 결합과 recycling ( + Matrix ) (0) | 2018.09.12 |
#IT #먹방 #전자기기 #일상
#개발 #일상