학부공부/빅데이터기술
Dataset들을 사용해 보자
IT grow.
2019. 3. 28. 21:11
반응형
forge() 사용해보기 .
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
import pandas as pd
import mglearn
# 데이터셋 만들기
# 인위적으로 만든 이진 분류 데이터셋
X, y = mglearn.datasets.make_forge()
# 산점도 그리기
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
plt.legend(["Class 0", "Class 1"], loc=4)
plt.xlabel("First characteristic") # 첫 번째 특성
plt.ylabel("Second characteristic") # 두 번째 특성
print("X.shape: {}".format(X.shape))
plt.show()결과값

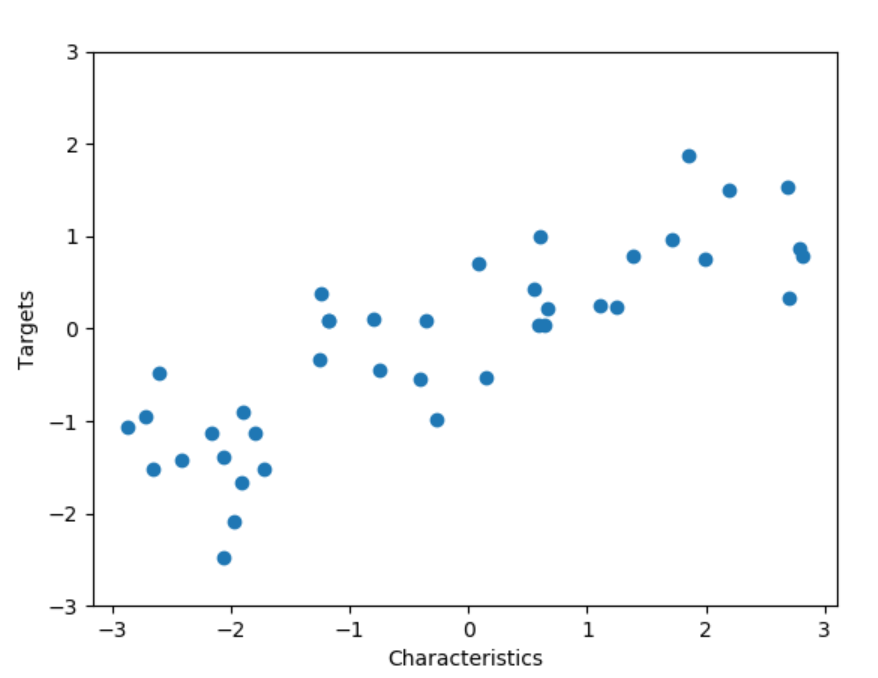
wave()사용해 보기
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
import pandas as pd
import mglearn
# 회귀 알고리즘
# 인위적으로 만든 wave 데이터셋 사용
X, y = mglearn.datasets.make_wave(n_samples=40)
plt.plot(X,y,'o')
plt.ylim(-3, 3)
plt.xlabel("Characteristics")
plt.ylabel("Targets")
plt.show()결과값
Cancer
# * cancer 데이터셋 : 위스콘신 유방암 데이터셋. 유방암 종양의 임상 데이터가 기록된 실제 데이터셋.
# 569개의 데이터와 30개의 특성을 가진다. 그중 212개는 악성이고 357개는 양성이다.
import scipy as sp
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import mglearn
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
print("cancer.keys():\n{}".format(cancer.keys()))
print("데이터의 형태: {}".format(cancer.data.shape))
print("클래스별 샘플 개수:\n{}".format(
{n: v for n, v in zip(cancer.target_names, np.bincount(cancer.target))}))
print("특성 이름:\n{}".format(cancer.feature_names))
Boston
import scipy as sp
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import mglearn
from sklearn.datasets import load_boston
boston = load_boston()
print("shape: {}".format(boston.data.shape))
print("Boston.keys():\n{}".format(boston.keys()))
Extended Boston
import scipy as sp
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import mglearn
from sklearn.datasets import load_boston
X, y = mglearn.datasets.load_extended_boston()
print("X.shape: {}".format(X.shape))
plt.show()
반응형